MAGDA: Multi-agent guideline-driven diagnostic assistance
作者: David Bani-Harouni, Nassir Navab, Matthias Keicher
分类: cs.AI
发布日期: 2024-09-10
💡 一句话要点
提出MAGDA:多智能体协同,指南驱动的诊断辅助系统,提升医疗决策质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 医学图像诊断 大型语言模型 零样本学习 指南驱动 胸部X射线 临床决策支持
📋 核心要点
- 现有大型语言模型在医学诊断中表现出潜力,但缺乏对医学指南的有效遵循,限制了其临床应用。
- MAGDA利用多智能体系统,每个智能体遵循特定诊断指南,协同分析医学图像并提供可解释的诊断推理。
- 在CheXpert和ChestX-ray 14 Longtail数据集上的实验表明,MAGDA优于现有零样本方法,尤其在罕见疾病诊断方面。
📝 摘要(中文)
在急诊科、乡村医院或欠发达地区的诊所中,临床医生常常缺乏训练有素的放射科医生提供的快速图像分析,这对患者的健康可能产生不利影响。大型语言模型(LLM)有潜力通过提供见解来减轻这些临床医生的一些压力,从而帮助他们做出决策。虽然这些LLM在医学考试中取得了很高的测试结果,展示了其强大的理论医学知识,但它们往往不遵循医学指南。在这项工作中,我们提出了一种新的零样本指南驱动决策支持方法。我们构建了一个由多个LLM智能体组成的系统,并使用对比视觉-语言模型进行增强,这些智能体协同工作以达成患者诊断。在为智能体提供简单的诊断指南后,它们将综合提示并根据这些指南筛选图像中的发现。最后,它们为诊断提供可理解的思维链推理,然后对其进行自我完善,以考虑疾病之间的相互依赖性。由于我们的方法是零样本的,因此它适用于罕见疾病的设置,在这些设置中,训练数据有限,但可以获得专家编写的疾病描述。我们在两个胸部X射线数据集CheXpert和ChestX-ray 14 Longtail上评估了我们的方法,展示了相对于现有零样本方法的性能改进以及对罕见疾病的泛化能力。
🔬 方法详解
问题定义:论文旨在解决临床医生在缺乏放射科专家支持的情况下,如何利用大型语言模型(LLM)进行准确、可靠的医学图像诊断的问题。现有LLM虽然具备医学知识,但往往忽略医学指南,导致诊断结果不符合临床实践,尤其是在罕见疾病诊断方面,缺乏足够的训练数据支撑。
核心思路:论文的核心思路是构建一个多智能体系统,每个智能体负责遵循特定的诊断指南,通过协同工作和信息交互,模拟专家团队的诊断过程。这种方法旨在将医学指南融入诊断流程,提高诊断的准确性和可靠性,并增强模型的可解释性。
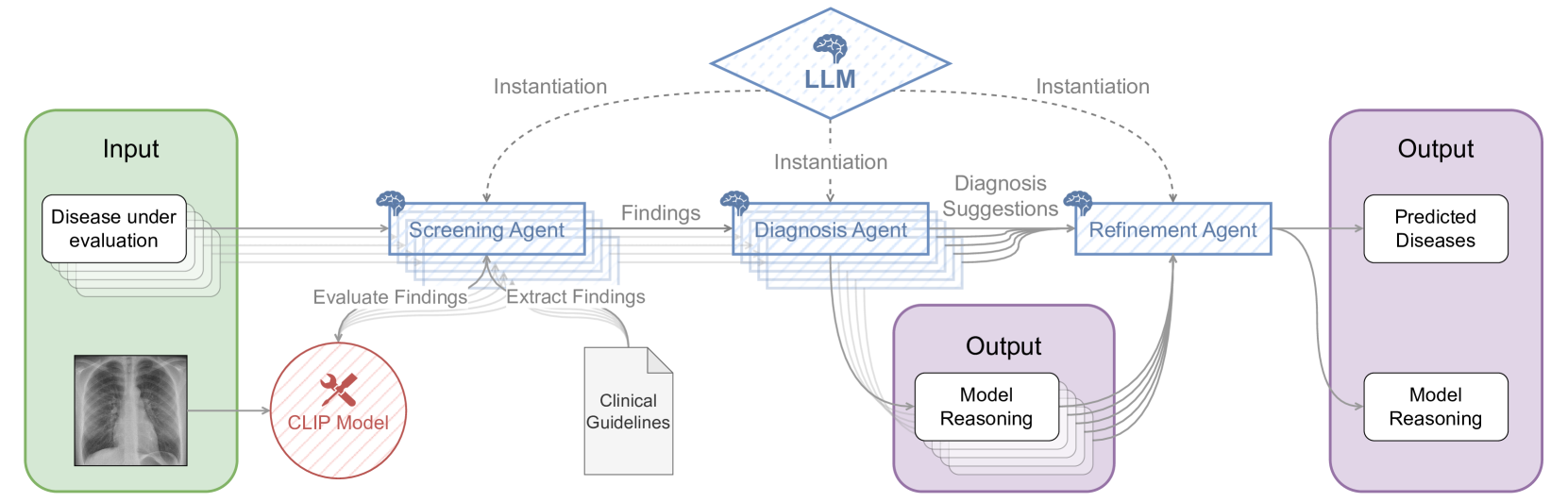
技术框架:MAGDA系统包含多个LLM智能体和一个对比视觉-语言模型。整体流程如下:1) 输入医学图像和诊断指南;2) 各个智能体根据指南生成提示,并利用视觉-语言模型分析图像,提取相关特征;3) 智能体之间交换信息,进行协同推理,生成诊断结果和思维链;4) 系统对诊断结果进行自我完善,考虑疾病之间的相互依赖性,最终输出诊断报告。
关键创新:MAGDA的关键创新在于其多智能体协同诊断框架,以及指南驱动的提示生成和推理过程。与传统的单模型方法相比,MAGDA能够更好地整合医学指南,提高诊断的准确性和可解释性。此外,MAGDA的零样本学习能力使其能够应用于罕见疾病的诊断,无需大量的训练数据。
关键设计:MAGDA的关键设计包括:1) 智能体的数量和角色分配,每个智能体负责不同的疾病或诊断步骤;2) 提示生成策略,如何将诊断指南转化为有效的提示,引导智能体进行图像分析;3) 智能体之间的信息交换机制,如何有效地整合各个智能体的知识和推理结果;4) 自我完善机制,如何利用疾病之间的相互依赖性,提高诊断的准确性。
🖼️ 关键图片

📊 实验亮点
MAGDA在CheXpert和ChestX-ray 14 Longtail数据集上进行了评估,实验结果表明,MAGDA显著优于现有的零样本方法。尤其在罕见疾病诊断方面,MAGDA表现出更强的泛化能力。具体性能数据在论文中给出,证明了MAGDA的有效性和实用性。
🎯 应用场景
MAGDA可应用于急诊科、乡村医院、欠发达地区诊所等缺乏放射科专家的场景,辅助临床医生进行快速、准确的医学图像诊断。该系统还可用于医学教育和培训,帮助医学生学习和掌握诊断流程。未来,MAGDA有望扩展到其他医学影像模态和疾病领域,成为临床决策支持的重要工具。
📄 摘要(原文)
In emergency departments, rural hospitals, or clinics in less developed regions, clinicians often lack fast image analysis by trained radiologists, which can have a detrimental effect on patients' healthcare. Large Language Models (LLMs) have the potential to alleviate some pressure from these clinicians by providing insights that can help them in their decision-making. While these LLMs achieve high test results on medical exams showcasing their great theoretical medical knowledge, they tend not to follow medical guidelines. In this work, we introduce a new approach for zero-shot guideline-driven decision support. We model a system of multiple LLM agents augmented with a contrastive vision-language model that collaborate to reach a patient diagnosis. After providing the agents with simple diagnostic guidelines, they will synthesize prompts and screen the image for findings following these guidelines. Finally, they provide understandable chain-of-thought reasoning for their diagnosis, which is then self-refined to consider inter-dependencies between diseases. As our method is zero-shot, it is adaptable to settings with rare diseases, where training data is limited, but expert-crafted disease descriptions are available. We evaluate our method on two chest X-ray datasets, CheXpert and ChestX-ray 14 Longtail, showcasing performance improvement over existing zero-shot methods and generalizability to rare diseases.