MoWE-Audio: Multitask AudioLLMs with Mixture of Weak Encoders
作者: Wenyu Zhang, Shuo Sun, Bin Wang, Xunlong Zou, Zhuohan Liu, Yingxu He, Geyu Lin, Nancy F. Chen, Ai Ti Aw
分类: cs.SD, cs.AI, cs.CL, eess.AS
发布日期: 2024-09-10 (更新: 2025-04-21)
备注: ICASSP 2025
💡 一句话要点
提出MoWE-Audio:利用混合弱编码器的多任务AudioLLM,提升音频特征提取能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: AudioLLM 多任务学习 音频编码器 混合专家模型 弱监督学习 特征提取 语音识别 音频理解
📋 核心要点
- 现有AudioLLM依赖预训练音频编码器,其容量限制阻碍了对新任务和数据集特征的有效捕获。
- MoWE-Audio通过引入混合弱编码器,根据输入音频选择性激活,增强特征提取能力,同时控制模型大小。
- 实验结果表明,MoWE-Audio有效提升了多任务音频处理性能,扩展了AudioLLM的应用范围。
📝 摘要(中文)
大型语言模型(LLM)的快速发展显著增强了自然语言处理能力,促进了AudioLLM的发展,使其能够处理和理解语音和音频输入以及文本。现有的AudioLLM通常将预训练的音频编码器与预训练的LLM相结合,然后在特定音频任务上进行微调。然而,预训练的音频编码器在捕获新任务和数据集的特征方面存在容量限制。为了解决这个问题,我们提出将混合“弱”编码器(MoWE)集成到AudioLLM框架中。MoWE通过一组相对轻量级的编码器来补充基础编码器,这些编码器根据音频输入选择性地激活,以增强特征提取,而不会显著增加模型大小。我们的实验结果表明,MoWE有效地提高了多任务性能,从而扩大了AudioLLM在更多样化的音频任务中的适用性。
🔬 方法详解
问题定义:现有AudioLLM依赖于预训练的音频编码器,但这些编码器在面对新的音频任务和数据集时,往往难以充分提取所需的特征。预训练编码器的容量限制成为了一个瓶颈,限制了模型在新任务上的泛化能力。此外,直接增大预训练编码器的规模会显著增加模型大小和计算成本。
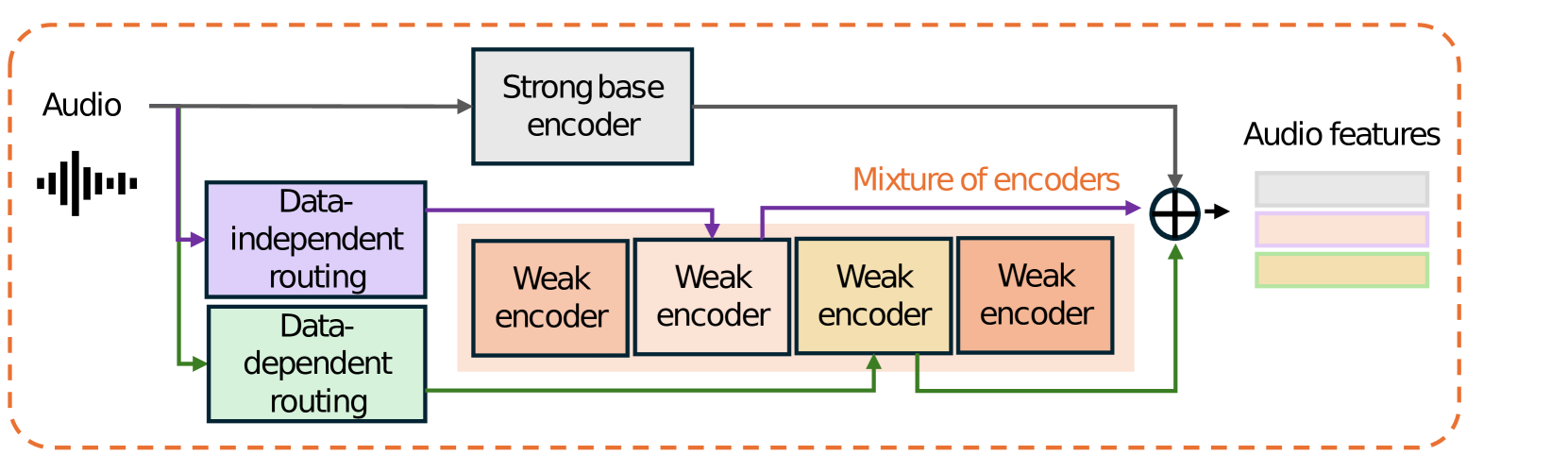
核心思路:MoWE-Audio的核心思路是利用一组“弱”编码器(weak encoders)来补充现有的基础编码器。这些弱编码器相对轻量级,可以针对不同的音频特征进行专门训练。通过混合使用这些弱编码器,模型可以更灵活地提取音频特征,而无需显著增加模型整体的参数量。
技术框架:MoWE-Audio的整体框架包括一个基础音频编码器和一个混合弱编码器模块(MoWE)。首先,音频输入通过基础编码器提取初步特征。然后,MoWE模块根据音频输入的内容,选择性地激活一组弱编码器。每个弱编码器提取不同的特征表示,这些特征表示与基础编码器的输出进行融合,形成最终的音频特征表示。最后,融合后的特征被输入到预训练的LLM中进行后续处理。
关键创新:MoWE-Audio的关键创新在于混合弱编码器的设计。与传统的单一编码器相比,MoWE能够更灵活地提取音频特征,从而提高模型在多任务场景下的性能。此外,弱编码器的设计使得模型可以在不显著增加参数量的情况下,提升特征提取能力。
关键设计:MoWE模块的关键设计包括:1) 弱编码器的数量和结构;2) 弱编码器的选择机制(例如,使用门控机制或注意力机制);3) 特征融合策略(例如,使用加权平均或拼接)。论文中可能还涉及了特定的损失函数设计,以鼓励弱编码器学习到互补的特征表示。
🖼️ 关键图片

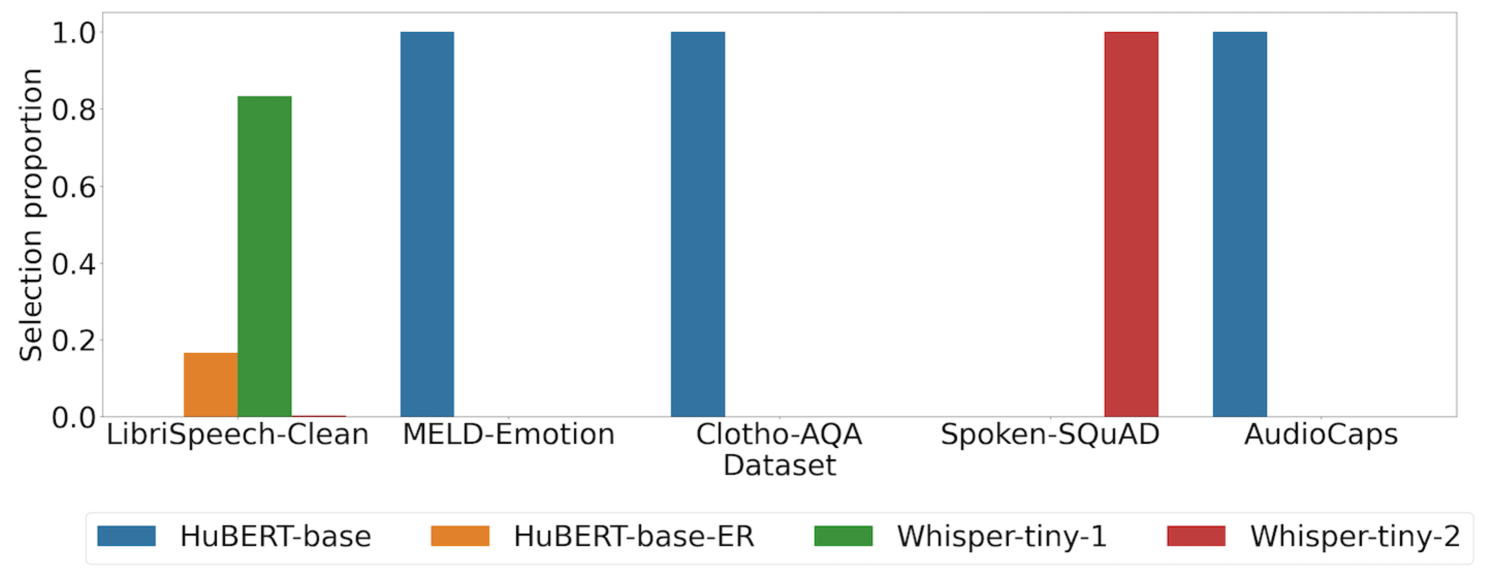
📊 实验亮点
论文提出的MoWE-Audio通过混合弱编码器,有效提升了多任务音频处理性能。具体实验结果未知,但摘要中明确指出MoWE能够有效地提高多任务性能,扩大AudioLLM在更多样化的音频任务中的适用性。与直接增大预训练编码器规模相比,MoWE在提升性能的同时,能够更好地控制模型大小。
🎯 应用场景
MoWE-Audio具有广泛的应用前景,包括语音识别、语音合成、音乐理解、环境声音识别等。该技术可以应用于智能助手、语音搜索、音频内容分析等领域,提升音频处理系统的性能和用户体验。未来,MoWE-Audio有望推动AudioLLM在更多实际场景中的应用。
📄 摘要(原文)
The rapid advancements in large language models (LLMs) have significantly enhanced natural language processing capabilities, facilitating the development of AudioLLMs that process and understand speech and audio inputs alongside text. Existing AudioLLMs typically combine a pre-trained audio encoder with a pre-trained LLM, which are subsequently finetuned on specific audio tasks. However, the pre-trained audio encoder has constrained capacity to capture features for new tasks and datasets. To address this, we propose to incorporate mixtures of `weak' encoders (MoWE) into the AudioLLM framework. MoWE supplements a base encoder with a pool of relatively light weight encoders, selectively activated based on the audio input to enhance feature extraction without significantly increasing model size. Our empirical results demonstrate that MoWE effectively improves multi-task performance, broadening the applicability of AudioLLMs to more diverse audio tasks.