Moshi: a speech-text foundation model for real-time dialogue
作者: Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave, Neil Zeghidour
分类: eess.AS, cs.AI, cs.CL, cs.LG, cs.SD
发布日期: 2024-09-17 (更新: 2024-10-02)
🔗 代码/项目: GITHUB
💡 一句话要点
Moshi:用于实时对话的语音-文本基础模型,实现全双工语音交互
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音对话 语音生成 端到端学习 实时系统 全双工 语音识别 文本到语音 基础模型
📋 核心要点
- 现有语音对话系统延迟高、信息损失,且无法处理复杂对话场景(如语音重叠)。
- Moshi将语音对话建模为语音到语音生成,并行处理双方语音流,无需显式分割说话人轮次。
- 引入“内心独白”方法,先预测时间对齐的文本token,显著提升生成语音的语言质量,并实现流式语音识别和TTS。
📝 摘要(中文)
本文介绍Moshi,一个语音-文本基础模型和全双工语音对话框架。现有的语音对话系统依赖于独立的组件流水线,包括语音活动检测、语音识别、文本对话和文本到语音。这种框架无法模拟真实的对话体验。首先,其复杂性导致交互之间存在数秒的延迟。其次,文本作为对话的中间模态,情感或非语音声音等影响含义的非语言信息在交互中丢失。最后,它们依赖于说话人轮流分割,这没有考虑到重叠的语音、中断和插话。Moshi通过将语音对话转换为语音到语音的生成来完全解决这些独立的问题。从文本语言模型骨干开始,Moshi将语音生成为神经音频编解码器的残差量化器的token,同时将自己的语音和用户的语音分别建模到并行流中。这允许消除显式的说话人轮流,并对任意的会话动态进行建模。此外,我们将先前工作中分层的语义到声学token生成扩展为首先预测时间对齐的文本token作为音频token的前缀。这种“内心独白”方法不仅显著提高了生成语音的语言质量,而且还说明了它如何提供流式语音识别和文本到语音。我们最终得到的模型是第一个实时的全双工语音大型语言模型,理论延迟为160ms,实际延迟为200ms,可在https://github.com/kyutai-labs/moshi上获得。
🔬 方法详解
问题定义:现有语音对话系统通常采用流水线式的架构,包含语音活动检测、语音识别、文本对话管理和文本到语音合成等多个独立模块。这种架构存在几个主要问题:一是处理延迟较高,难以实现实时交互;二是文本作为中间模态会丢失情感等非语言信息;三是无法有效处理语音重叠、中断等复杂的对话场景。
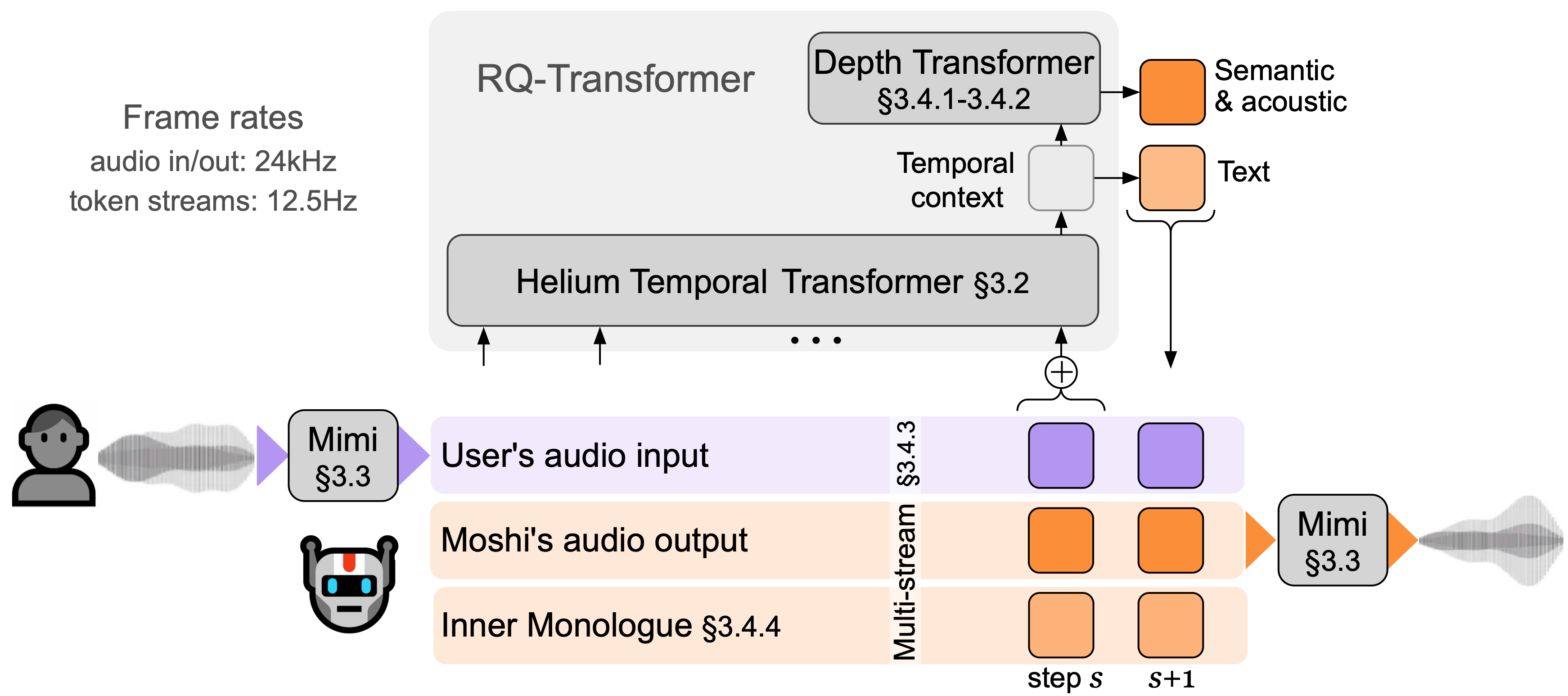
核心思路:Moshi的核心思路是将语音对话视为一个端到端的语音到语音生成任务。通过直接生成语音,避免了中间文本表示带来的信息损失和延迟。同时,Moshi采用并行流的方式建模双方的语音,从而能够自然地处理语音重叠和中断等情况。
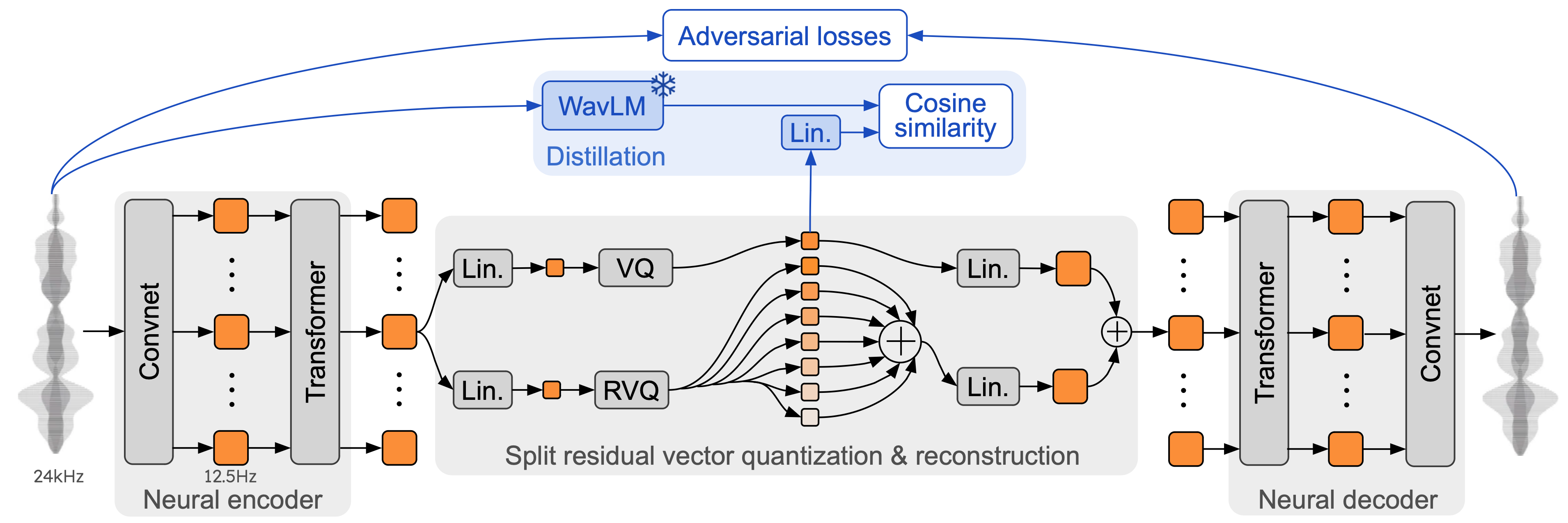
技术框架:Moshi基于一个文本语言模型作为骨干网络。该模型通过神经音频编解码器将语音转换为离散的token序列。Moshi同时建模自身和用户的语音,并将它们作为并行的数据流输入模型。为了提高生成语音的质量,Moshi引入了“内心独白”机制,即在生成音频token之前,先预测时间对齐的文本token。整个框架可以实现实时的全双工语音对话。
关键创新:Moshi的关键创新在于其端到端的语音到语音生成方式,以及并行流的语音建模方法。与传统的流水线式系统相比,Moshi能够显著降低延迟,保留非语言信息,并更好地处理复杂的对话场景。“内心独白”机制也是一个重要的创新,它通过引入文本信息来提高生成语音的语言质量。
关键设计:Moshi使用神经音频编解码器将语音转换为离散的token序列。具体使用的编解码器类型未知。 “内心独白”模块的具体实现方式未知,但其目标是预测与音频token对齐的文本token。模型的训练目标是最小化生成语音和目标语音之间的差异,可能采用交叉熵损失或类似的损失函数。模型的具体参数设置和网络结构未知。
🖼️ 关键图片

📊 实验亮点
Moshi实现了160ms的理论延迟和200ms的实际延迟,是目前最快的全双工语音大型语言模型之一。通过引入“内心独白”方法,Moshi显著提高了生成语音的语言质量。具体提升幅度未知,但论文强调了其重要性。Moshi在处理语音重叠和中断等复杂对话场景方面也表现出色。
🎯 应用场景
Moshi具有广泛的应用前景,例如实时语音助手、在线会议系统、游戏中的语音交互、以及人机协作等领域。其低延迟和全双工特性使其能够提供更自然、流畅的语音交互体验。未来,Moshi有望成为下一代语音交互系统的核心技术。
📄 摘要(原文)
We introduce Moshi, a speech-text foundation model and full-duplex spoken dialogue framework. Current systems for spoken dialogue rely on pipelines of independent components, namely voice activity detection, speech recognition, textual dialogue and text-to-speech. Such frameworks cannot emulate the experience of real conversations. First, their complexity induces a latency of several seconds between interactions. Second, text being the intermediate modality for dialogue, non-linguistic information that modifies meaning -- such as emotion or non-speech sounds -- is lost in the interaction. Finally, they rely on a segmentation into speaker turns, which does not take into account overlapping speech, interruptions and interjections. Moshi solves these independent issues altogether by casting spoken dialogue as speech-to-speech generation. Starting from a text language model backbone, Moshi generates speech as tokens from the residual quantizer of a neural audio codec, while modeling separately its own speech and that of the user into parallel streams. This allows for the removal of explicit speaker turns, and the modeling of arbitrary conversational dynamics. We moreover extend the hierarchical semantic-to-acoustic token generation of previous work to first predict time-aligned text tokens as a prefix to audio tokens. Not only this "Inner Monologue" method significantly improves the linguistic quality of generated speech, but we also illustrate how it can provide streaming speech recognition and text-to-speech. Our resulting model is the first real-time full-duplex spoken large language model, with a theoretical latency of 160ms, 200ms in practice, and is available at https://github.com/kyutai-labs/moshi.