A First Look At Efficient And Secure On-Device LLM Inference Against KV Leakage
作者: Huan Yang, Deyu Zhang, Yudong Zhao, Yuanchun Li, Yunxin Liu
分类: cs.CR, cs.AI
发布日期: 2024-09-06
💡 一句话要点
提出KV-Shield,防御设备端LLM推理中KV对泄露导致的隐私风险。
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction)
关键词: 设备端LLM 隐私保护 KV对泄露 可信执行环境 置换算法
📋 核心要点
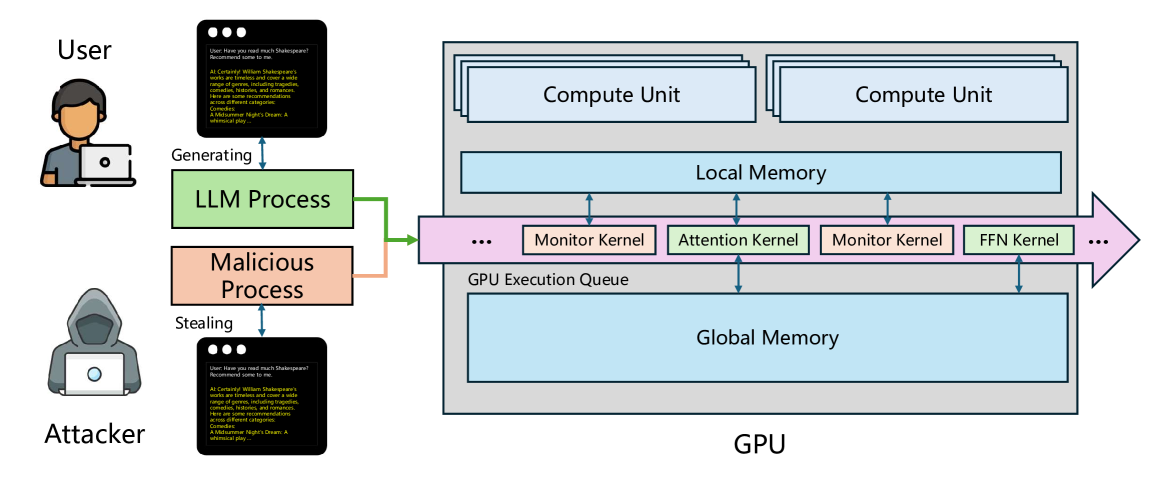
- 设备端LLM推理面临KV对泄露风险,攻击者可借此重建用户对话,现有FHE和TEE方案计算开销大或资源受限。
- KV-Shield通过在初始化阶段置换权重矩阵,运行时阶段反向置换注意力向量,确保KV对的安全性。
- 置换操作在TEE中执行,防止不安全的GPU访问原始KV对,理论分析验证了KV-Shield的正确性和效率。
📝 摘要(中文)
由于其在隐私保护方面的优势,在终端设备上运行LLM模型最近受到了广泛关注。随着轻量级LLM模型和专门设计的GPU的出现,设备端LLM推理已经达到了必要的精度和性能指标。然而,我们发现GPU上的LLM推理可能会泄露隐私敏感的中间信息,特别是KV对。攻击者可以利用这些KV对来重建整个用户对话,从而导致严重的安全漏洞。现有的解决方案,如全同态加密(FHE)和可信执行环境(TEE),要么计算量太大,要么资源有限。为了解决这些问题,我们设计了KV-Shield,它分两个阶段运行。在初始化阶段,它置换权重矩阵,以便所有KV对都相应地置换。在运行时阶段,注意力向量被反向置换,以确保层输出的正确性。所有与置换相关的操作都在TEE中执行,确保不安全的GPU无法访问原始KV对,从而防止对话重建。最后,我们从理论上分析了KV-Shield的正确性,以及它的优点和开销。
🔬 方法详解
问题定义:论文旨在解决设备端LLM推理过程中,GPU上运行的LLM模型可能泄露隐私敏感的KV对信息的问题。攻击者可以利用这些泄露的KV对重建用户的完整对话,从而造成严重的隐私风险。现有的隐私保护方案,如全同态加密(FHE)和可信执行环境(TEE),要么计算开销过大,要么资源受限,无法直接应用于设备端LLM推理。
核心思路:论文的核心思路是通过置换(permutation)的方式来保护KV对的隐私。具体来说,通过在初始化阶段对权重矩阵进行置换,使得KV对也相应地被置换。在运行时阶段,对注意力向量进行反向置换,以保证LLM推理的正确性。这种方法的核心在于,即使攻击者获取了被置换的KV对,也无法直接还原出原始的KV对,从而保护了用户的隐私。
技术框架:KV-Shield主要包含两个阶段:初始化阶段和运行时阶段。在初始化阶段,KV-Shield对LLM的权重矩阵进行置换,并将置换后的权重矩阵加载到GPU上。在运行时阶段,当LLM进行推理时,KV-Shield首先对注意力向量进行反向置换,然后将反向置换后的注意力向量输入到LLM中进行计算。计算完成后,LLM输出的结果是正确的,但是KV对是被置换过的,从而保护了用户的隐私。所有的置换操作都在TEE中执行,以确保安全性。
关键创新:KV-Shield的关键创新在于利用置换操作来保护KV对的隐私,同时保证LLM推理的正确性。与现有的隐私保护方案相比,KV-Shield的计算开销更小,资源消耗更低,更适合在设备端LLM推理中使用。此外,KV-Shield将所有的置换操作都放在TEE中执行,进一步提高了安全性。
关键设计:KV-Shield的关键设计包括:1) 如何选择合适的置换方式,以保证KV对的隐私性和LLM推理的正确性;2) 如何在TEE中高效地执行置换操作,以降低计算开销;3) 如何将置换操作集成到现有的LLM推理框架中。论文中没有明确给出具体的置换算法或参数设置,这部分可能是未来的研究方向。
🖼️ 关键图片

📊 实验亮点
论文提出了KV-Shield,一种针对设备端LLM推理中KV对泄露的防御机制。该机制通过在TEE中执行权重矩阵置换和注意力向量反向置换,有效保护了KV对的隐私。论文进行了理论分析,验证了KV-Shield的正确性和效率。具体的实验数据和性能提升幅度在摘要中未提及,属于未知信息。
🎯 应用场景
KV-Shield可应用于各种需要保护用户隐私的设备端LLM推理场景,例如智能助手、聊天机器人、语音识别等。通过防止KV对泄露,KV-Shield可以有效保护用户的对话内容和个人信息,提升用户对设备端LLM应用的信任度。未来,该技术有望推动设备端LLM的广泛应用,并促进隐私计算技术的发展。
📄 摘要(原文)
Running LLMs on end devices has garnered significant attention recently due to their advantages in privacy preservation. With the advent of lightweight LLM models and specially designed GPUs, on-device LLM inference has achieved the necessary accuracy and performance metrics. However, we have identified that LLM inference on GPUs can leak privacy-sensitive intermediate information, specifically the KV pairs. An attacker could exploit these KV pairs to reconstruct the entire user conversation, leading to significant vulnerabilities. Existing solutions, such as Fully Homomorphic Encryption (FHE) and Trusted Execution Environments (TEE), are either too computation-intensive or resource-limited. To address these issues, we designed KV-Shield, which operates in two phases. In the initialization phase, it permutes the weight matrices so that all KV pairs are correspondingly permuted. During the runtime phase, the attention vector is inversely permuted to ensure the correctness of the layer output. All permutation-related operations are executed within the TEE, ensuring that insecure GPUs cannot access the original KV pairs, thus preventing conversation reconstruction. Finally, we theoretically analyze the correctness of KV-Shield, along with its advantages and overhead.