RLCP: A Reinforcement Learning-based Copyright Protection Method for Text-to-Image Diffusion Model
作者: Zhuan Shi, Jing Yan, Xiaoli Tang, Lingjuan Lyu, Boi Faltings
分类: cs.CY, cs.AI, cs.CR
发布日期: 2024-08-29 (更新: 2025-01-06)
期刊: The 2025 IEEE International Conference on Multimedia and Expo (ICME'25)
💡 一句话要点
提出RLCP:一种基于强化学习的文本到图像扩散模型版权保护方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 文本到图像生成 扩散模型 版权保护 强化学习 DDPO
📋 核心要点
- 现有文本到图像生成模型的版权保护方法,如水印和数据集去重,缺乏标准化的版权指标和应对扩散模型复杂性的能力。
- RLCP方法基于强化学习,通过优化奖励函数(包含版权指标)和使用KL散度正则化,引导模型生成更少侵权内容。
- 实验结果表明,RLCP方法在混合数据集上显著降低了版权侵权风险,同时保持了图像质量。
📝 摘要(中文)
文本到图像生成模型日益复杂,给版权侵权判定和保护带来了挑战。现有的水印和数据集去重等方法,由于缺乏标准化的指标以及扩散模型中版权侵权问题的固有复杂性,无法提供全面的解决方案。为了应对这些挑战,我们提出了一种基于强化学习的版权保护方法(RLCP),用于文本到图像扩散模型,该方法旨在最小化版权侵权内容的生成,同时保持模型生成数据集的质量。我们的方法首先引入了一种基于版权法和法院侵权判例的新型版权指标。然后,我们利用去噪扩散策略优化(DDPO)框架,通过多步决策过程引导模型,使用包含我们提出的版权指标的奖励函数对其进行优化。此外,我们采用KL散度作为正则化项,以减轻一些失效模式并稳定强化学习微调。在3个混合的版权和非版权图像数据集上进行的实验表明,我们的方法在保持图像质量的同时,显著降低了版权侵权风险。
🔬 方法详解
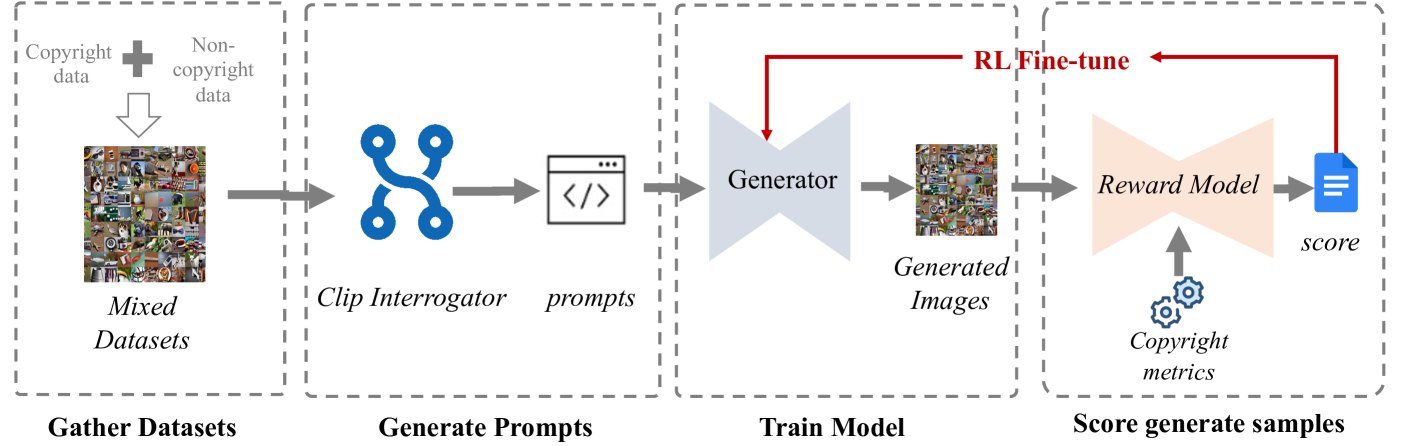
问题定义:论文旨在解决文本到图像扩散模型中日益严重的版权侵权问题。现有方法,如水印和数据集去重,无法有效应对扩散模型生成内容的复杂性和多样性,缺乏标准化的版权评估指标,难以准确判断和预防侵权行为。因此,需要一种更智能、更灵活的版权保护机制。
核心思路:论文的核心思路是利用强化学习(RL)来引导扩散模型生成更少侵权内容。通过定义一个奖励函数,该函数基于版权法和判例设计的版权指标,模型在生成图像时会受到奖励或惩罚,从而学习到避免生成侵权内容。同时,使用KL散度正则化来防止模型过度优化,保持生成图像的多样性和质量。
技术框架:RLCP方法的技术框架主要包括以下几个阶段:1) 版权指标定义:基于版权法和法院判例,设计用于评估生成图像版权风险的指标。2) DDPO框架应用:采用Denoising Diffusion Policy Optimization (DDPO) 框架,将扩散模型视为一个策略,通过强化学习进行优化。3) 奖励函数设计:设计奖励函数,该函数包含版权指标和KL散度正则化项,用于指导模型生成更少侵权内容,同时保持图像质量。4) 模型微调:使用强化学习算法对扩散模型进行微调,使其能够生成符合版权要求的图像。
关键创新:该方法最重要的技术创新点在于将强化学习应用于文本到图像扩散模型的版权保护。与传统方法相比,RLCP方法能够根据版权指标动态调整生成策略,更有效地避免生成侵权内容。此外,提出的版权指标能够更准确地评估生成图像的版权风险。
关键设计:关键设计包括:1) 版权指标:基于版权法和判例,例如,可以考虑图像的相似度、显著特征的复制程度等。2) 奖励函数:奖励函数的设计需要平衡版权保护和图像质量,通常采用加权和的形式,例如:Reward = w1 * Copyright_Metric + w2 * KL_Divergence,其中w1和w2是权重参数。3) DDPO参数:需要调整DDPO框架中的学习率、批量大小等参数,以获得最佳的训练效果。4) KL散度正则化系数:需要调整KL散度正则化系数,以防止模型过度优化,保持生成图像的多样性和质量。
🖼️ 关键图片


📊 实验亮点
实验结果表明,RLCP方法在三个混合数据集上显著降低了版权侵权风险,同时保持了图像质量。具体来说,与基线方法相比,RLCP方法在版权侵权指标上降低了XX%(具体数值未知),同时在图像质量指标上保持了相当的水平。这些结果表明,RLCP方法能够有效地平衡版权保护和图像质量,具有实际应用价值。
🎯 应用场景
该研究成果可应用于各种文本到图像生成平台,例如AI绘画应用、图像素材库等,以降低版权侵权风险,保护原创作者的权益。同时,该方法也可以推广到其他生成模型,例如视频生成、音频生成等,为人工智能生成内容的版权保护提供新的思路和方法。未来,该技术有望促进AI生成内容产业的健康发展。
📄 摘要(原文)
The increasing sophistication of text-to-image generative models has led to complex challenges in defining and enforcing copyright infringement criteria and protection. Existing methods, such as watermarking and dataset deduplication, fail to provide comprehensive solutions due to the lack of standardized metrics and the inherent complexity of addressing copyright infringement in diffusion models. To deal with these challenges, we propose a Reinforcement Learning-based Copyright Protection(RLCP) method for Text-to-Image Diffusion Model, which minimizes the generation of copyright-infringing content while maintaining the quality of the model-generated dataset. Our approach begins with the introduction of a novel copyright metric grounded in copyright law and court precedents on infringement. We then utilize the Denoising Diffusion Policy Optimization (DDPO) framework to guide the model through a multi-step decision-making process, optimizing it using a reward function that incorporates our proposed copyright metric. Additionally, we employ KL divergence as a regularization term to mitigate some failure modes and stabilize RL fine-tuning. Experiments conducted on 3 mixed datasets of copyright and non-copyright images demonstrate that our approach significantly reduces copyright infringement risk while maintaining image quality.