CLNX: Bridging Code and Natural Language for C/C++ Vulnerability-Contributing Commits Identification
作者: Zeqing Qin, Yiwei Wu, Lansheng Han
分类: cs.CR, cs.AI
发布日期: 2024-09-11
备注: 8 pages, 2 figures, conference
💡 一句话要点
提出CLNX,桥接代码与自然语言,轻量级提升LLM的C/C++漏洞识别能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 漏洞识别 C/C++ 自然语言处理 代码自然化 大型语言模型 软件安全 CodeBERT
📋 核心要点
- 现有方法主要依赖于在大型代码数据集上预训练LLM,资源消耗大,效率低,难以快速适应新的漏洞模式。
- CLNX通过结构级和token级自然化,将C/C++代码转换为更易于LLM理解的自然语言表示,保留关键细节。
- 实验结果表明,CLNX显著提升了LLM识别C/C++ VCCs的性能,并成功识别了38个真实世界的OSS漏洞。
📝 摘要(中文)
大型语言模型(LLMs)在漏洞识别方面展现出巨大潜力。鉴于C/C++在过去十年中占据了开源软件(OSS)漏洞的一半,并且OSS中的更新主要通过提交(commits)进行,因此增强LLMs识别C/C++漏洞贡献提交(VCCs)的能力至关重要。然而,当前的研究主要集中在海量代码数据集上对LLMs进行进一步的预训练,这既耗费资源又带来效率挑战。本文提出CodeLinguaNexus (CLNX),以轻量级的方式增强基于BERT的LLMs识别C/C++ VCCs的能力。CLNX作为一个桥梁,促进C/C++程序和LLMs之间的通信。基于提交,CLNX有效地将源代码转换为更自然的表示,同时保留关键细节。具体来说,CLNX首先应用结构级自然化来分解复杂的程序,然后应用token级自然化来解释复杂的符号。在包含25,872个C/C++函数及其提交的公共数据集上评估CLNX。结果表明,CLNX显著提高了LLMs在识别C/C++ VCCs方面的性能。此外,配备CLNX的CodeBERT实现了新的state-of-the-art,并在现实世界中识别出38个OSS漏洞。
🔬 方法详解
问题定义:论文旨在解决C/C++开源软件中漏洞贡献提交(VCCs)的识别问题。现有方法主要依赖于大规模代码预训练LLM,计算成本高昂且效率低下,难以快速适应新的漏洞模式。此外,直接使用LLM处理C/C++代码存在语义理解上的gap,影响识别准确率。
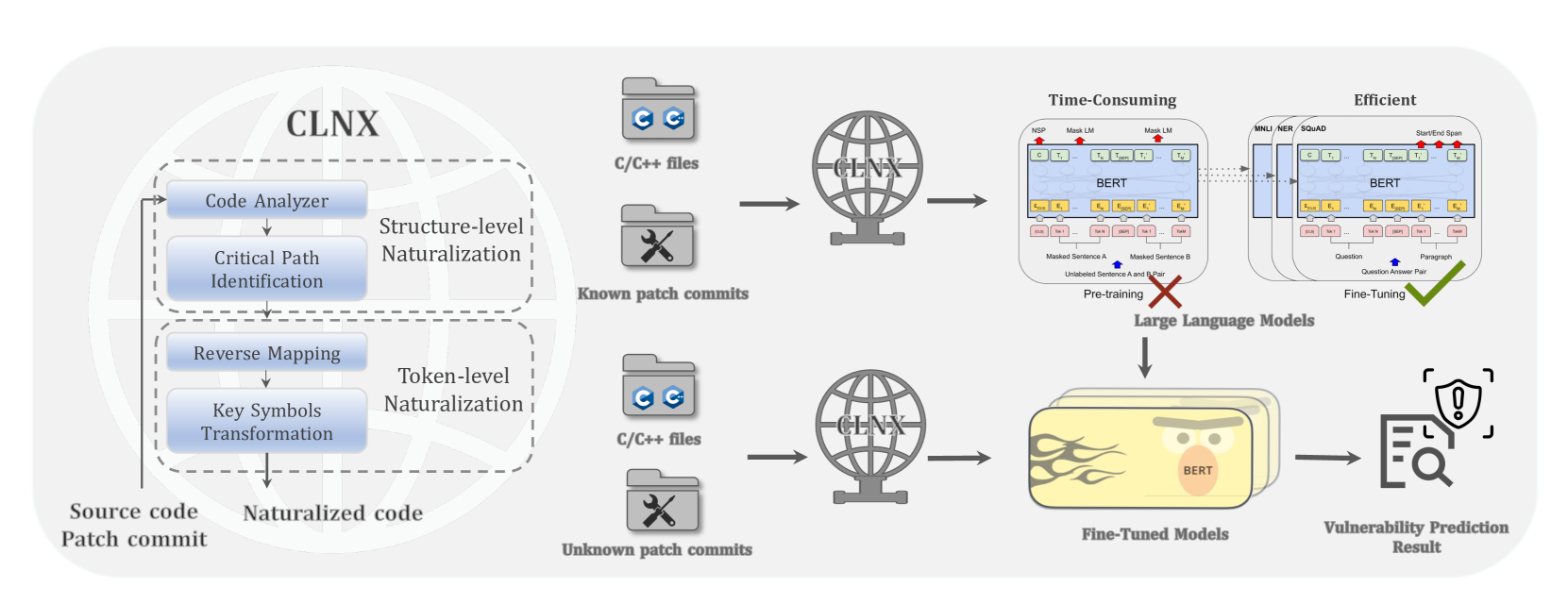
核心思路:论文的核心思路是通过CodeLinguaNexus (CLNX) 桥接代码和自然语言,将C/C++代码转换为更易于LLM理解的自然语言表示,从而提升LLM识别VCCs的能力。CLNX通过结构级和token级自然化,在保留代码关键信息的同时,降低了LLM处理代码的难度。
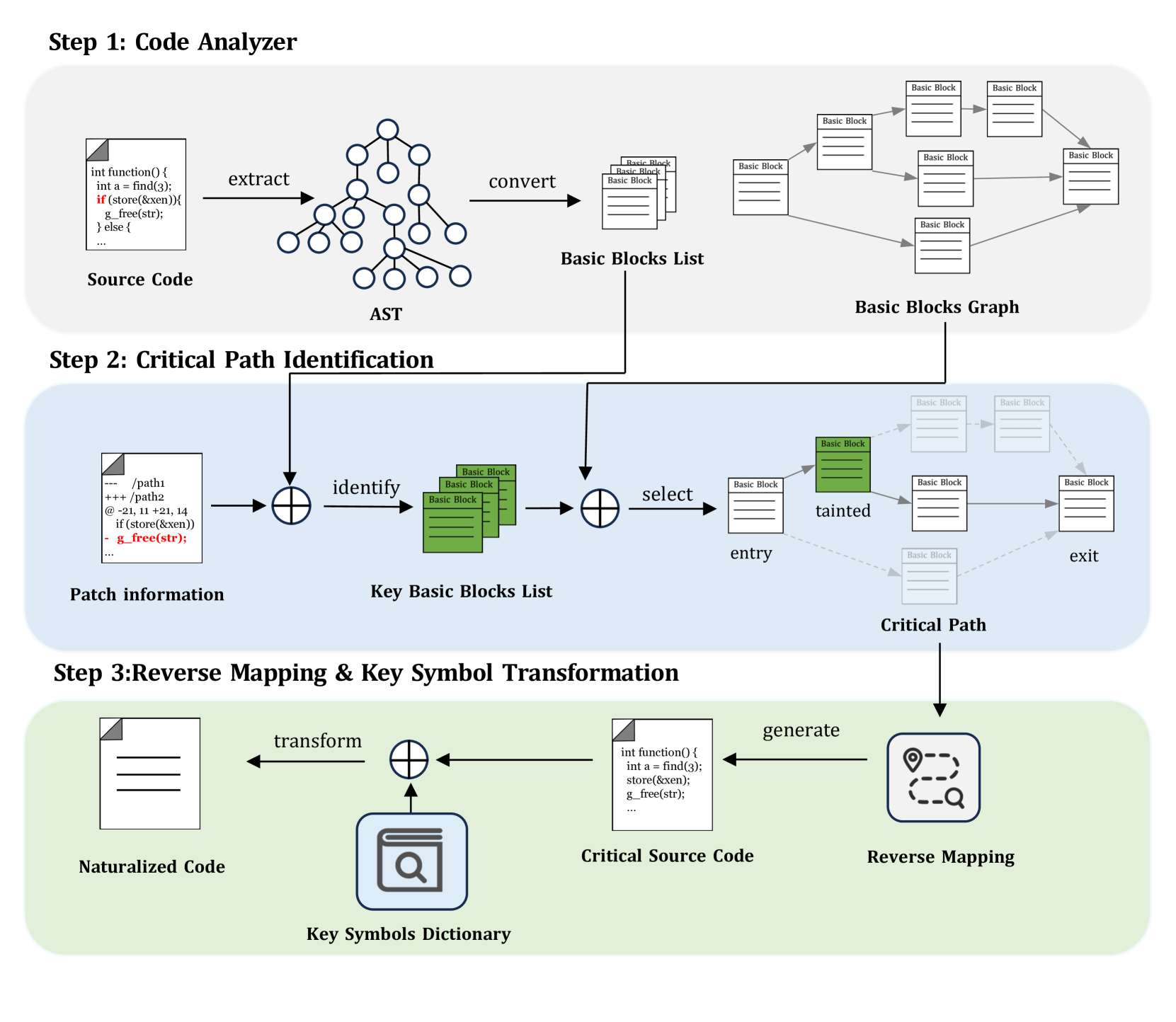
技术框架:CLNX框架主要包含两个阶段:结构级自然化和token级自然化。首先,结构级自然化将复杂的C/C++程序分解为更小的、更易于理解的结构单元,例如函数、循环和条件语句。然后,token级自然化将复杂的符号(例如指针、运算符和宏)转换为更自然的语言描述。最终,将自然化后的代码表示输入到LLM中进行VCCs识别。
关键创新:CLNX的关键创新在于其轻量级的代码自然化方法,它避免了大规模的代码预训练,而是通过结构级和token级转换,将代码转换为更易于LLM理解的自然语言表示。这种方法既降低了计算成本,又提高了LLM的识别准确率。
关键设计:结构级自然化主要依赖于抽象语法树(AST)的分析,将代码分解为结构化的节点。Token级自然化则使用预定义的规则和词汇表,将复杂的符号转换为自然语言描述。例如,指针可以被描述为“a pointer to”,运算符可以被描述为“plus”或“minus”。论文未明确提及损失函数和网络结构等细节,推测是使用了预训练的CodeBERT模型,并可能在其基础上进行了微调。
🖼️ 关键图片
📊 实验亮点
实验结果表明,CLNX显著提高了LLM识别C/C++ VCCs的性能,配备CLNX的CodeBERT模型达到了新的state-of-the-art。在真实世界的OSS漏洞识别中,CLNX成功识别了38个漏洞,验证了其在实际应用中的有效性。具体性能提升数据未知。
🎯 应用场景
该研究成果可应用于开源软件的安全审计、漏洞挖掘和修复等领域。通过自动识别VCCs,可以帮助开发者及时发现和修复潜在的安全漏洞,提高软件的安全性。此外,该方法还可以用于代码相似性分析、代码搜索和代码生成等任务。
📄 摘要(原文)
Large Language Models (LLMs) have shown great promise in vulnerability identification. As C/C++ comprises half of the Open-Source Software (OSS) vulnerabilities over the past decade and updates in OSS mainly occur through commits, enhancing LLMs' ability to identify C/C++ Vulnerability-Contributing Commits (VCCs) is essential. However, current studies primarily focus on further pre-training LLMs on massive code datasets, which is resource-intensive and poses efficiency challenges. In this paper, we enhance the ability of BERT-based LLMs to identify C/C++ VCCs in a lightweight manner. We propose CodeLinguaNexus (CLNX) as a bridge facilitating communication between C/C++ programs and LLMs. Based on commits, CLNX efficiently converts the source code into a more natural representation while preserving key details. Specifically, CLNX first applies structure-level naturalization to decompose complex programs, followed by token-level naturalization to interpret complex symbols. We evaluate CLNX on public datasets of 25,872 C/C++ functions with their commits. The results show that CLNX significantly enhances the performance of LLMs on identifying C/C++ VCCs. Moreover, CLNX-equipped CodeBERT achieves new state-of-the-art and identifies 38 OSS vulnerabilities in the real world.