B4: Towards Optimal Assessment of Plausible Code Solutions with Plausible Tests
作者: Mouxiang Chen, Zhongxin Liu, He Tao, Yusu Hong, David Lo, Xin Xia, Jianling Sun
分类: cs.SE, cs.AI, cs.CL
发布日期: 2024-09-13
备注: accepted by ASE' 24 (full paper)
🔗 代码/项目: GITHUB
💡 一句话要点
B4:利用可信测试,实现对代码生成中多个候选解的最优评估与选择
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 代码评估 贝叶斯推断 整数规划 大型语言模型
📋 核心要点
- 现有代码生成方案评估依赖可靠测试用例,但人工编写成本高,自动生成测试用例又面临可靠性问题。
- 论文提出基于贝叶斯框架的最优选择策略,通过后验概率评估代码方案,并将问题转化为整数规划。
- 实验表明,该策略显著优于现有启发式方法,在复杂场景下性能提升高达50%,验证了其有效性。
📝 摘要(中文)
在代码生成中,从多个生成的代码解决方案中选择最佳方案至关重要,这可以通过使用一些可靠的验证器(例如,开发人员编写的测试用例)来辅助实现。由于可靠的测试用例并非总是可用,并且在实践中构建成本可能很高,因此研究人员提出自动生成测试用例来评估代码解决方案。然而,当代码解决方案和测试用例都看似合理但不可靠时,选择最佳解决方案就变得具有挑战性。尽管已经提出了一些启发式策略来解决这个问题,但它们缺乏强大的理论保证,并且是否存在最佳选择策略仍然是一个悬而未决的问题。本文做出了两方面的贡献。首先,我们表明,在贝叶斯框架内,最佳选择策略可以基于解决方案和测试之间观察到的通过状态的后验概率来定义。然后,将识别最佳解决方案的问题转化为整数规划问题。其次,我们提出了一种有效的方法来近似这种最优(但不可计算)策略,其中近似误差受先验知识正确性的限制。然后,我们结合有效的先验知识来定制代码生成任务。理论和实证研究都证实,现有的启发式方法在利用可信测试用例选择最佳解决方案方面存在局限性。我们提出的近似最优策略 B4 在选择由大型语言模型 (LLM) 生成的代码解决方案(使用 LLM 生成的测试)方面,显著优于现有的启发式方法,在最具挑战性的场景中,相对于最强的启发式方法,相对性能提升高达 50%,相对于随机选择,性能提升高达 246%。我们的代码已公开发布在 https://github.com/ZJU-CTAG/B4。
🔬 方法详解
问题定义:论文旨在解决代码生成任务中,如何从多个由大型语言模型生成的候选代码解决方案中选择最优解的问题。现有方法,如启发式策略,在测试用例不可靠的情况下,缺乏理论保证,无法有效区分不同方案的优劣。痛点在于,当测试用例本身也由LLM生成时,其可靠性进一步降低,导致传统评估方法失效。
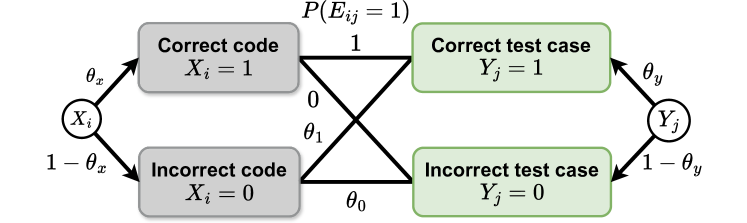
核心思路:论文的核心思路是将代码选择问题置于贝叶斯框架下,利用后验概率来评估每个候选解的优劣。具体而言,通过计算在给定观察到的代码和测试用例执行结果(即通过/失败状态)的情况下,每个候选解为最优解的概率。这种方法考虑了代码和测试用例的不确定性,并试图找到最大化后验概率的解。
技术框架:整体框架包含以下几个主要步骤: 1. 代码生成:使用大型语言模型生成多个候选代码解决方案。 2. 测试用例生成:使用大型语言模型为每个代码解决方案生成测试用例。 3. 执行与观察:执行每个代码解决方案在每个测试用例上的结果,记录通过/失败状态。 4. 后验概率计算:基于贝叶斯公式,计算每个代码解决方案为最优解的后验概率。 5. 最优解选择:将最优解选择问题转化为整数规划问题,求解最大化后验概率的解。 6. 近似优化:由于直接计算后验概率计算复杂度高,论文提出一种近似方法,并在近似过程中引入先验知识。
关键创新:论文的最重要的技术创新点在于,将代码选择问题形式化为一个贝叶斯推断问题,并提出了一种基于后验概率的最优选择策略。与现有启发式方法相比,该方法具有更强的理论基础,能够更好地处理测试用例不可靠的情况。此外,论文还提出了一种有效的近似方法,使得该策略可以在实际应用中得以实现。
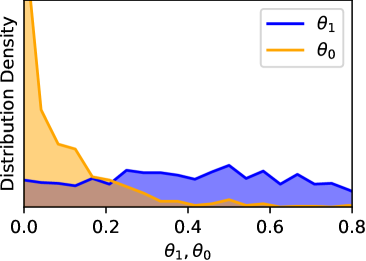
关键设计:论文的关键设计包括: 1. 后验概率计算公式:基于贝叶斯公式,定义了代码解决方案为最优解的后验概率计算公式,该公式考虑了代码和测试用例的先验概率以及观察到的执行结果。 2. 整数规划模型:将最优解选择问题转化为整数规划问题,目标是最大化后验概率,约束条件包括只能选择一个最优解。 3. 近似方法:为了降低计算复杂度,论文提出了一种近似方法,该方法基于先验知识对后验概率进行估计,并保证近似误差受先验知识正确性的限制。 4. 先验知识的引入:论文探讨了如何引入有效的先验知识来提高选择的准确性,例如,可以利用代码的复杂度、测试用例的覆盖率等信息作为先验知识。
🖼️ 关键图片

📊 实验亮点
实验结果表明,提出的B4策略在选择LLM生成的代码解决方案时,显著优于现有的启发式方法。在最具挑战性的场景中,B4相对于最强的启发式方法,相对性能提升高达50%,相对于随机选择,性能提升高达246%。这表明B4在处理不可靠测试用例时具有显著优势。
🎯 应用场景
该研究成果可应用于自动化代码生成、程序修复、代码克隆检测等领域。通过更准确地评估和选择代码方案,可以提高软件开发的效率和质量。未来,该方法可以扩展到更复杂的代码生成任务,并与其他代码分析技术相结合,实现更智能化的软件开发。
📄 摘要(原文)
Selecting the best code solution from multiple generated ones is an essential task in code generation, which can be achieved by using some reliable validators (e.g., developer-written test cases) for assistance. Since reliable test cases are not always available and can be expensive to build in practice, researchers propose to automatically generate test cases to assess code solutions. However, when both code solutions and test cases are plausible and not reliable, selecting the best solution becomes challenging. Although some heuristic strategies have been proposed to tackle this problem, they lack a strong theoretical guarantee and it is still an open question whether an optimal selection strategy exists. Our work contributes in two ways. First, we show that within a Bayesian framework, the optimal selection strategy can be defined based on the posterior probability of the observed passing states between solutions and tests. The problem of identifying the best solution is then framed as an integer programming problem. Second, we propose an efficient approach for approximating this optimal (yet uncomputable) strategy, where the approximation error is bounded by the correctness of prior knowledge. We then incorporate effective prior knowledge to tailor code generation tasks. Both theoretical and empirical studies confirm that existing heuristics are limited in selecting the best solutions with plausible test cases. Our proposed approximated optimal strategy B4 significantly surpasses existing heuristics in selecting code solutions generated by large language models (LLMs) with LLM-generated tests, achieving a relative performance improvement by up to 50% over the strongest heuristic and 246% over the random selection in the most challenging scenarios. Our code is publicly available at https://github.com/ZJU-CTAG/B4.