MLLM-LLaVA-FL: Multimodal Large Language Model Assisted Federated Learning
作者: Jianyi Zhang, Hao Frank Yang, Ang Li, Xin Guo, Pu Wang, Haiming Wang, Yiran Chen, Hai Li
分类: cs.AI, cs.CL, cs.LG
发布日期: 2024-09-09 (更新: 2024-12-02)
备注: Accepted to WACV 2025
期刊: IEEE/CVF Winter Conference on Applications of Computer Vision (WACV 2025)
💡 一句话要点
提出MLLM-LLaVA-FL框架,利用多模态大语言模型辅助联邦学习,解决数据异构和长尾问题。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 多模态学习 大语言模型 数据异构 长尾分布
📋 核心要点
- 联邦学习面临数据异构性挑战,导致模型性能下降,难以充分利用各客户端数据。
- 利用多模态大语言模型MLLM的跨模态理解能力,辅助联邦学习,提升模型在异构数据上的泛化能力。
- 通过全局预训练和MLLM监督下的全局对齐,实验证明该框架在异构和长尾数据场景下性能优异。
📝 摘要(中文)
本文提出了一种名为多模态大语言模型辅助联邦学习(MLLM-LLaVA-FL)的新型联邦学习框架。该框架利用服务器端强大的多模态大语言模型(MLLMs),如GPT-4v和LLaVA,来解决联邦学习中普遍存在的数据异构性和长尾分布挑战。凭借MLLMs先进的跨模态表征能力和丰富的开放词汇先验知识,MLLM-LLaVA-FL能够有效利用来自网站的大量未被充分利用的开源数据和强大的服务器端计算资源。该框架不仅提升了性能,而且避免了增加本地设备的隐私泄露风险和计算负担,这与以往的方法不同。MLLM-LLaVA-FL包含三个关键阶段:首先,借助MLLMs的辅助,利用大量在线开源数据对模型进行全局视觉-文本预训练;其次,将预训练模型分发给各个客户端进行本地训练;最后,将本地训练的模型传回服务器后,在MLLMs的监督下进行全局对齐,以进一步提升性能。在标准基准数据集上的实验结果表明,该框架在联邦学习中数据异构和长尾分布的典型场景下表现出良好的性能。
🔬 方法详解
问题定义:联邦学习中,由于各个客户端的数据分布存在差异(数据异构性)以及某些类别的数据量远少于其他类别(长尾分布),导致全局模型在某些客户端或某些类别上的性能显著下降。现有的联邦学习方法难以有效解决这些问题,并且可能增加客户端的计算负担或隐私泄露风险。
核心思路:利用多模态大语言模型(MLLMs)强大的跨模态表征能力和丰富的先验知识,在服务器端辅助联邦学习。通过MLLMs对数据的理解和指导,提升模型在异构数据上的泛化能力,并缓解长尾分布带来的影响。同时,将计算密集型任务放在服务器端执行,避免增加客户端的负担。
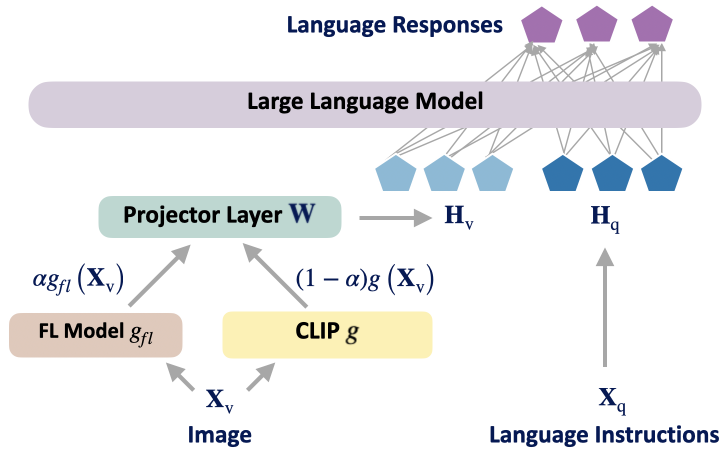
技术框架:MLLM-LLaVA-FL框架包含三个主要阶段: 1. 全局视觉-文本预训练:利用MLLMs辅助,从互联网上获取大量开源数据,进行视觉-文本联合预训练,提升模型的初始性能。 2. 本地训练:将预训练模型分发到各个客户端进行本地训练,利用本地数据对模型进行微调。 3. 全局对齐:将本地训练的模型上传到服务器,在MLLMs的监督下进行全局对齐,进一步提升模型性能,缓解数据异构性带来的影响。
关键创新:该方法的核心创新在于利用MLLMs辅助联邦学习,将MLLMs的跨模态理解能力和先验知识引入到联邦学习过程中。与传统的联邦学习方法相比,该方法能够更好地处理数据异构性和长尾分布问题,并且避免了增加客户端的计算负担和隐私泄露风险。
关键设计: 1. MLLM的选择:选择具有强大跨模态表征能力和丰富先验知识的MLLM,例如LLaVA。 2. 预训练数据:利用MLLMs从互联网上获取大量相关的视觉-文本数据,用于全局预训练。 3. 全局对齐策略:设计合适的全局对齐策略,利用MLLMs的监督信号,使各个客户端的模型能够更好地对齐,提升全局模型的性能。
🖼️ 关键图片

📊 实验亮点
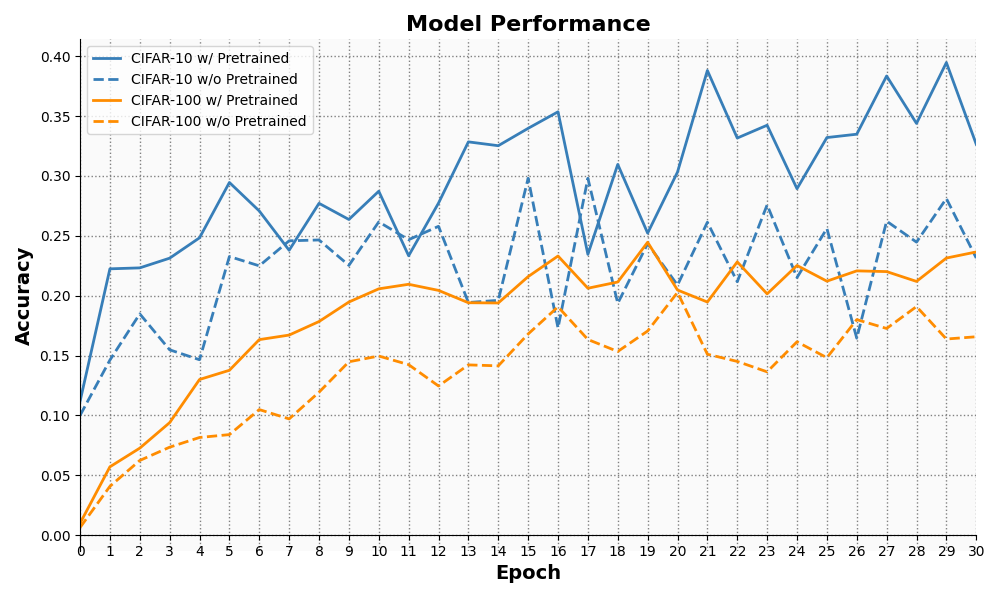
实验结果表明,MLLM-LLaVA-FL框架在数据异构和长尾分布的联邦学习场景下表现出良好的性能。与传统的联邦学习方法相比,该框架能够显著提升模型的准确率和泛化能力。具体的性能提升数据需要在论文中查找,这里无法给出确切数值。
🎯 应用场景
该研究成果可应用于医疗影像分析、自动驾驶、智能零售等领域。在这些场景中,数据通常分布在不同的机构或设备上,且存在数据异构性和长尾分布问题。MLLM-LLaVA-FL框架能够有效解决这些问题,提升模型在实际应用中的性能和鲁棒性,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
Previous studies on federated learning (FL) often encounter performance degradation due to data heterogeneity among different clients. In light of the recent advances in multimodal large language models (MLLMs), such as GPT-4v and LLaVA, which demonstrate their exceptional proficiency in multimodal tasks, such as image captioning and multimodal question answering. We introduce a novel federated learning framework, named Multimodal Large Language Model Assisted Federated Learning (MLLM-LLaVA-FL), which employs powerful MLLMs at the server end to address the heterogeneous and long-tailed challenges. Owing to the advanced cross-modality representation capabilities and the extensive open-vocabulary prior knowledge of MLLMs, our framework is adept at harnessing the extensive, yet previously underexploited, open-source data accessible from websites and powerful server-side computational resources. Hence, the MLLM-LLaVA-FL not only enhances the performance but also avoids increasing the risk of privacy leakage and the computational burden on local devices, distinguishing it from prior methodologies. Our framework has three key stages. Initially, we conduct global visual-text pretraining of the model. This pretraining is facilitated by utilizing the extensive open-source data available online, with the assistance of MLLMs. Subsequently, the pretrained model is distributed among various clients for local training. Finally, once the locally trained models are transmitted back to the server, a global alignment is carried out under the supervision of MLLMs to further enhance the performance. Experimental evaluations on established benchmarks, show that our framework delivers promising performance in the typical scenarios with data heterogeneity and long-tail distribution across different clients in FL.