ATFLRec: A Multimodal Recommender System with Audio-Text Fusion and Low-Rank Adaptation via Instruction-Tuned Large Language Model
作者: Zezheng Qin
分类: cs.IR, cs.AI
发布日期: 2024-09-13
💡 一句话要点
ATFLRec:利用指令调优LLM和低秩适应的多模态推荐系统
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态推荐系统 大型语言模型 低秩适应 音频文本融合 指令调优
📋 核心要点
- 传统推荐系统在处理冷启动问题和融合多模态信息方面存在局限性,难以充分利用音频和文本数据。
- ATFLRec框架利用LoRA技术,将音频和文本模态融入LLM,旨在提升推荐性能并降低计算成本。
- 实验结果表明,ATFLRec在AUC指标上优于传统和基于图神经网络的基线模型,验证了该方法的有效性。
📝 摘要(中文)
本研究探讨了将多模态数据(文本和音频)集成到大型语言模型(LLM)中,以提高推荐性能。传统文本和音频推荐器面临冷启动等问题,而LLM的最新进展虽然前景广阔,但计算成本高昂。为了解决这些问题,引入了低秩适应(LoRA),它在不影响性能的前提下提高了效率。论文提出了ATFLRec框架,将音频和文本模态集成到多模态推荐系统中,利用各种LoRA配置和模态融合技术。结果表明,ATFLRec优于包括传统方法和基于图神经网络的方法在内的基线模型,实现了更高的AUC分数。此外,使用不同的LoRA模块对音频和文本数据进行单独微调可获得最佳性能,不同的池化方法和Mel滤波器组数量会显著影响性能。这项研究为优化多模态推荐系统和推进LLM中不同数据模态的集成提供了宝贵的见解。
🔬 方法详解
问题定义:论文旨在解决传统推荐系统在融合多模态信息(特别是音频和文本)方面的不足,以及大型语言模型(LLM)应用于推荐系统时计算成本过高的问题。现有方法在处理冷启动问题和有效利用音频信息方面存在痛点。
核心思路:论文的核心思路是利用低秩适应(LoRA)技术,将音频和文本模态有效地融入到指令调优的大型语言模型中,从而在提升推荐性能的同时,降低计算成本。通过对不同模态的数据进行独立微调,并采用合适的融合策略,充分利用多模态信息。
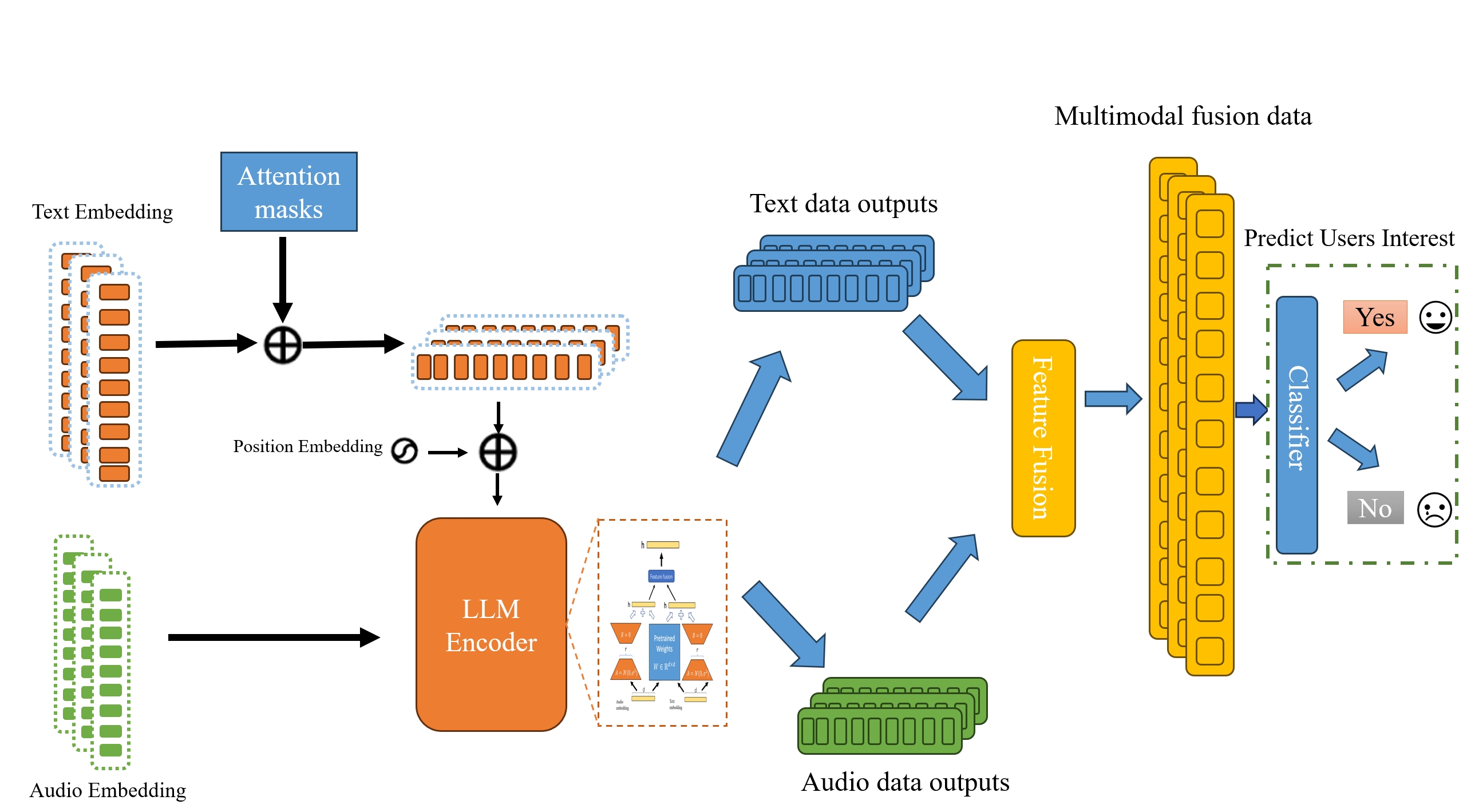
技术框架:ATFLRec框架主要包含以下几个模块:1) 音频特征提取模块,用于提取音频的Mel滤波器组特征;2) 文本特征提取模块,用于提取文本的语义特征;3) 基于LoRA的微调模块,分别对音频和文本数据进行独立微调;4) 多模态融合模块,将音频和文本特征进行融合;5) 推荐预测模块,基于融合后的特征进行推荐预测。整体流程是先分别提取音频和文本特征,然后使用LoRA进行微调,再进行模态融合,最后进行推荐。
关键创新:论文的关键创新在于:1) 提出了ATFLRec框架,将音频和文本模态有效地融入到LLM中;2) 采用LoRA技术,降低了LLM的微调成本;3) 通过对不同模态的数据进行独立微调,并采用合适的融合策略,提升了推荐性能。与现有方法的本质区别在于,ATFLRec能够更有效地利用多模态信息,并在计算效率上具有优势。
关键设计:论文的关键设计包括:1) 使用Mel滤波器组作为音频特征;2) 采用不同的池化方法进行特征聚合;3) 使用不同的LoRA配置(如LoRA模块的数量和秩)进行微调;4) 设计了多种模态融合策略,如拼接和加权融合;5) 损失函数采用交叉熵损失函数。
🖼️ 关键图片


📊 实验亮点
实验结果表明,ATFLRec在AUC指标上优于包括传统方法和基于图神经网络的方法在内的基线模型。通过对音频和文本数据进行独立微调,并采用合适的池化方法和Mel滤波器组数量,可以进一步提升性能。具体而言,ATFLRec在某些数据集上实现了超过5%的AUC提升。
🎯 应用场景
该研究成果可应用于电商、音乐、视频等领域的推荐系统,提升用户体验和平台收益。通过融合音频和文本信息,可以更准确地理解用户偏好,从而提供更个性化的推荐服务。未来,该方法有望扩展到更多模态的数据融合,例如图像和视频,进一步提升推荐系统的性能。
📄 摘要(原文)
Recommender Systems (RS) play a pivotal role in boosting user satisfaction by providing personalized product suggestions in domains such as e-commerce and entertainment. This study examines the integration of multimodal data text and audio into large language models (LLMs) with the aim of enhancing recommendation performance. Traditional text and audio recommenders encounter limitations such as the cold-start problem, and recent advancements in LLMs, while promising, are computationally expensive. To address these issues, Low-Rank Adaptation (LoRA) is introduced, which enhances efficiency without compromising performance. The ATFLRec framework is proposed to integrate audio and text modalities into a multimodal recommendation system, utilizing various LoRA configurations and modality fusion techniques. Results indicate that ATFLRec outperforms baseline models, including traditional and graph neural network-based approaches, achieving higher AUC scores. Furthermore, separate fine-tuning of audio and text data with distinct LoRA modules yields optimal performance, with different pooling methods and Mel filter bank numbers significantly impacting performance. This research offers valuable insights into optimizing multimodal recommender systems and advancing the integration of diverse data modalities in LLMs.