Superior Computer Chess with Model Predictive Control, Reinforcement Learning, and Rollout
作者: Atharva Gundawar, Yuchao Li, Dimitri Bertsekas
分类: cs.AI, cs.LG, eess.SY
发布日期: 2024-09-10
💡 一句话要点
提出基于模型预测控制、强化学习和Rollout的计算机象棋架构,显著提升引擎性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 计算机象棋 模型预测控制 强化学习 Rollout 多智能体系统 博弈AI
📋 核心要点
- 现有计算机象棋引擎的性能提升面临瓶颈,需要更智能的走法选择策略。
- 利用模型预测控制、强化学习和Rollout,构建多引擎协同的走法选择架构,提升整体智能。
- 实验表明,该架构能显著提升各种象棋引擎的性能,包括顶尖引擎和较弱引擎。
📝 摘要(中文)
本文将模型预测控制(MPC)、Rollout和强化学习(RL)方法应用于计算机象棋。我们提出了一种新的走法选择架构,其中现有的象棋引擎被用作组件。一个引擎用于在近似值空间MPC/RL方案中提供位置评估,而第二个引擎用作名义对手,以模拟或近似真实对手玩家的走法。我们表明,我们的架构大大提高了位置评估引擎的性能。换句话说,我们的架构在它所基于的引擎的智能之上提供了一个额外的智能层。对于任何引擎,无论其强度如何,例如Stockfish和Komodo Dragon(具有不同的强度)以及较弱的引擎,都是如此。在结构上,我们的基本架构通过一步前瞻搜索来选择走法,其中中间走法由名义对手引擎生成,然后由另一个象棋引擎进行位置评估。省略名义对手的更简单的方案也比位置评估器表现更好,但提升幅度没有那么大。涉及多步前瞻的更复杂的方案也可以使用,并且通常会随着前瞻长度的增加而表现更好。从理论上讲,我们的方法依赖于通用的成本改进属性和牛顿法的超线性收敛框架,牛顿法从根本上支撑着值空间近似,以及相关的MPC/RL和Rollout/策略迭代方案。该框架的一个关键要求是第一步前瞻应该被精确执行。这一事实指导了我们的架构选择,并且显然是提高即使是最好的可用象棋引擎的性能的一个重要因素。
🔬 方法详解
问题定义:论文旨在解决计算机象棋中现有引擎性能提升受限的问题。现有方法通常依赖于单一引擎的评估函数和搜索算法,难以充分利用不同引擎的优势,且容易陷入局部最优解。因此,如何设计一种更智能的走法选择架构,充分利用现有引擎的能力,是本文要解决的核心问题。
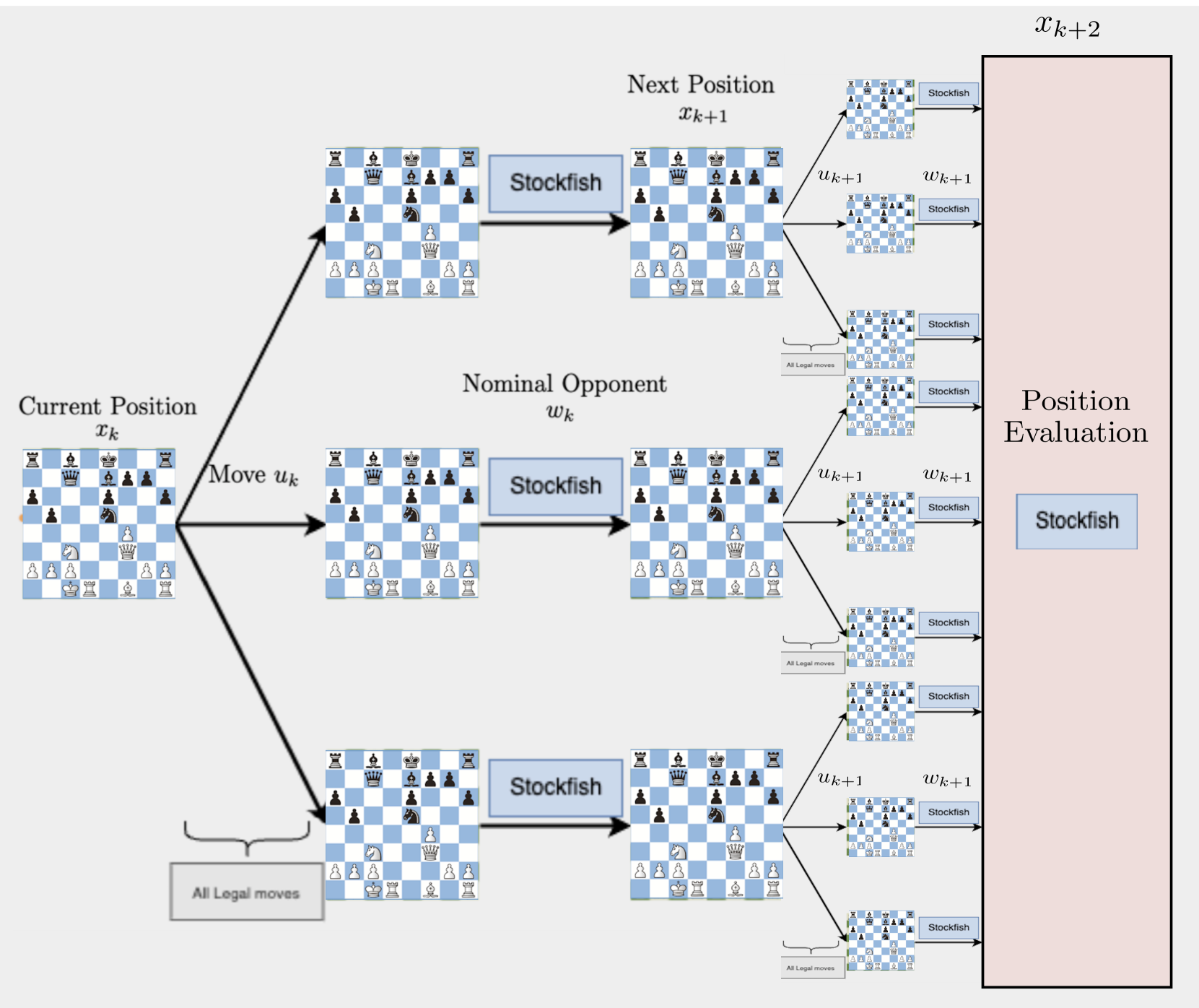
核心思路:论文的核心思路是构建一个基于模型预测控制(MPC)、强化学习(RL)和Rollout的走法选择架构,将多个象棋引擎作为组件协同工作。通过MPC进行前瞻搜索,利用一个引擎进行位置评估,另一个引擎模拟对手走法,从而更准确地评估当前局势,选择最优走法。这种多引擎协同的方式可以有效提升整体智能,避免单一引擎的局限性。
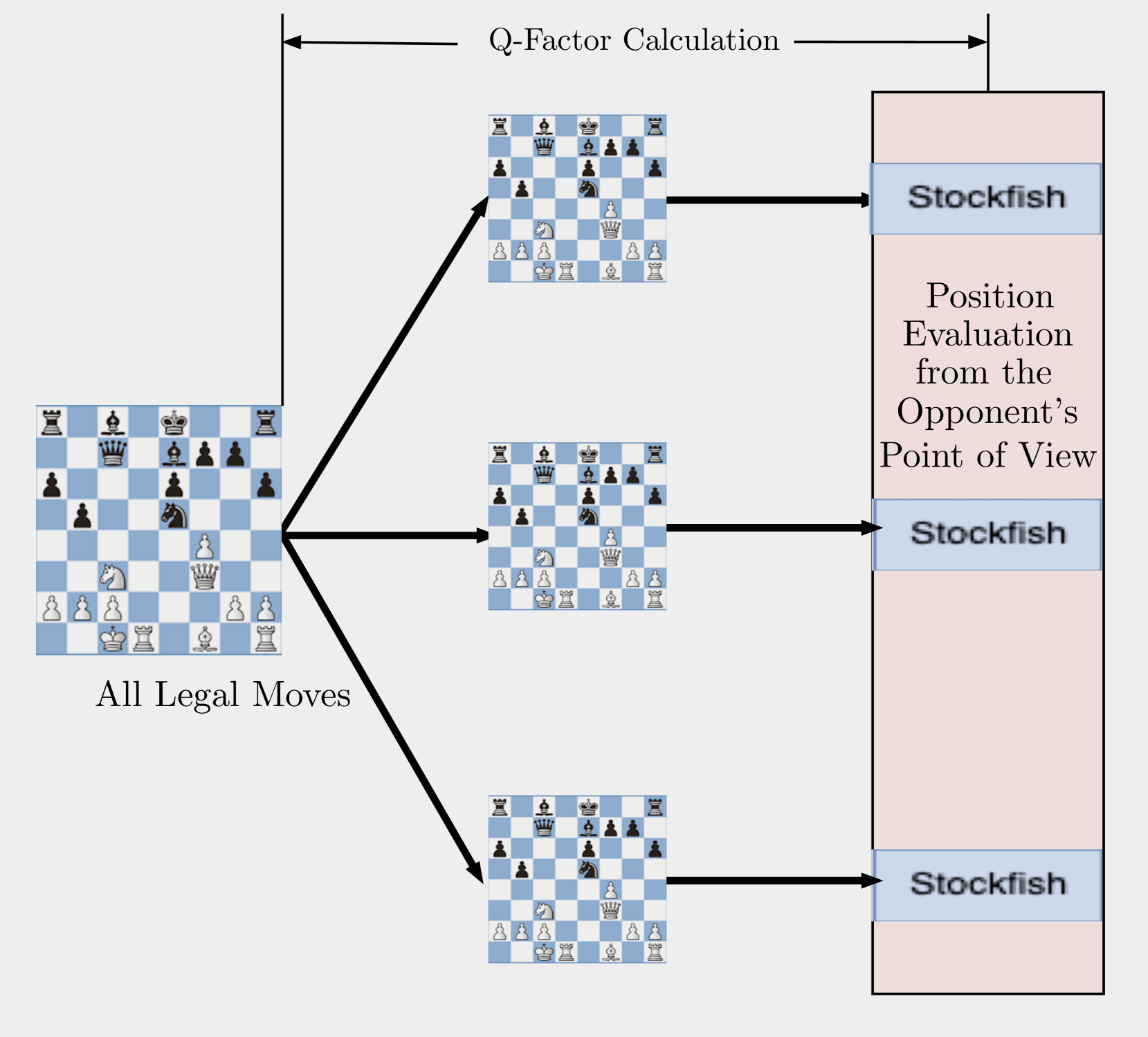
技术框架:整体架构包含以下几个主要模块:1) 名义对手引擎:用于模拟对手的走法,预测对手可能的响应。2) 位置评估引擎:用于评估当前棋局的优劣势,提供价值函数近似。3) 模型预测控制(MPC)模块:通过一步或多步前瞻搜索,结合名义对手引擎和位置评估引擎的输出,选择最优走法。基本流程是:首先,由当前引擎选择一个可能的走法;然后,由名义对手引擎模拟对手的响应;最后,由位置评估引擎评估棋局,MPC模块根据评估结果选择最佳走法。
关键创新:最重要的技术创新点在于将模型预测控制、强化学习和Rollout方法应用于计算机象棋,并设计了一种多引擎协同的走法选择架构。与传统方法相比,该架构能够充分利用不同引擎的优势,通过前瞻搜索和价值函数近似,更准确地评估棋局,选择最优走法。此外,该架构具有通用性,可以应用于各种象棋引擎,提升它们的性能。
关键设计:论文强调第一步前瞻需要精确执行,这指导了架构的设计。具体的技术细节包括:1) 前瞻步数:可以选择一步或多步前瞻,通常前瞻步数越多,性能越好。2) 名义对手引擎的选择:可以选择不同强度的引擎作为名义对手,以模拟不同水平的对手。3) 位置评估引擎的选择:可以选择不同的引擎进行位置评估,以利用不同引擎的评估能力。4) 价值函数近似:使用位置评估引擎的输出作为价值函数近似,用于指导MPC的搜索过程。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该架构能够显著提升各种象棋引擎的性能。即使是顶尖引擎如Stockfish和Komodo Dragon,在该架构下也能获得性能提升。更简单的方案(省略名义对手)也能提升性能,但幅度较小。更复杂的多步前瞻方案通常表现更好,且随着前瞻步数的增加,性能也随之提升。具体性能数据未知,但摘要强调了“substantially”的提升。
🎯 应用场景
该研究成果可应用于各种棋类游戏的人工智能开发,例如围棋、国际象棋等。通过构建多智能体协同的决策架构,可以提升AI在复杂策略游戏中的表现。此外,该方法还可以推广到其他需要复杂决策的领域,例如自动驾驶、机器人控制等,具有广泛的应用前景和实际价值。
📄 摘要(原文)
In this paper we apply model predictive control (MPC), rollout, and reinforcement learning (RL) methodologies to computer chess. We introduce a new architecture for move selection, within which available chess engines are used as components. One engine is used to provide position evaluations in an approximation in value space MPC/RL scheme, while a second engine is used as nominal opponent, to emulate or approximate the moves of the true opponent player. We show that our architecture improves substantially the performance of the position evaluation engine. In other words our architecture provides an additional layer of intelligence, on top of the intelligence of the engines on which it is based. This is true for any engine, regardless of its strength: top engines such as Stockfish and Komodo Dragon (of varying strengths), as well as weaker engines. Structurally, our basic architecture selects moves by a one-move lookahead search, with an intermediate move generated by a nominal opponent engine, and followed by a position evaluation by another chess engine. Simpler schemes that forego the use of the nominal opponent, also perform better than the position evaluator, but not quite by as much. More complex schemes, involving multistep lookahead, may also be used and generally tend to perform better as the length of the lookahead increases. Theoretically, our methodology relies on generic cost improvement properties and the superlinear convergence framework of Newton's method, which fundamentally underlies approximation in value space, and related MPC/RL and rollout/policy iteration schemes. A critical requirement of this framework is that the first lookahead step should be executed exactly. This fact has guided our architectural choices, and is apparently an important factor in improving the performance of even the best available chess engines.