Evaluating the Performance of Large Language Models in Competitive Programming: A Multi-Year, Multi-Grade Analysis
作者: Adrian Marius Dumitran, Adrian Catalin Badea, Stefan-Gabriel Muscalu
分类: cs.SE, cs.AI, cs.PL
发布日期: 2024-08-31
备注: 7 pages, Inista 2024
💡 一句话要点
多年度多级别分析:评估大型语言模型在编程竞赛中的表现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 编程竞赛 代码生成 性能评估 教育应用
📋 核心要点
- 现有方法难以系统评估LLM在复杂编程问题解决中的能力,尤其缺乏针对竞赛场景的深入分析。
- 核心思路是构建一个包含多年度、多级别竞赛题目的数据集,并采用标准化的评估流程分析LLM的表现。
- 实验结果表明,不同LLM在不同年级和问题类型上表现差异显著,GPT-4在中学生问题上表现出潜力。
📝 摘要(中文)
本研究探讨了大型语言模型(LLM)在解决罗马尼亚信息学奥林匹克竞赛县级水平的编程问题中的表现。罗马尼亚是计算机科学竞赛领域的领先国家,其悠久的历史和严格的竞赛标准为评估LLM的能力提供了理想的环境。我们收集并分析了2002年至2023年的304个挑战的数据集,重点关注LLM用C++和Python编写的解决方案。我们的主要目标是了解LLM在不同任务上的表现优异或不佳的原因。我们使用标准化的流程(包括多次尝试和反馈)评估了各种模型,包括GPT-4等闭源模型以及CodeLlama和RoMistral等开源模型。分析表明,LLM在不同年级和问题类型上的表现存在显著差异。值得注意的是,GPT-4表现出强大的性能,表明其有潜力作为中学生的教育工具。我们还观察到各种LLM在代码质量和风格上的差异。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在解决罗马尼亚信息学奥林匹克竞赛县级水平编程问题上的能力。现有方法缺乏对LLM在竞赛编程场景下的系统性评估,难以深入了解LLM在不同难度级别和问题类型上的表现瓶颈。
核心思路:论文的核心思路是构建一个包含多年份、多级别竞赛题目的数据集,并采用标准化的评估流程,对不同LLM生成的代码进行测试和分析。通过分析LLM在不同问题上的表现,揭示其优势和不足,从而为LLM在教育领域的应用提供参考。
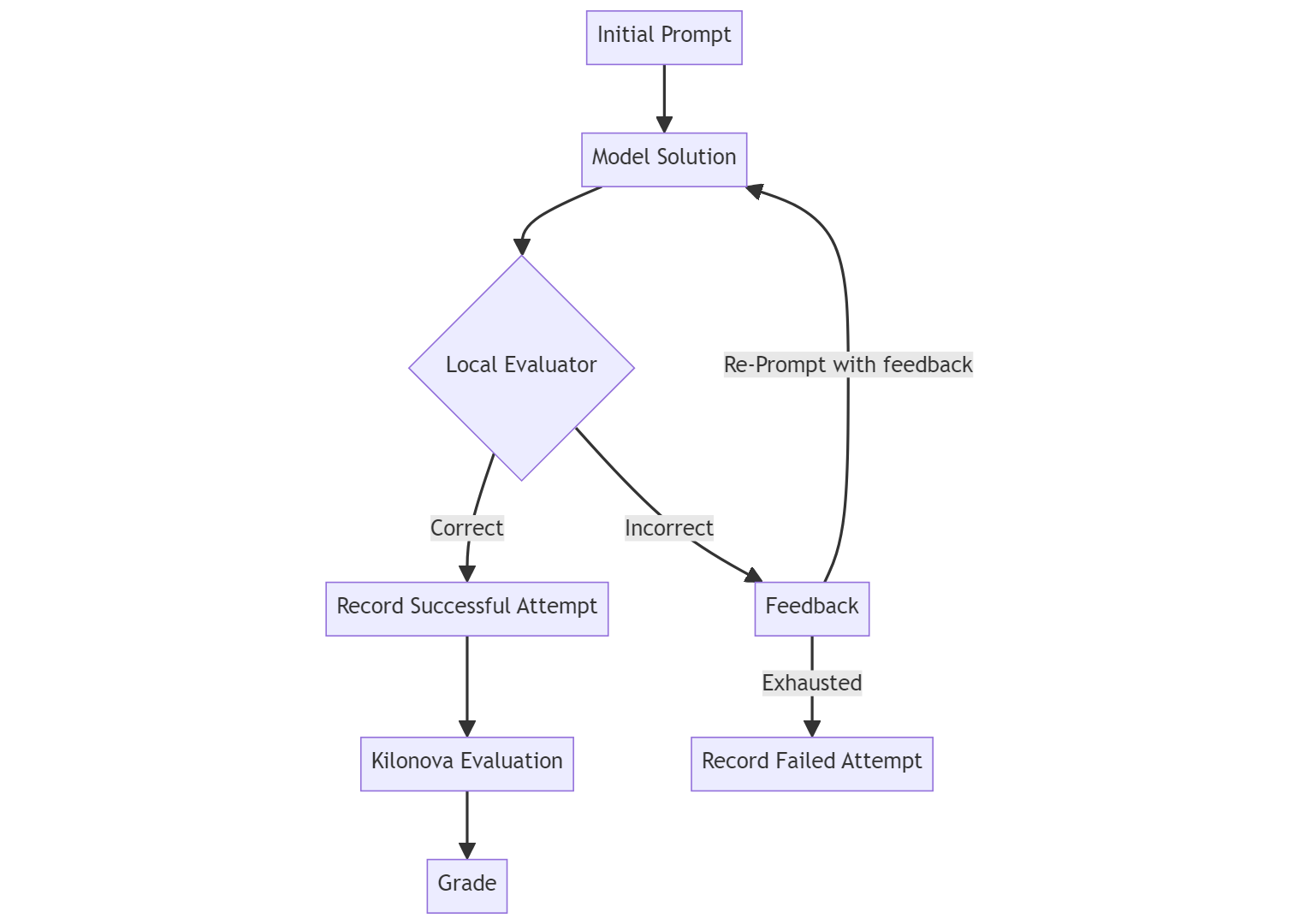
技术框架:整体流程包括以下几个阶段:1) 数据收集:收集2002年至2023年罗马尼亚信息学奥林匹克竞赛县级水平的304个编程题目。2) 代码生成:使用不同的LLM(如GPT-4、CodeLlama、RoMistral)生成C++和Python代码。3) 标准化评估:采用标准化的测试流程,包括多次尝试和反馈,评估LLM生成的代码的正确性。4) 结果分析:分析LLM在不同年级和问题类型上的表现,并比较不同LLM的代码质量和风格。
关键创新:论文的关键创新在于:1) 构建了一个专门用于评估LLM在竞赛编程场景下表现的数据集。2) 采用标准化的评估流程,保证了评估结果的客观性和可比性。3) 对LLM在不同年级和问题类型上的表现进行了深入分析,揭示了其优势和不足。
关键设计:论文的关键设计包括:1) 数据集的选择:选择罗马尼亚信息学奥林匹克竞赛县级水平的题目,保证了题目的难度和区分度。2) 评估流程的设计:采用多次尝试和反馈的机制,提高了评估的准确性。3) 模型选择:选择了具有代表性的闭源模型(GPT-4)和开源模型(CodeLlama、RoMistral),以便进行比较分析。
🖼️ 关键图片
📊 实验亮点
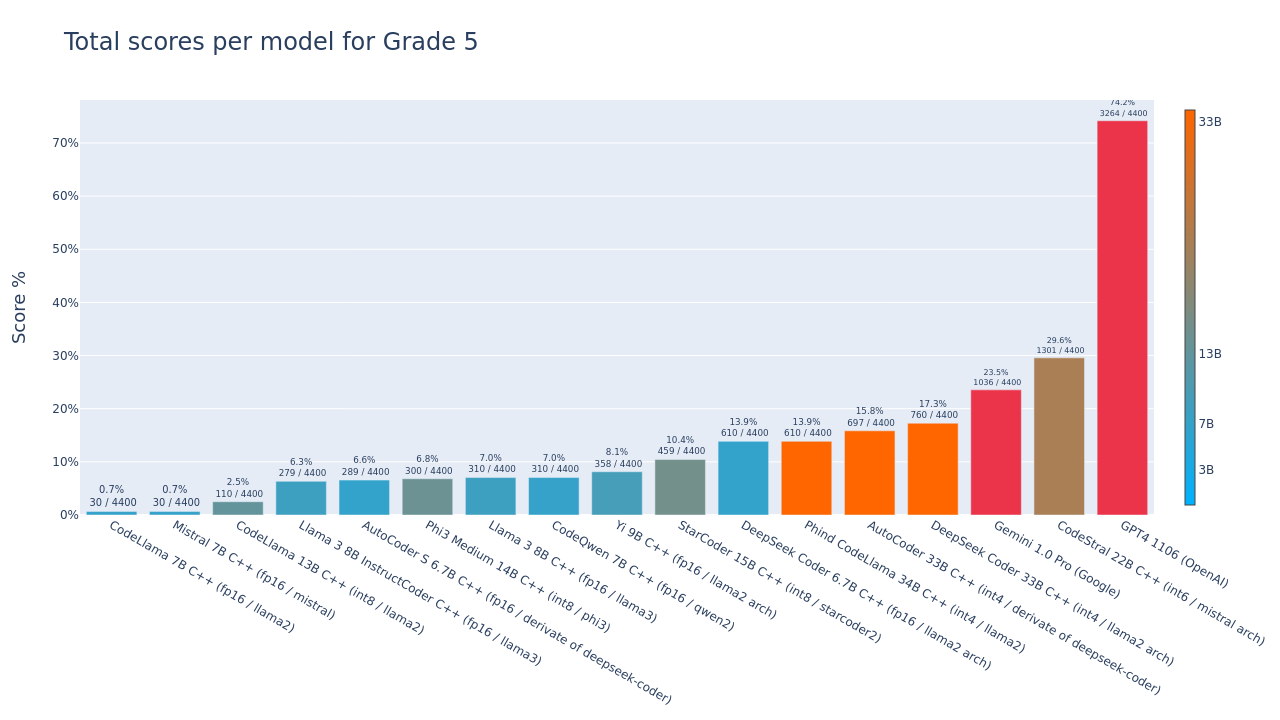
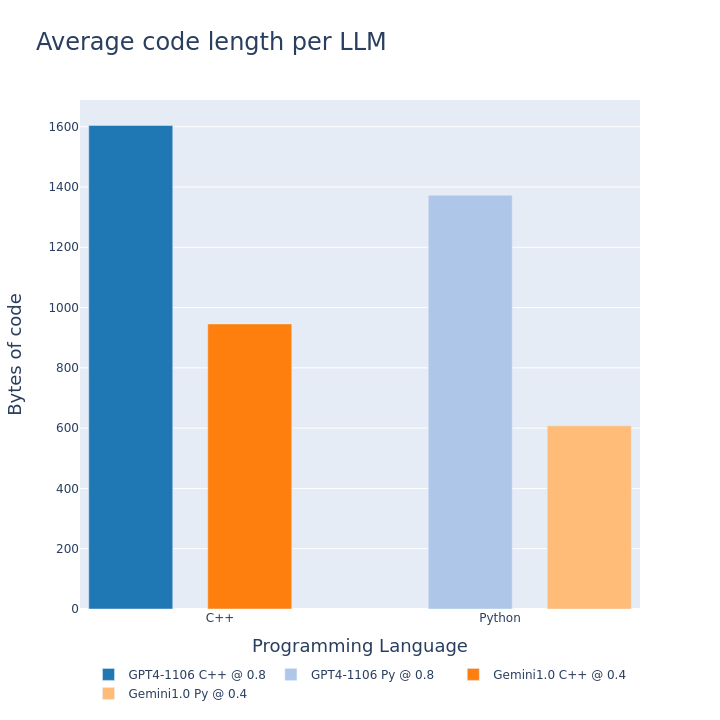
实验结果表明,GPT-4在解决中学生编程问题上表现出强大的性能,表明其有潜力作为教育工具。此外,研究还观察到不同LLM在代码质量和风格上的差异,为选择合适的LLM提供了参考依据。具体性能数据未在摘要中给出,需要查阅原文。
🎯 应用场景
该研究的潜在应用领域包括:1) 辅助编程教育:利用LLM的编程能力,为学生提供个性化的编程辅导和练习。2) 自动化代码生成:在特定领域,利用LLM自动生成代码,提高开发效率。3) 竞赛训练:帮助选手更好地理解和解决编程竞赛问题。未来的影响在于推动LLM在教育和软件开发领域的应用。
📄 摘要(原文)
This study explores the performance of large language models (LLMs) in solving competitive programming problems from the Romanian Informatics Olympiad at the county level. Romania, a leading nation in computer science competitions, provides an ideal environment for evaluating LLM capabilities due to its rich history and stringent competition standards. We collected and analyzed a dataset comprising 304 challenges from 2002 to 2023, focusing on solutions written by LLMs in C++ and Python for these problems. Our primary goal is to understand why LLMs perform well or poorly on different tasks. We evaluated various models, including closed-source models like GPT-4 and open-weight models such as CodeLlama and RoMistral, using a standardized process involving multiple attempts and feedback rounds. The analysis revealed significant variations in LLM performance across different grades and problem types. Notably, GPT-4 showed strong performance, indicating its potential use as an educational tool for middle school students. We also observed differences in code quality and style across various LLMs