Autonomous Vehicle Controllers From End-to-End Differentiable Simulation
作者: Asen Nachkov, Danda Pani Paudel, Luc Van Gool
分类: cs.AI, cs.RO
发布日期: 2024-09-12 (更新: 2025-09-29)
备注: Polished and accepted at IROS 2025
期刊: 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
💡 一句话要点
提出基于可微仿真和解析策略梯度的自动驾驶车辆控制器训练方法
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 自动驾驶 可微仿真 解析策略梯度 行为克隆 强化学习
📋 核心要点
- 现有自动驾驶控制器学习方法依赖行为克隆,泛化能力弱,且仿真器被视为黑盒,导致训练效率低。
- 论文提出一种基于可微仿真和解析策略梯度(APG)的端到端训练框架,利用环境动力学梯度作为先验。
- 实验表明,该方法在性能、鲁棒性和人机交互方面均优于行为克隆,且仅需专家轨迹而非动作。
📝 摘要(中文)
目前自动驾驶车辆(AVs)控制器的学习方法主要集中在行为克隆上。由于仅在精确的历史数据上训练,导致智能体在新场景中的泛化能力较差。仿真器提供了超越离线数据集的机会,但它们仍然被视为复杂的黑盒,仅用于更新全局仿真状态。因此,这些强化学习算法速度慢、样本效率低且缺乏先验知识。本文利用可微仿真器,设计了一种解析策略梯度(APG)方法,用于在大型Waymo开放运动数据集上训练AV控制器。我们提出的框架将可微仿真器引入端到端训练循环中,其中环境动力学的梯度作为有用的先验,帮助智能体学习更可靠的策略。我们将此设置与循环架构相结合,可以有效地在长模拟轨迹上传播时间信息。这种APG方法使我们能够学习鲁棒、准确和快速的策略,同时只需要广泛可用的专家轨迹,而不是稀缺的专家动作。我们与行为克隆进行比较,发现在性能和对动力学噪声的鲁棒性方面有显著改进,并且总体上更直观,更像人类的操作。
🔬 方法详解
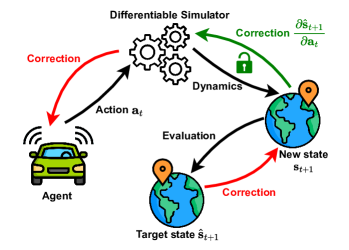
问题定义:现有自动驾驶车辆控制器学习方法,如行为克隆,依赖于离线数据集,在新场景下泛化能力差。强化学习方法虽然可以利用仿真器,但通常将仿真器视为黑盒,导致样本效率低,训练速度慢,且缺乏对环境动力学的先验知识。因此,如何高效地利用仿真器,学习具有良好泛化能力的自动驾驶控制器是一个关键问题。
核心思路:论文的核心思路是利用可微仿真器,将环境动力学的梯度信息融入到策略学习过程中。通过构建端到端的训练框架,使得策略可以直接从仿真环境中学习,并利用环境动力学的梯度作为先验知识,指导策略的优化方向。这种方法可以提高样本效率,加快训练速度,并增强策略的鲁棒性。
技术框架:该框架包含三个主要组成部分:可微仿真器、策略网络和解析策略梯度(APG)优化器。首先,策略网络根据当前状态输出控制指令。然后,可微仿真器根据控制指令更新环境状态。接着,计算环境动力学的梯度,并将其传递给APG优化器。最后,APG优化器利用梯度信息更新策略网络的参数。整个过程在一个端到端的训练循环中进行,使得策略可以直接从仿真环境中学习,并利用环境动力学的梯度作为先验知识。
关键创新:最重要的技术创新点在于利用可微仿真器,将环境动力学的梯度信息融入到策略学习过程中。与传统的强化学习方法不同,该方法不需要通过试错来探索环境,而是可以直接利用环境动力学的梯度信息来指导策略的优化方向。这种方法可以显著提高样本效率,加快训练速度,并增强策略的鲁棒性。此外,使用专家轨迹而非动作也降低了数据获取的难度。
关键设计:论文使用循环神经网络(RNN)作为策略网络,以有效地处理时间序列数据。损失函数包括行为克隆损失和正则化项,以鼓励策略学习模仿专家轨迹,并避免过拟合。APG优化器利用环境动力学的梯度信息来更新策略网络的参数。具体来说,APG优化器计算策略网络的梯度,并将其与环境动力学的梯度相结合,以获得更准确的策略梯度估计。此外,论文还设计了一种噪声注入机制,以增强策略的鲁棒性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在Waymo开放运动数据集上取得了显著的性能提升。与行为克隆相比,该方法在轨迹预测精度、碰撞避免和驾驶舒适性方面均有明显改善。此外,该方法对环境动力学噪声具有更强的鲁棒性,能够在复杂的交通场景中稳定运行。更重要的是,该方法仅需要专家轨迹,而非专家动作,降低了数据获取的难度。
🎯 应用场景
该研究成果可应用于自动驾驶车辆的控制器设计,提高自动驾驶系统的安全性、可靠性和智能化水平。通过利用可微仿真器和解析策略梯度方法,可以更高效地训练出鲁棒的自动驾驶策略,从而降低开发成本,加速自动驾驶技术的落地。此外,该方法还可以推广到其他机器人控制领域,例如无人机、机器人手臂等。
📄 摘要(原文)
Current methods to learn controllers for autonomous vehicles (AVs) focus on behavioural cloning. Being trained only on exact historic data, the resulting agents often generalize poorly to novel scenarios. Simulators provide the opportunity to go beyond offline datasets, but they are still treated as complicated black boxes, only used to update the global simulation state. As a result, these RL algorithms are slow, sample-inefficient, and prior-agnostic. In this work, we leverage a differentiable simulator and design an analytic policy gradients (APG) approach to training AV controllers on the large-scale Waymo Open Motion Dataset. Our proposed framework brings the differentiable simulator into an end-to-end training loop, where gradients of the environment dynamics serve as a useful prior to help the agent learn a more grounded policy. We combine this setup with a recurrent architecture that can efficiently propagate temporal information across long simulated trajectories. This APG method allows us to learn robust, accurate, and fast policies, while only requiring widely-available expert trajectories, instead of scarce expert actions. We compare to behavioural cloning and find significant improvements in performance and robustness to noise in the dynamics, as well as overall more intuitive human-like handling.