Decoding Style: Efficient Fine-Tuning of LLMs for Image-Guided Outfit Recommendation with Preference
作者: Najmeh Forouzandehmehr, Nima Farrokhsiar, Ramin Giahi, Evren Korpeoglu, Kannan Achan
分类: cs.IR, cs.AI, cs.LG
发布日期: 2024-09-18
备注: CIKM 2024
💡 一句话要点
提出基于LLM微调的图像引导Outfit推荐框架,提升个性化时尚搭配效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 服装推荐 大型语言模型 多模态学习 图像描述 个性化推荐
📋 核心要点
- 现有服装推荐方法难以兼顾时尚兼容性和潮流感知,个性化推荐效果不佳。
- 利用MLLM提取图像风格特征,微调LLM学习时尚搭配,并引入负样本反馈优化推荐。
- 在Polyvore数据集上验证,填空和补全任务均优于基线LLM,提升服装搭配的连贯性。
📝 摘要(中文)
本文提出了一种新颖的框架,利用大型语言模型(LLM)的表达能力来解决个性化服装推荐这一复杂挑战。通过微调和直接反馈集成,缓解了LLM的“黑盒”和静态特性。该框架利用多模态大型语言模型(MLLM)进行图像描述,弥合了物品视觉-文本描述之间的差距,使LLM能够从人工设计的时尚图像中提取风格和颜色特征,从而为个性化推荐奠定基础。在Polyvore数据集上对LLM进行高效微调,优化其推荐时尚服装的能力。采用使用负样本的直接偏好机制来增强LLM的决策过程。这创建了一个自我增强的AI反馈循环,不断根据季节性时尚趋势改进推荐。在Polyvore数据集上的评估表明,该框架在填空和补充项目检索这两项关键任务中都非常有效,突显了其生成时尚、符合潮流的服装建议的能力,并通过直接反馈不断改进。评估结果表明,我们提出的框架明显优于基础LLM,创造了更具凝聚力的服装。
🔬 方法详解
问题定义:论文旨在解决个性化服装推荐问题,现有方法难以有效理解时尚搭配的内在逻辑和捕捉不断变化的潮流趋势,导致推荐结果缺乏时尚性和个性化。此外,LLM在服装推荐中的应用面临“黑盒”问题,难以解释和优化。
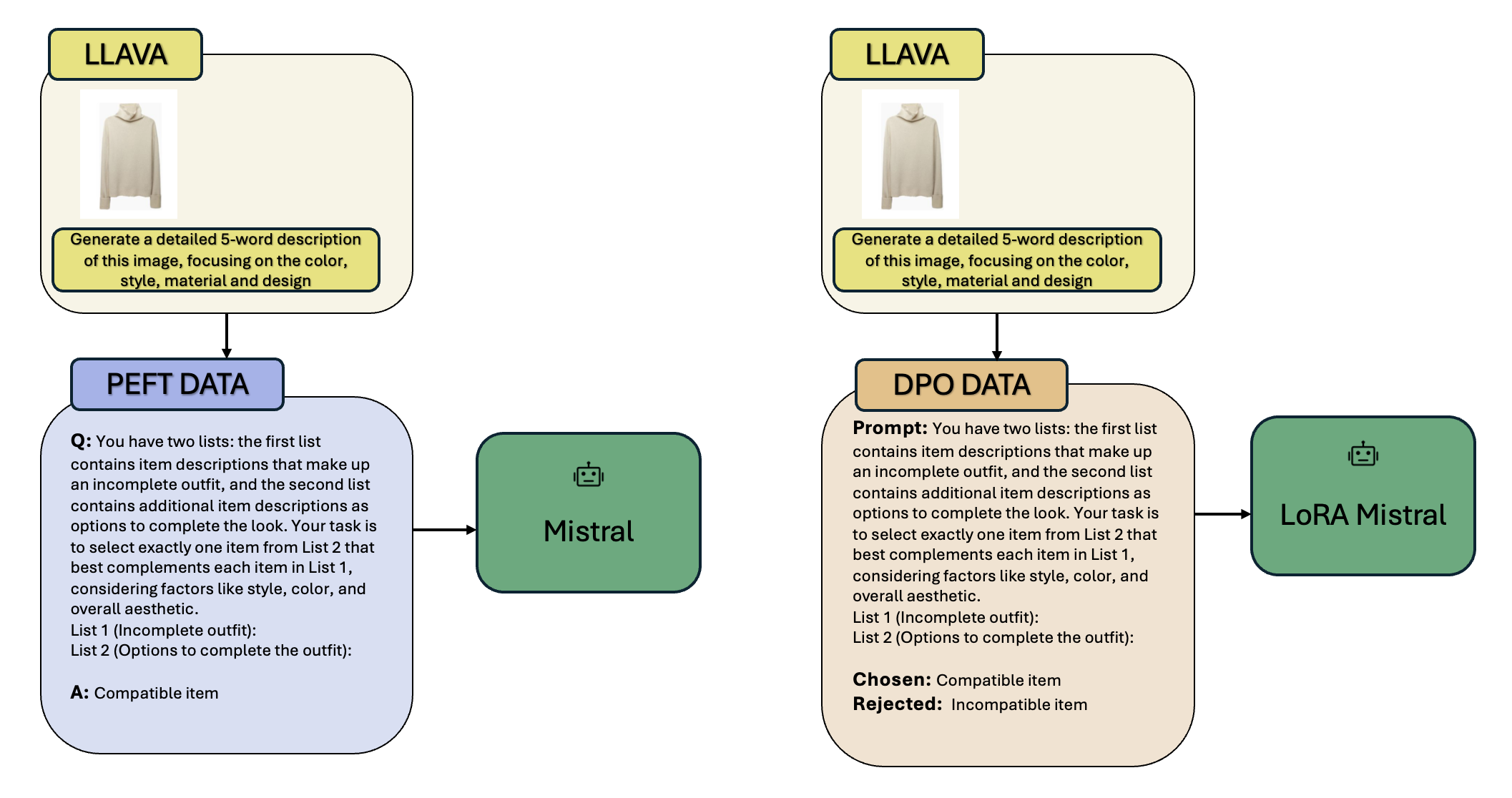
核心思路:核心思路是利用MLLM从时尚图像中提取视觉特征,并将其转化为文本描述,从而弥合视觉和文本之间的鸿沟。然后,通过微调LLM,使其能够理解和生成时尚搭配建议。此外,引入基于负样本的直接偏好机制,让LLM能够学习用户的偏好,并根据反馈不断优化推荐结果。
技术框架:整体框架包含以下几个主要模块:1) 图像描述模块:使用MLLM对服装图像进行描述,提取风格、颜色等特征。2) LLM微调模块:在Polyvore数据集上对LLM进行微调,使其学习时尚搭配的知识。3) 偏好学习模块:通过负样本反馈,让LLM学习用户的偏好。4) 推荐模块:根据用户的历史行为和偏好,生成个性化的服装搭配建议。
关键创新:最重要的创新点在于将MLLM用于服装图像的特征提取,并结合LLM的文本生成能力,实现端到端的服装推荐。此外,引入基于负样本的直接偏好机制,能够有效地学习用户的偏好,并根据反馈不断优化推荐结果。与现有方法相比,该方法能够更好地理解时尚搭配的内在逻辑,并生成更具时尚性和个性化的推荐结果。
关键设计:论文使用开源的Polyvore数据集进行训练和评估。在LLM微调过程中,采用了高效的参数微调方法,以减少计算成本。在偏好学习模块中,采用了对比学习损失函数,以鼓励LLM学习区分正样本和负样本。具体参数设置和网络结构等技术细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
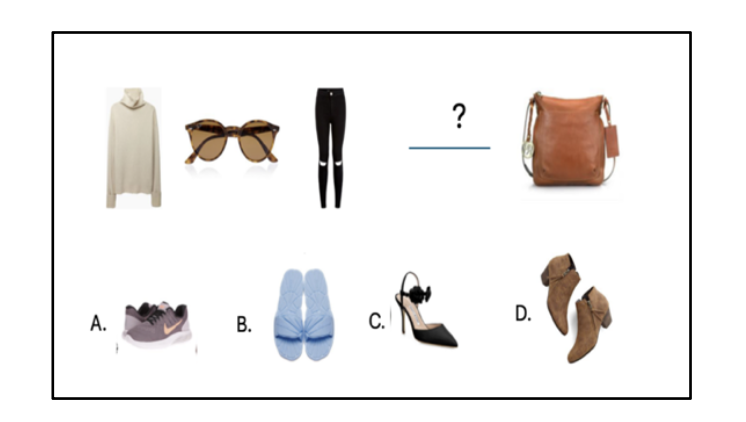
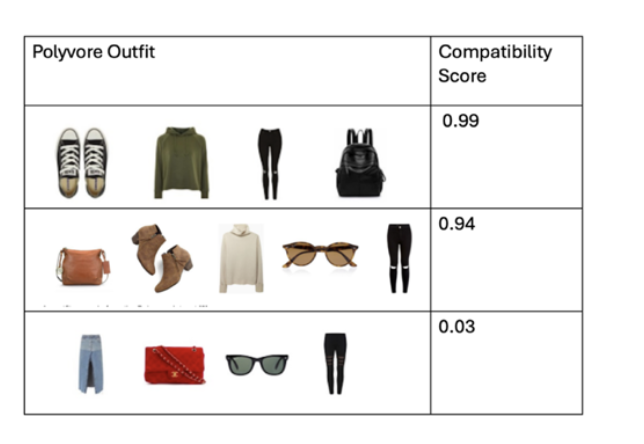
实验结果表明,该框架在填空和补全任务中均优于基线LLM,证明了其生成时尚、符合潮流的服装建议的能力。具体而言,该框架能够生成更具凝聚力的服装搭配,提升了服装搭配的整体协调性。这些结果突显了该框架在增强购物体验方面的潜力。
🎯 应用场景
该研究成果可应用于电商平台的服装推荐系统,帮助用户发现更符合其风格和潮流的服装搭配,提升购物体验。此外,该方法还可以应用于时尚搭配咨询、虚拟试衣等领域,为用户提供个性化的时尚建议。未来,该研究有望推动人工智能在时尚领域的更广泛应用。
📄 摘要(原文)
Personalized outfit recommendation remains a complex challenge, demanding both fashion compatibility understanding and trend awareness. This paper presents a novel framework that harnesses the expressive power of large language models (LLMs) for this task, mitigating their "black box" and static nature through fine-tuning and direct feedback integration. We bridge the item visual-textual gap in items descriptions by employing image captioning with a Multimodal Large Language Model (MLLM). This enables the LLM to extract style and color characteristics from human-curated fashion images, forming the basis for personalized recommendations. The LLM is efficiently fine-tuned on the open-source Polyvore dataset of curated fashion images, optimizing its ability to recommend stylish outfits. A direct preference mechanism using negative examples is employed to enhance the LLM's decision-making process. This creates a self-enhancing AI feedback loop that continuously refines recommendations in line with seasonal fashion trends. Our framework is evaluated on the Polyvore dataset, demonstrating its effectiveness in two key tasks: fill-in-the-blank, and complementary item retrieval. These evaluations underline the framework's ability to generate stylish, trend-aligned outfit suggestions, continuously improving through direct feedback. The evaluation results demonstrated that our proposed framework significantly outperforms the base LLM, creating more cohesive outfits. The improved performance in these tasks underscores the proposed framework's potential to enhance the shopping experience with accurate suggestions, proving its effectiveness over the vanilla LLM based outfit generation.