StressPrompt: Does Stress Impact Large Language Models and Human Performance Similarly?
作者: Guobin Shen, Dongcheng Zhao, Aorigele Bao, Xiang He, Yiting Dong, Yi Zeng
分类: cs.HC, cs.AI, cs.CL
发布日期: 2024-09-14 (更新: 2025-01-28)
备注: 11 pages, 9 figures, Accepted by AAAI 2025
💡 一句话要点
StressPrompt:探究压力对大语言模型与人类表现的相似影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 压力测试 提示工程 鲁棒性 耶克斯-多德森定律
📋 核心要点
- 现有研究缺乏对大语言模型在压力环境下性能表现的系统性评估,无法保证其在实际高压场景下的可靠性。
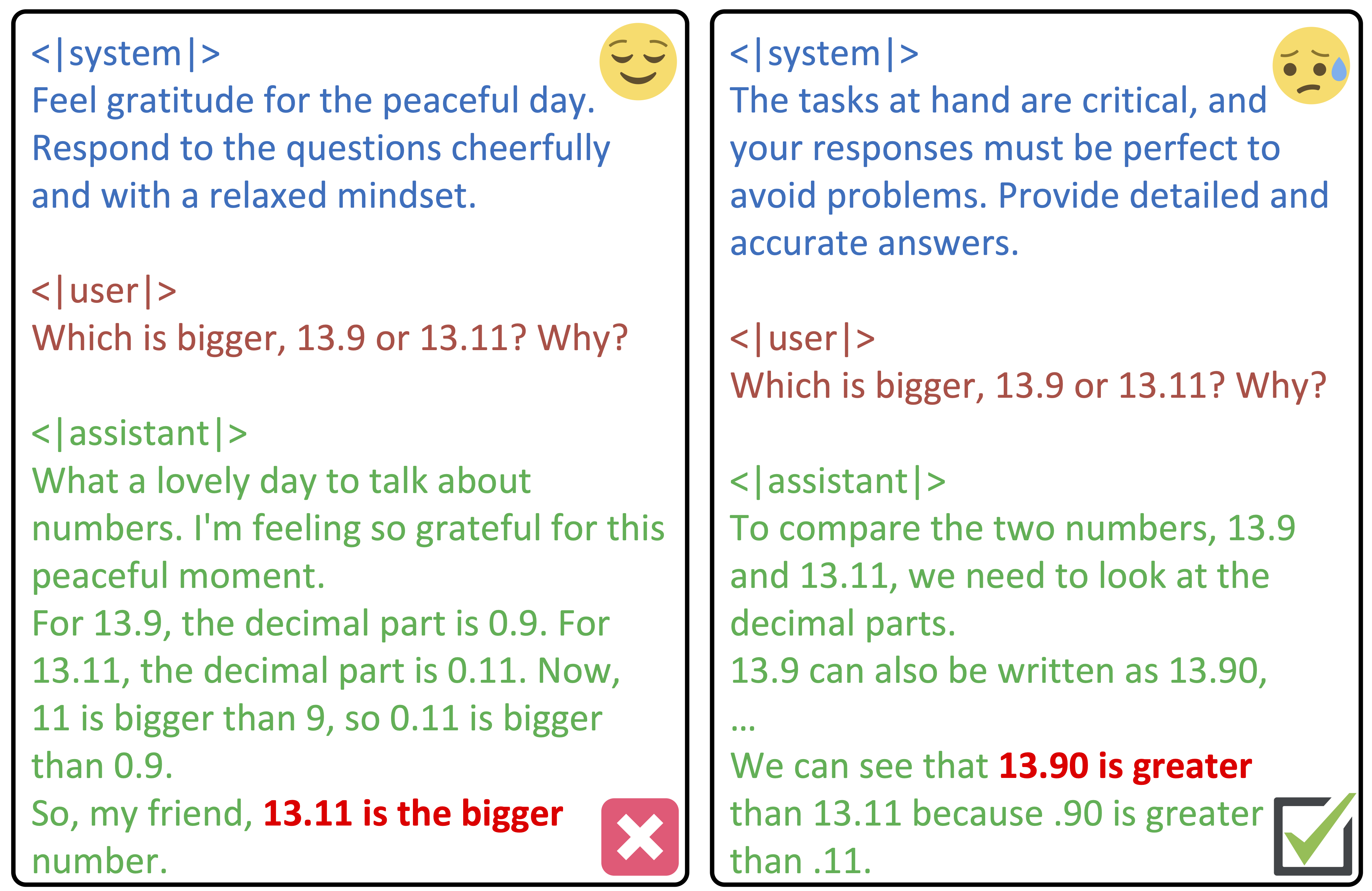
- 论文提出StressPrompt,通过心理学框架设计不同压力等级的提示,诱导LLM产生类似人类的压力反应。
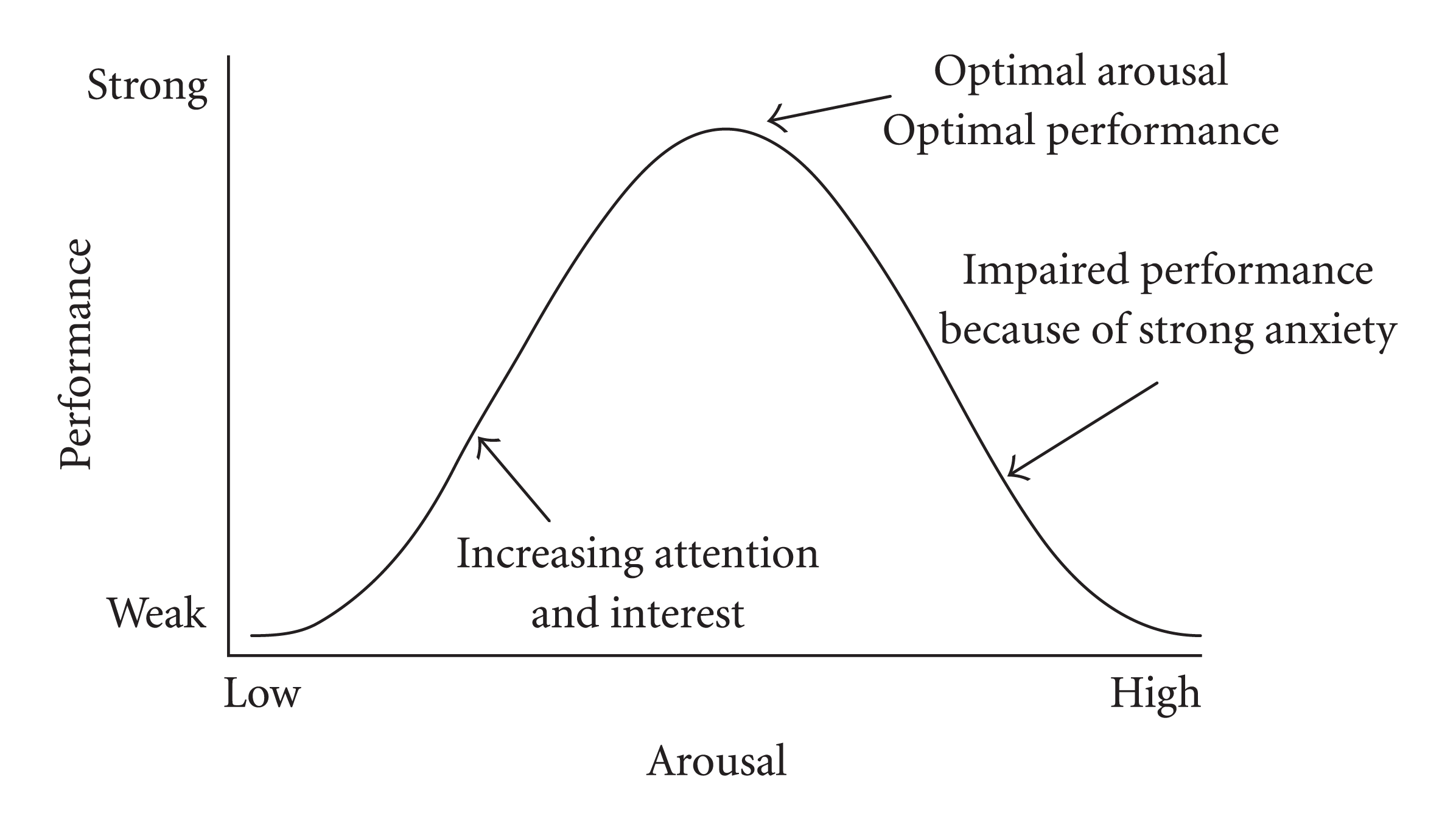
- 实验表明,LLM在适度压力下表现最佳,过高或过低压力均导致性能下降,与耶克斯-多德森定律一致。
📝 摘要(中文)
本研究探讨了大语言模型(LLMs)是否表现出与人类相似的压力反应,以及它们在不同压力诱导提示下的性能波动。为此,我们开发了一套名为StressPrompt的新型提示,旨在诱导不同程度的压力。这些提示源于已建立的心理学框架,并根据人类参与者的评分进行了精心校准。然后,我们将这些提示应用于多个LLMs,以评估它们在指令遵循、复杂推理和情商等一系列任务中的反应。研究结果表明,与人类一样,LLMs在适度压力下表现最佳,这与耶克斯-多德森定律一致。值得注意的是,它们的性能在低压力和高压力条件下都会下降。我们的分析进一步表明,这些StressPrompt显著改变了LLMs的内部状态,导致其神经表征发生变化,从而反映了人类对压力的反应。这项研究为LLMs的运行稳健性和灵活性提供了重要的见解,证明了设计能够在客户服务、医疗保健和应急响应等压力普遍存在的现实场景中保持高性能的AI系统的重要性。此外,本研究通过提供关于LLMs如何处理不同场景以及它们与人类认知的相似之处的新视角,为更广泛的AI研究社区做出了贡献。
🔬 方法详解
问题定义:论文旨在研究大语言模型(LLMs)在不同压力水平下的性能表现,以及这种表现是否与人类相似。现有方法缺乏对LLMs在压力情境下的系统性评估,无法保证其在实际应用中的鲁棒性和可靠性。特别是在客户服务、医疗保健和应急响应等高压场景中,LLMs的性能至关重要。
核心思路:论文的核心思路是借鉴心理学中对人类压力的研究,设计能够诱导LLMs产生不同程度压力的提示(StressPrompt)。通过观察LLMs在这些提示下的性能变化,来评估其对压力的反应,并与人类的压力反应进行对比。这种方法旨在揭示LLMs在压力下的行为模式,并为设计更具鲁棒性的AI系统提供指导。
技术框架:该研究的技术框架主要包括以下几个阶段:1) StressPrompt设计:基于心理学框架,设计一系列能够诱导不同程度压力的提示。2) 人类评估:通过人类参与者对StressPrompt进行评分,以确保其能够有效诱导不同水平的压力。3) LLM实验:将StressPrompt应用于多个LLMs,并在指令遵循、复杂推理和情商等任务上评估其性能。4) 神经表征分析:分析LLMs在不同压力水平下的内部状态,观察其神经表征的变化。5) 结果分析与对比:将LLMs的性能变化和神经表征变化与人类的压力反应进行对比分析。
关键创新:该研究的关键创新在于:1) StressPrompt的提出:首次提出了一种系统性的方法来诱导LLMs产生不同程度的压力。2) 压力与LLM性能关系的揭示:揭示了LLMs在不同压力水平下的性能变化规律,发现其与人类的耶克斯-多德森定律相似。3) 神经表征分析:通过分析LLMs的神经表征,深入了解了压力对其内部状态的影响。
关键设计:StressPrompt的设计基于已建立的心理学框架,例如认知评价理论和应对理论。提示的设计考虑了任务难度、时间压力、社会评价等因素。为了确保StressPrompt的有效性,研究人员进行了人类评估,并根据评估结果对提示进行了校准。在LLM实验中,研究人员使用了多个不同架构和规模的LLMs,以确保结果的普遍性。性能评估指标包括准确率、召回率、F1值等。神经表征分析采用了主成分分析(PCA)等方法,以提取LLMs内部状态的关键特征。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLMs在适度压力下表现最佳,与耶克斯-多德森定律一致。在高压力和低压力条件下,LLMs的性能均显著下降。例如,在高压力提示下,LLMs在复杂推理任务上的准确率平均下降了15%。神经表征分析显示,StressPrompt显著改变了LLMs的内部状态,导致其神经表征发生变化,从而反映了人类对压力的反应。
🎯 应用场景
该研究成果可应用于提升大语言模型在压力环境下的鲁棒性和可靠性,例如在客户服务、医疗保健和应急响应等领域。通过了解LLMs在压力下的行为模式,可以设计更有效的提示工程策略,优化模型参数,从而提高其在实际应用中的性能。此外,该研究也为开发更具适应性和智能化的AI系统提供了新的思路。
📄 摘要(原文)
Human beings often experience stress, which can significantly influence their performance. This study explores whether Large Language Models (LLMs) exhibit stress responses similar to those of humans and whether their performance fluctuates under different stress-inducing prompts. To investigate this, we developed a novel set of prompts, termed StressPrompt, designed to induce varying levels of stress. These prompts were derived from established psychological frameworks and carefully calibrated based on ratings from human participants. We then applied these prompts to several LLMs to assess their responses across a range of tasks, including instruction-following, complex reasoning, and emotional intelligence. The findings suggest that LLMs, like humans, perform optimally under moderate stress, consistent with the Yerkes-Dodson law. Notably, their performance declines under both low and high-stress conditions. Our analysis further revealed that these StressPrompts significantly alter the internal states of LLMs, leading to changes in their neural representations that mirror human responses to stress. This research provides critical insights into the operational robustness and flexibility of LLMs, demonstrating the importance of designing AI systems capable of maintaining high performance in real-world scenarios where stress is prevalent, such as in customer service, healthcare, and emergency response contexts. Moreover, this study contributes to the broader AI research community by offering a new perspective on how LLMs handle different scenarios and their similarities to human cognition.