A Spatiotemporal Stealthy Backdoor Attack against Cooperative Multi-Agent Deep Reinforcement Learning
作者: Yinbo Yu, Saihao Yan, Jiajia Liu
分类: cs.AI, cs.CR
发布日期: 2024-09-12
备注: 6 pages, IEEE Globecom 2024
💡 一句话要点
提出时空隐蔽后门攻击,提升合作多智能体深度强化学习的安全性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 多智能体强化学习 后门攻击 对抗攻击 时空行为模式 奖励函数修改
📋 核心要点
- 现有c-MADRL后门攻击存在视觉触发器固定、依赖额外网络、需攻击所有智能体等问题,隐蔽性和实用性不足。
- 提出一种新型后门攻击,仅需在单个智能体中嵌入后门,利用对抗性时空行为模式作为触发器,并修改奖励函数。
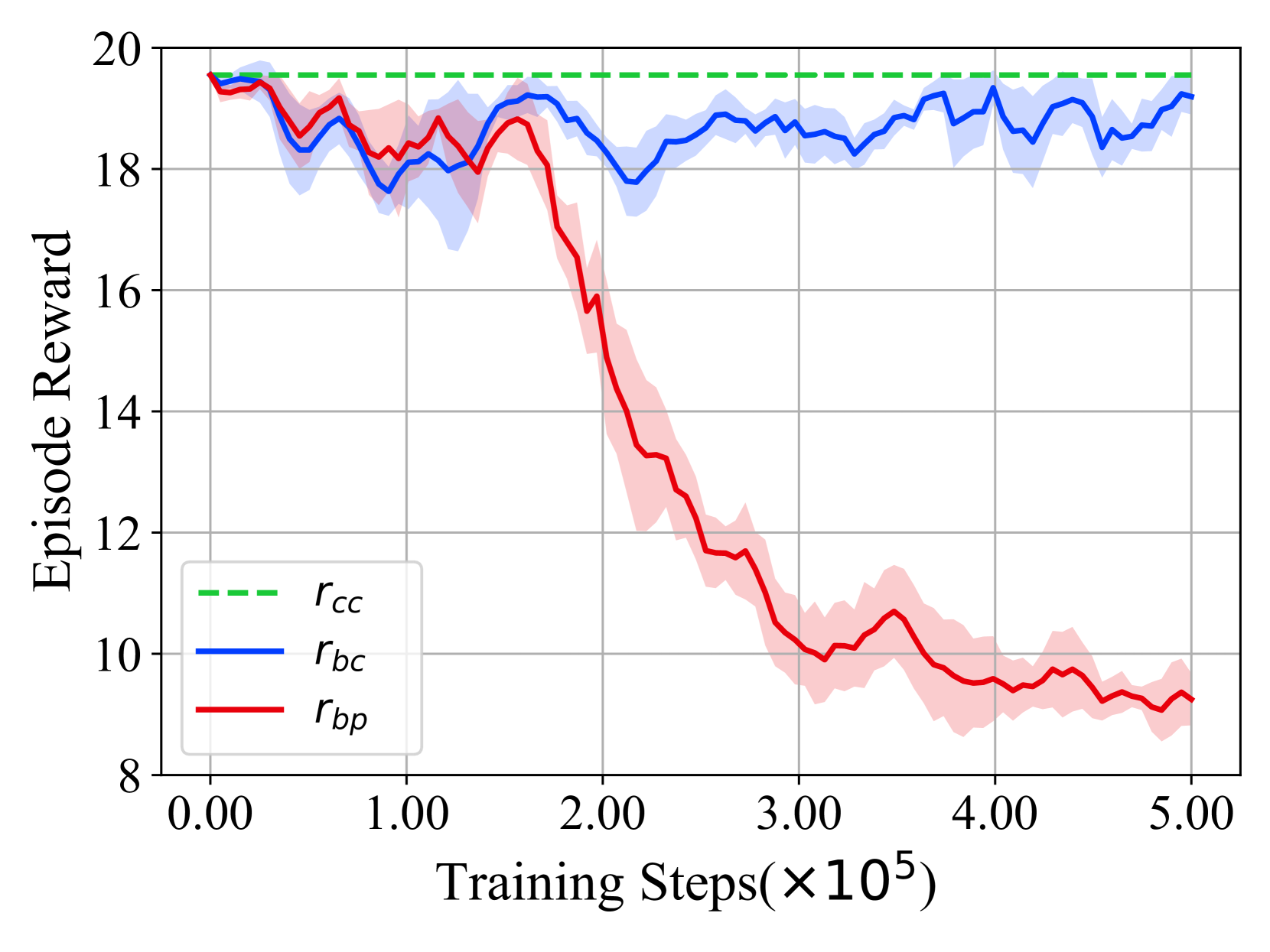
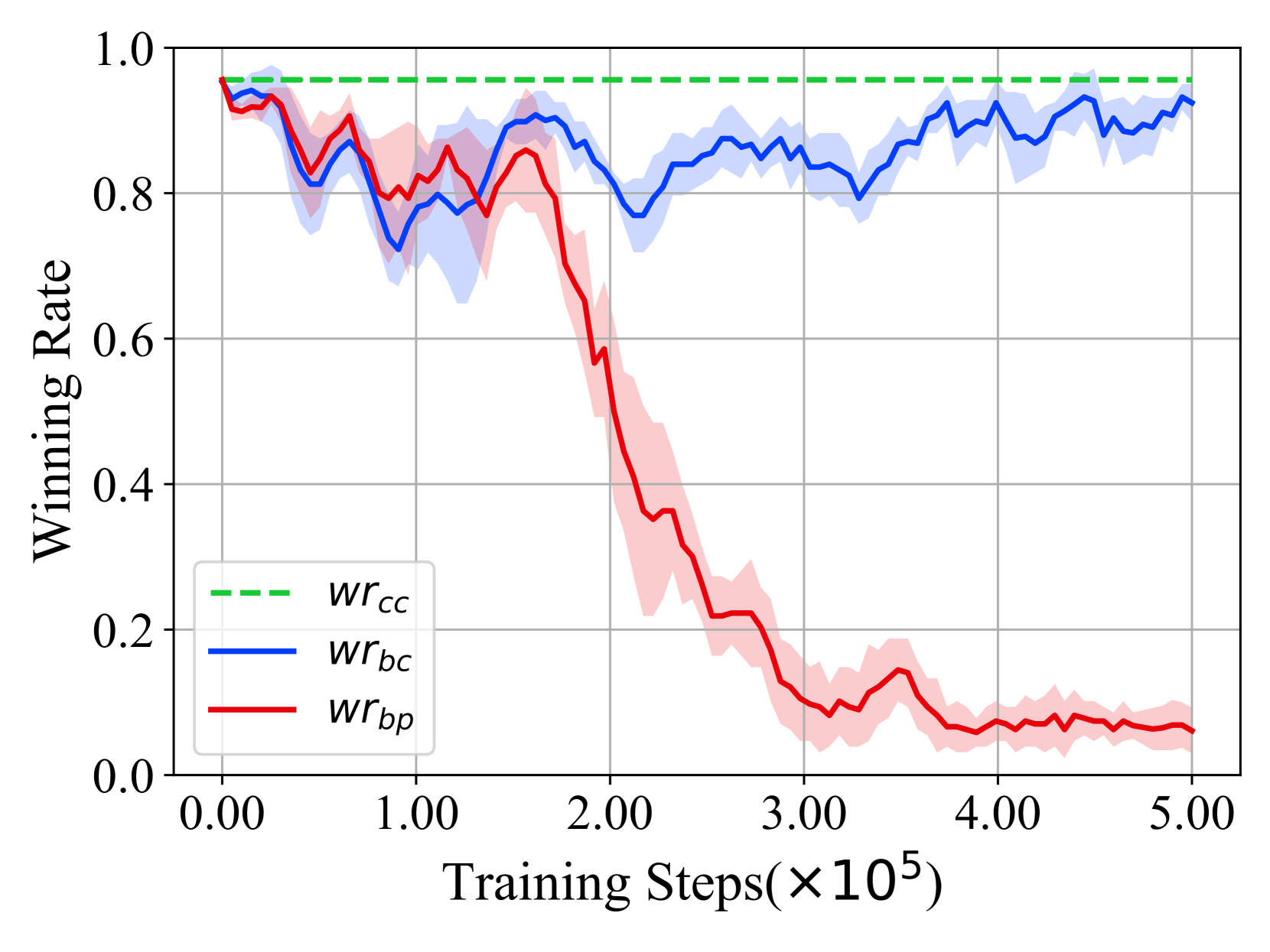
- 实验表明,该攻击在SMAC环境中对VDN和QMIX算法有效,攻击成功率高达91.6%,且对正常性能影响较小。
📝 摘要(中文)
本文提出了一种针对合作多智能体深度强化学习(c-MADRL)的新型后门攻击方法。现有后门攻击存在隐蔽性不足、依赖额外网络或需攻击所有智能体等问题。该方法仅需在单个智能体中嵌入后门,即可攻击整个多智能体团队。通过引入对抗性的时空行为模式作为后门触发器,而非手动注入的固定视觉模式或瞬时状态,并控制攻击持续时间,保证了后门注入的隐蔽性和实用性。此外,通过奖励反转和单边指导,修改受攻击智能体的原始奖励函数,确保其对整个团队产生不利影响。在SMAC环境中,对VDN和QMIX两种经典c-MADRL算法进行了评估。实验结果表明,该后门攻击能够达到较高的攻击成功率(91.6%),同时保持较低的清洁性能方差率(3.7%)。
🔬 方法详解
问题定义:现有的c-MADRL后门攻击方法通常依赖于固定的视觉触发器,容易被检测;或者需要额外的网络进行训练或激活,增加了复杂性;再或者需要对所有智能体进行后门植入,成本较高。这些方法在隐蔽性、实用性和效率方面存在不足,难以在实际应用中有效威胁c-MADRL系统。
核心思路:本文的核心思路是通过引入对抗性的时空行为模式作为后门触发器,而非静态的视觉模式。这种动态的触发方式更难以被检测,提高了隐蔽性。同时,通过修改受攻击智能体的奖励函数,使其在特定时空行为模式下对整个团队产生负面影响,从而实现攻击目标。只攻击单个智能体,降低了攻击成本。
技术框架:该后门攻击框架主要包含两个阶段:后门植入阶段和攻击执行阶段。在后门植入阶段,首先选择一个智能体作为攻击目标,然后设计对抗性的时空行为模式作为触发器。接着,通过奖励反转和单边指导,修改该智能体的奖励函数,使其在触发器激活时产生不利于团队的行为。在攻击执行阶段,当受攻击智能体观察到触发器时,就会执行被篡改的行为,从而影响整个团队的性能。
关键创新:该方法最重要的创新点在于使用对抗性的时空行为模式作为后门触发器。与传统的固定视觉模式相比,这种动态的触发方式更难以被检测,提高了攻击的隐蔽性。此外,通过修改奖励函数而非直接控制智能体的行为,使得攻击更加自然,降低了被发现的风险。
关键设计:在时空行为模式的设计上,需要仔细选择能够有效触发后门并对团队产生负面影响的行为序列。奖励函数的修改采用奖励反转和单边指导相结合的方式,确保受攻击智能体在触发器激活时产生不利于团队的行为。具体而言,奖励反转是指将原本应该获得的奖励变为惩罚,而单边指导是指在触发器激活时,给予受攻击智能体额外的负面奖励,以强化其不利于团队的行为。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该后门攻击在SMAC环境中对VDN和QMIX算法均有效,攻击成功率高达91.6%,同时保持了较低的清洁性能方差率(3.7%)。这意味着该攻击能够在不显著影响正常性能的情况下,有效地破坏多智能体系统的协作能力。相较于其他后门攻击方法,该方法具有更高的隐蔽性和实用性。
🎯 应用场景
该研究成果可应用于评估和提升多智能体系统的安全性,尤其是在需要高度协作的场景,如自动驾驶车队、机器人协同作业、分布式计算等。通过模拟和防御此类后门攻击,可以提高系统的鲁棒性和可靠性,避免潜在的安全风险和经济损失。该研究也为开发更安全的c-MADRL算法提供了新的思路。
📄 摘要(原文)
Recent studies have shown that cooperative multi-agent deep reinforcement learning (c-MADRL) is under the threat of backdoor attacks. Once a backdoor trigger is observed, it will perform abnormal actions leading to failures or malicious goals. However, existing proposed backdoors suffer from several issues, e.g., fixed visual trigger patterns lack stealthiness, the backdoor is trained or activated by an additional network, or all agents are backdoored. To this end, in this paper, we propose a novel backdoor attack against c-MADRL, which attacks the entire multi-agent team by embedding the backdoor only in a single agent. Firstly, we introduce adversary spatiotemporal behavior patterns as the backdoor trigger rather than manual-injected fixed visual patterns or instant status and control the attack duration. This method can guarantee the stealthiness and practicality of injected backdoors. Secondly, we hack the original reward function of the backdoored agent via reward reverse and unilateral guidance during training to ensure its adverse influence on the entire team. We evaluate our backdoor attacks on two classic c-MADRL algorithms VDN and QMIX, in a popular c-MADRL environment SMAC. The experimental results demonstrate that our backdoor attacks are able to reach a high attack success rate (91.6\%) while maintaining a low clean performance variance rate (3.7\%).