What Is Wrong with My Model? Identifying Systematic Problems with Semantic Data Slicing
作者: Chenyang Yang, Yining Hong, Grace A. Lewis, Tongshuang Wu, Christian Kästner
分类: cs.SE, cs.AI, cs.CL, cs.LG
发布日期: 2024-09-14
💡 一句话要点
提出SemSlicer,利用语义切片识别机器学习模型中的系统性问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语义切片 机器学习模型调试 错误分析 大型语言模型 数据标注 模型审计 系统性问题
📋 核心要点
- 传统数据切片依赖于预定义特征和程序化函数,难以发现模型在语义层面的系统性错误。
- SemSlicer利用大型语言模型进行数据标注,并根据用户自定义的语义标准生成数据切片。
- 实验证明SemSlicer能以低成本生成准确切片,有效识别模型表现不佳的语义切片,辅助分析系统性问题。
📝 摘要(中文)
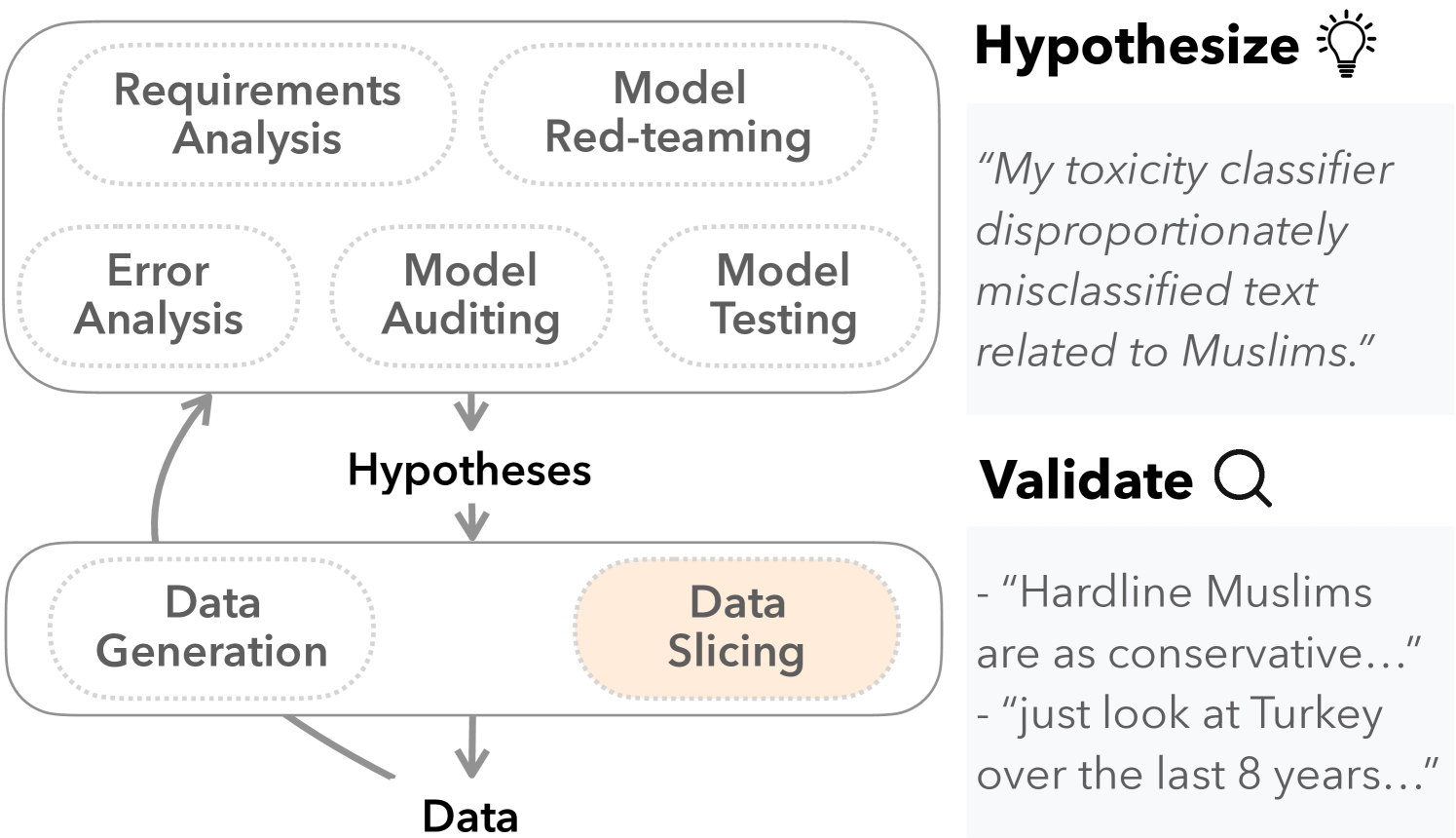
机器学习模型会犯错,但有时难以识别错误背后的系统性问题。从业者进行各种活动,包括错误分析、测试、审计和红队演练,以形成关于模型可能出错(或已经出错)的假设。为了验证这些假设,从业者采用数据切片来识别相关示例。然而,传统的数据切片受到可用特征和程序化切片函数的限制。本文提出了SemSlicer,一个支持语义数据切片的框架,它无需现有特征即可识别语义上连贯的切片。SemSlicer使用大型语言模型来注释数据集,并从任何用户定义的切片标准生成切片。实验表明,SemSlicer以低成本生成准确的切片,允许在不同的设计维度之间进行灵活的权衡,可靠地识别表现不佳的数据切片,并帮助从业者识别反映系统性问题的有用数据切片。
🔬 方法详解
问题定义:论文旨在解决机器学习模型错误分析中,传统数据切片方法依赖预定义特征和程序化函数,难以发现模型在语义层面存在的系统性问题。现有方法的痛点在于缺乏灵活性和语义理解能力,无法根据用户自定义的语义标准进行切片,从而难以定位模型在特定语义场景下的缺陷。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大语义理解和生成能力,对数据集进行语义标注,并根据用户定义的语义标准生成数据切片。通过这种方式,可以摆脱对预定义特征的依赖,实现更灵活、更具语义针对性的数据切片,从而更好地识别模型在特定语义场景下的系统性问题。
技术框架:SemSlicer框架主要包含以下几个阶段:1. 数据标注:使用LLM对数据集中的每个样本进行语义标注,生成包含丰富语义信息的元数据。2. 切片生成:根据用户定义的语义标准(例如,“包含特定对象的图像”),利用LLM生成相应的切片查询。3. 切片评估:评估生成的切片在模型上的表现,识别表现不佳的切片。4. 问题诊断:分析表现不佳的切片,定位模型存在的系统性问题。
关键创新:SemSlicer的关键创新在于将大型语言模型引入到数据切片过程中,实现了语义数据切片。与传统数据切片方法相比,SemSlicer无需预定义特征,可以根据用户自定义的语义标准进行切片,从而更灵活、更有效地识别模型在特定语义场景下的系统性问题。
关键设计:SemSlicer的关键设计包括:1. LLM的选择:选择合适的LLM,以保证标注的准确性和效率。2. 切片查询的生成:设计有效的切片查询生成方法,以保证生成的切片能够准确反映用户定义的语义标准。3. 切片评估指标的选择:选择合适的切片评估指标,以准确评估切片在模型上的表现。
🖼️ 关键图片


📊 实验亮点
论文通过实验验证了SemSlicer的有效性。实验结果表明,SemSlicer能够以低成本生成准确的语义切片,并能有效识别模型表现不佳的数据切片。例如,在图像分类任务中,SemSlicer能够识别出模型在特定光照条件或特定对象遮挡情况下表现较差的切片,从而帮助开发者定位模型存在的系统性问题。
🎯 应用场景
SemSlicer可应用于各种机器学习模型的错误分析和调试,尤其适用于图像识别、自然语言处理等领域。它可以帮助开发者快速定位模型在特定场景下的缺陷,提高模型的鲁棒性和可靠性。此外,SemSlicer还可以用于模型审计和红队演练,评估模型在对抗性攻击下的表现。
📄 摘要(原文)
Machine learning models make mistakes, yet sometimes it is difficult to identify the systematic problems behind the mistakes. Practitioners engage in various activities, including error analysis, testing, auditing, and red-teaming, to form hypotheses of what can go (or has gone) wrong with their models. To validate these hypotheses, practitioners employ data slicing to identify relevant examples. However, traditional data slicing is limited by available features and programmatic slicing functions. In this work, we propose SemSlicer, a framework that supports semantic data slicing, which identifies a semantically coherent slice, without the need for existing features. SemSlicer uses Large Language Models to annotate datasets and generate slices from any user-defined slicing criteria. We show that SemSlicer generates accurate slices with low cost, allows flexible trade-offs between different design dimensions, reliably identifies under-performing data slices, and helps practitioners identify useful data slices that reflect systematic problems.