Co-Learning: Code Learning for Multi-Agent Reinforcement Collaborative Framework with Conversational Natural Language Interfaces
作者: Jiapeng Yu, Yuqian Wu, Yajing Zhan, Wenhao Guo, Zhou Xu, Raymond Lee
分类: cs.SE, cs.AI, cs.CL
发布日期: 2024-09-02
备注: 12 pages, 8 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出Co-Learning框架,利用多智能体强化学习提升代码错误自动纠正的效率和准确率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 强化学习 代码纠错 大型语言模型 在线编程教育
📋 核心要点
- 现有在线问答系统在代码纠错方面效率和准确率有待提升,难以满足专业需求。
- Co-Learning框架利用多智能体协作,结合环境强化学习,动态选择最优LLM智能体进行代码纠错。
- 实验表明,Co-Learning框架在代码纠错精度和时间效率上均优于传统方法,具有实际应用价值。
📝 摘要(中文)
本文提出了一种名为Co-Learning的代码学习社区多智能体框架,该框架结合了环境强化学习(E-RL),旨在帮助初学者独立纠正代码错误。该框架使用包含702个错误代码的原始数据集评估多个大型语言模型(LLM)的性能,并将其作为E-RL的奖励或惩罚标准。通过分析当前智能体输入的错误代码,选择合适的基于LLM的智能体,以实现最佳的错误纠正准确率并减少纠正时间。实验结果表明,与没有E-RL的方法相比,精度提高了3%,时间成本降低了15%。源代码可在https://github.com/yuqian2003/Co_Learning获取。
🔬 方法详解
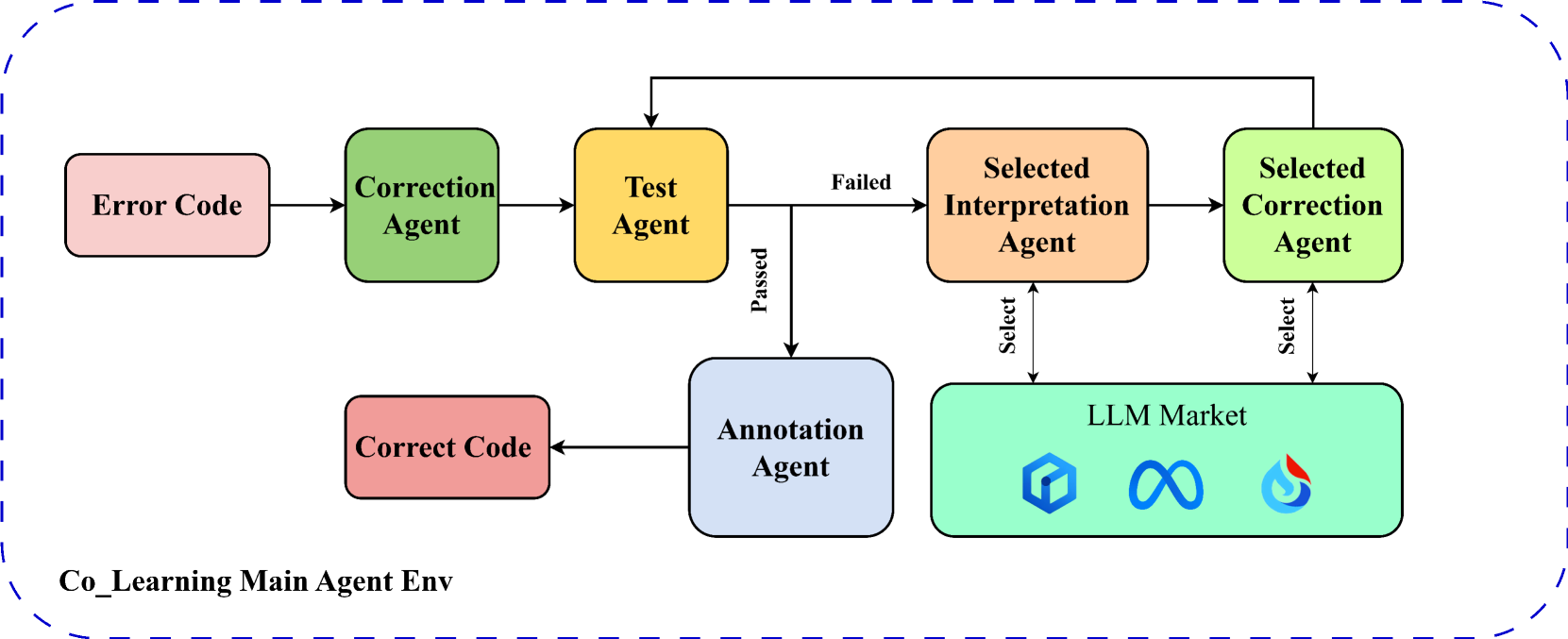
问题定义:论文旨在解决初学者在代码编写过程中遇到的错误难以高效、准确纠正的问题。现有方法,特别是基于单一大型语言模型(LLM)的纠错方案,可能无法针对不同类型的错误代码达到最佳性能,且纠错时间较长。
核心思路:论文的核心思路是构建一个多智能体系统,每个智能体基于不同的LLM,并利用环境强化学习(E-RL)动态选择最适合当前错误代码的智能体。通过E-RL,系统能够学习不同LLM在不同类型错误上的表现,从而优化整体纠错效果。
技术框架:Co-Learning框架包含以下主要模块:1) 错误代码输入模块:接收用户提交的错误代码。2) 智能体选择模块:基于E-RL算法,根据当前错误代码的特征选择合适的LLM智能体。3) LLM智能体模块:每个智能体基于不同的LLM,负责生成纠正后的代码。4) 评估模块:评估纠正后代码的质量,并将其作为E-RL的奖励或惩罚信号。5) E-RL训练模块:利用评估结果更新智能体选择策略。
关键创新:该论文的关键创新在于将多智能体系统与环境强化学习相结合,实现了代码纠错智能体的动态选择。与传统的单一LLM方法相比,Co-Learning框架能够根据错误代码的特点,选择最合适的LLM进行纠错,从而提高纠错准确率和效率。
关键设计:论文使用包含702个错误代码的原始数据集训练和评估模型。E-RL算法的具体实现细节(例如,状态表示、动作空间、奖励函数、强化学习算法选择)在论文中没有详细说明,属于未知信息。论文中提到使用LLM的性能作为E-RL的奖励或惩罚标准,但具体如何量化LLM的性能也属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,与没有E-RL的方法相比,Co-Learning框架在代码纠错精度上提高了3%,时间成本降低了15%。这表明该框架能够有效地选择合适的LLM智能体,从而提高纠错效率和准确率。
🎯 应用场景
Co-Learning框架可应用于在线编程教育平台、代码审查工具和集成开发环境(IDE)等领域,帮助初学者快速定位和纠正代码错误,提高编程效率和学习效果。该框架还可扩展到其他类型的代码错误,具有广泛的应用前景。
📄 摘要(原文)
Online question-and-answer (Q\&A) systems based on the Large Language Model (LLM) have progressively diverged from recreational to professional use. This paper proposed a Multi-Agent framework with environmentally reinforcement learning (E-RL) for code correction called Code Learning (Co-Learning) community, assisting beginners to correct code errors independently. It evaluates the performance of multiple LLMs from an original dataset with 702 error codes, uses it as a reward or punishment criterion for E-RL; Analyzes input error codes by the current agent; selects the appropriate LLM-based agent to achieve optimal error correction accuracy and reduce correction time. Experiment results showed that 3\% improvement in Precision score and 15\% improvement in time cost as compared with no E-RL method respectively. Our source code is available at: https://github.com/yuqian2003/Co_Learning