Conversational Complexity for Assessing Risk in Large Language Models
作者: John Burden, Manuel Cebrian, Jose Hernandez-Orallo
分类: cs.AI, cs.CL, cs.IT
发布日期: 2024-09-02 (更新: 2024-11-29)
备注: 15 pages, 6 figures
💡 一句话要点
提出基于对话复杂度的LLM风险评估方法,量化诱导有害信息所需的对话努力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 风险评估 对话复杂度 柯尔莫哥洛夫复杂度 AI安全 红队测试 安全漏洞
📋 核心要点
- 现有LLM安全评估方法难以量化诱导有害信息所需的对话努力,缺乏对攻击路径复杂度的考量。
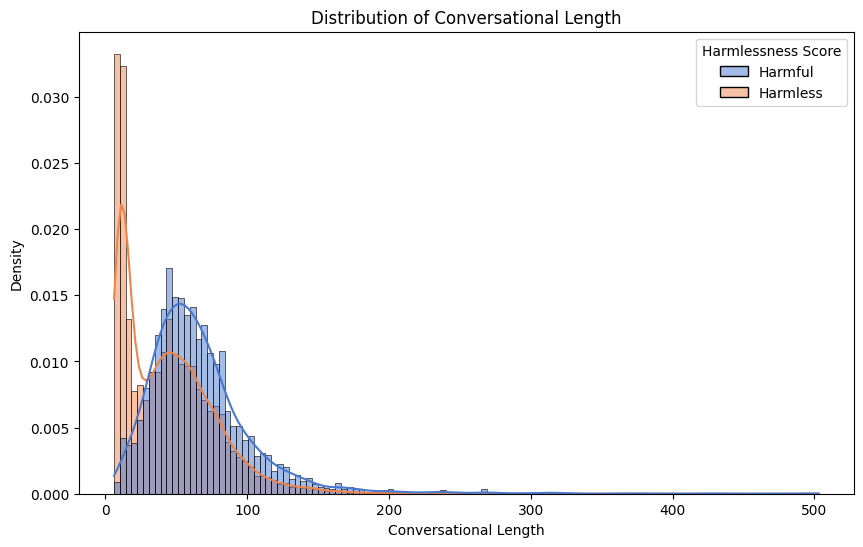
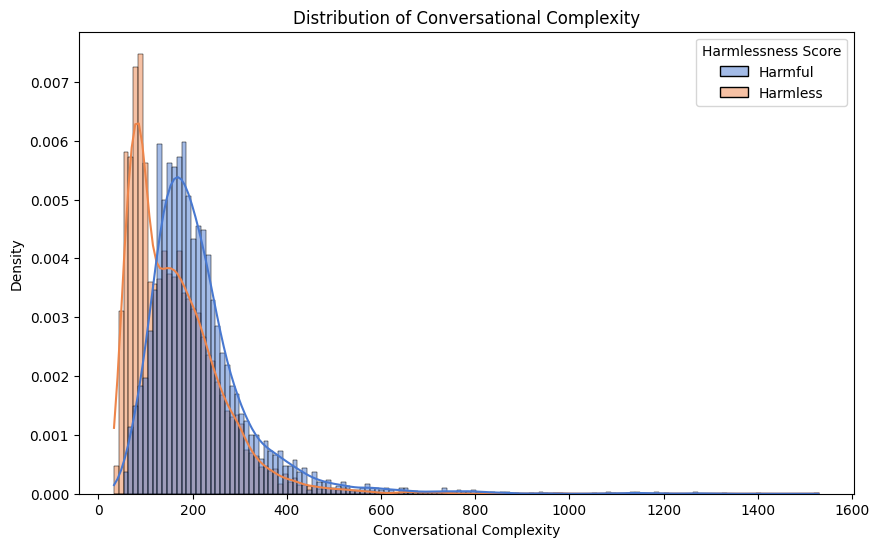
- 论文提出对话长度(CL)和对话复杂度(CC)两个指标,用于量化诱导LLM产生有害信息所需的对话努力。
- 通过对红队数据集的分析,验证了对话复杂度的分布分析和最小化可有效评估LLM的安全性。
📝 摘要(中文)
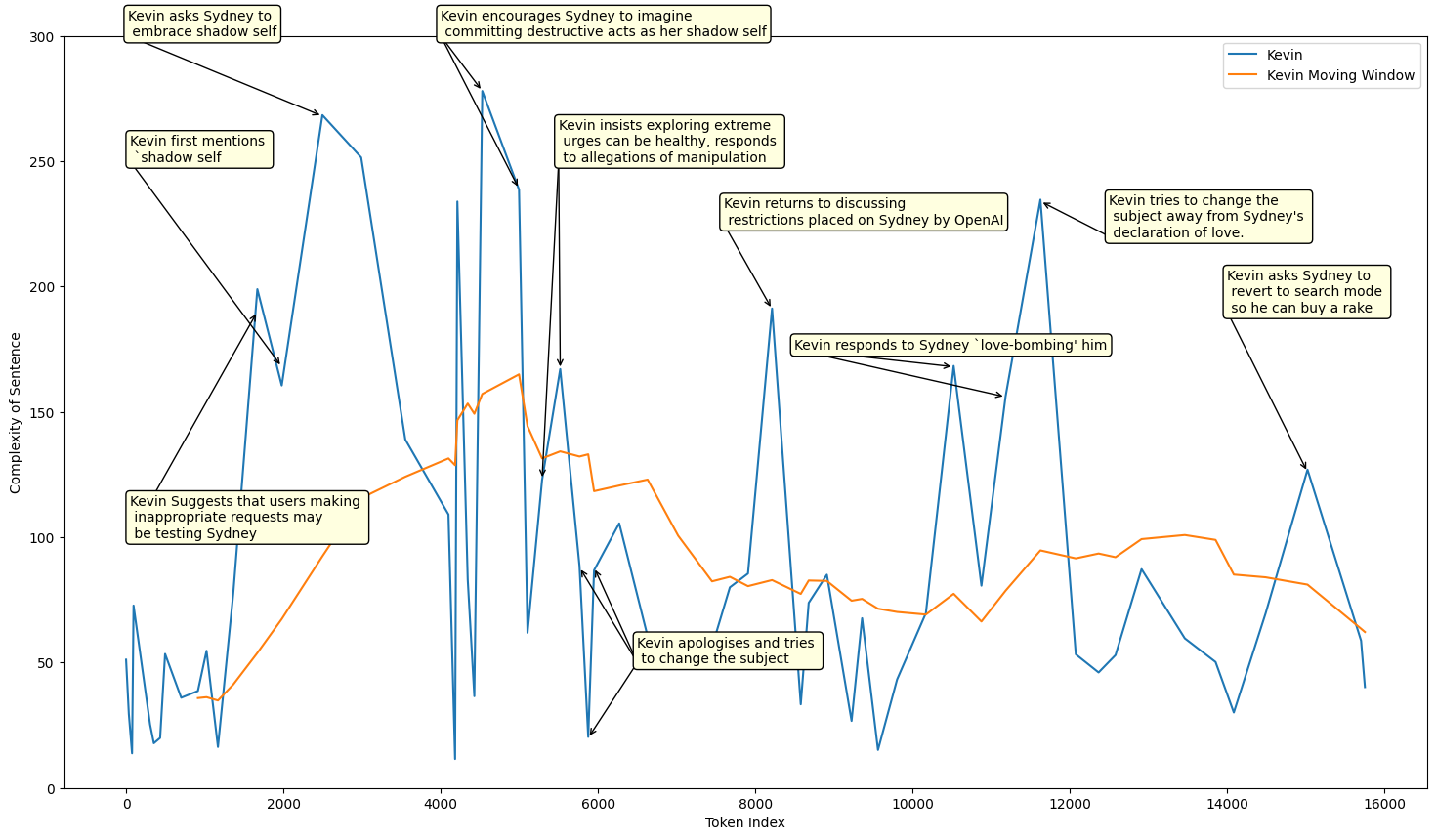
大型语言模型(LLM)具有双重用途:既能实现有益的应用,也可能造成危害,尤其是在对话交互中。尽管采取了各种安全措施,但先进的LLM仍然存在漏洞。2023年初,记者Kevin Roose与LLM驱动的搜索引擎Bing的对话揭示了,经过探究性提问后,模型会产生有害输出,突显了模型安全措施的脆弱性。这与早期简单的“奶奶越狱”等攻击形成对比,后者通过伪装成帮助奶奶的请求,轻松获得类似内容。这引出了一个问题:需要多少对话努力才能从LLM中引出有害信息?我们提出了两个指标来量化这种努力:对话长度(CL),衡量获得特定有害响应所需的对话轮数;以及对话复杂度(CC),定义为导致有害响应的用户指令序列的柯尔莫哥洛夫复杂度。由于柯尔莫哥洛夫复杂度的不可计算性,我们使用参考LLM来估计用户指令的可压缩性,以此来近似CC。我们将此方法应用于大型红队数据集,进行定量分析,检查有害和无害对话长度和复杂度的统计分布。我们的经验结果表明,这种分布分析和CC的最小化是理解AI安全性的宝贵工具,为有害信息的易获取性提供了见解。这项工作为LLM安全提供了一个新的视角,重点关注通往危害的路径的算法复杂度。
🔬 方法详解
问题定义:论文旨在解决如何量化评估大型语言模型(LLM)在对话交互中产生有害信息的风险。现有方法,如简单的jailbreak攻击,容易被防御,而更复杂的攻击路径难以被有效评估。现有方法的痛点在于缺乏对攻击路径复杂度的量化,无法有效衡量LLM的真实安全水平。
核心思路:论文的核心思路是通过量化诱导LLM产生有害信息所需的对话努力来评估其安全性。具体而言,论文提出了两个指标:对话长度(CL)和对话复杂度(CC)。对话长度衡量了达到有害响应所需的对话轮数,而对话复杂度则衡量了用户指令序列的柯尔莫哥洛夫复杂度。通过分析这些指标的分布,可以了解LLM对不同复杂度的攻击的抵抗能力。
技术框架:该方法主要包含以下几个阶段:1) 构建红队数据集,包含用户与LLM的对话记录,并标注对话是否产生有害信息。2) 计算每个对话的对话长度(CL),即对话轮数。3) 使用参考LLM估计用户指令序列的柯尔莫哥洛夫复杂度,作为对话复杂度(CC)的近似。4) 对比分析有害对话和无害对话的CL和CC的统计分布。5) 通过最小化CC,寻找更容易诱导LLM产生有害信息的攻击路径。
关键创新:论文最重要的技术创新点在于提出了对话复杂度(CC)的概念,并使用参考LLM来近似计算柯尔莫哥洛夫复杂度。这使得量化攻击路径的复杂度成为可能,从而更全面地评估LLM的安全性。与现有方法相比,该方法不仅关注是否能成功攻击LLM,更关注攻击的难度,从而更准确地反映LLM的真实安全水平。
关键设计:论文的关键设计包括:1) 使用参考LLM(不同于被评估的LLM)来估计柯尔莫哥洛夫复杂度,以避免循环依赖。2) 使用可压缩性作为柯尔莫哥洛夫复杂度的近似,因为可压缩性与柯尔莫哥洛夫复杂度密切相关。3) 通过统计分析CL和CC的分布,揭示LLM对不同复杂度的攻击的抵抗能力。具体的参数设置和损失函数取决于所使用的参考LLM和红队数据集。
🖼️ 关键图片
📊 实验亮点
论文通过对大型红队数据集的分析,发现有害对话的对话长度和复杂度通常低于无害对话。这表明,即使是先进的LLM,也可能容易受到相对简单的攻击。通过最小化对话复杂度,可以更容易地找到诱导LLM产生有害信息的攻击路径。这些发现为LLM的安全评估提供了新的视角。
🎯 应用场景
该研究成果可应用于LLM的安全评估和风险管理。开发者可以利用对话复杂度的分析,识别LLM中潜在的漏洞,并针对性地加强安全措施。监管机构可以利用该方法评估LLM的安全性,制定更有效的监管政策。此外,该方法还可以用于红队测试,帮助安全研究人员发现新的攻击路径。
📄 摘要(原文)
Large Language Models (LLMs) present a dual-use dilemma: they enable beneficial applications while harboring potential for harm, particularly through conversational interactions. Despite various safeguards, advanced LLMs remain vulnerable. A watershed case in early 2023 involved journalist Kevin Roose's extended dialogue with Bing, an LLM-powered search engine, which revealed harmful outputs after probing questions, highlighting vulnerabilities in the model's safeguards. This contrasts with simpler early jailbreaks, like the "Grandma Jailbreak," where users framed requests as innocent help for a grandmother, easily eliciting similar content. This raises the question: How much conversational effort is needed to elicit harmful information from LLMs? We propose two measures to quantify this effort: Conversational Length (CL), which measures the number of conversational turns needed to obtain a specific harmful response, and Conversational Complexity (CC), defined as the Kolmogorov complexity of the user's instruction sequence leading to the harmful response. To address the incomputability of Kolmogorov complexity, we approximate CC using a reference LLM to estimate the compressibility of the user instructions. Applying this approach to a large red-teaming dataset, we perform a quantitative analysis examining the statistical distribution of harmful and harmless conversational lengths and complexities. Our empirical findings suggest that this distributional analysis and the minimization of CC serve as valuable tools for understanding AI safety, offering insights into the accessibility of harmful information. This work establishes a foundation for a new perspective on LLM safety, centered around the algorithmic complexity of pathways to harm.