Examination of Code generated by Large Language Models
作者: Robin Beer, Alexander Feix, Tim Guttzeit, Tamara Muras, Vincent Müller, Maurice Rauscher, Florian Schäffler, Welf Löwe
分类: cs.SE, cs.AI
发布日期: 2024-08-29
💡 一句话要点
评估大型语言模型生成的代码质量与正确性,揭示不同模型、语言和时间的影响。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 代码生成 软件开发 代码质量评估 单元测试
📋 核心要点
- 大型语言模型在代码生成方面展现潜力,但其生成代码的正确性和质量仍需严格评估。
- 通过受控实验,对比分析ChatGPT和Copilot在生成Java和Python代码及单元测试时的表现。
- 实验结果揭示了不同LLM、编程语言以及时间推移对代码质量和正确性的影响。
📝 摘要(中文)
大型语言模型(LLMs),如ChatGPT和Copilot,正在通过自动化代码生成来改变软件开发,从而加速原型设计、支持教育并提高生产力。因此,生成的代码的正确性和质量应与手动编写的代码相当。为了评估LLMs在生成高质量正确代码方面的现状,我们对ChatGPT和Copilot进行了受控实验:我们让LLMs生成Java和Python中的简单算法以及相应的单元测试,并评估生成的(测试)代码的正确性和质量(覆盖率)。我们观察到LLMs之间、语言之间、算法和测试代码之间以及随时间推移的显著差异。本文报告了这些结果以及实验方法,这些方法允许对更多算法、语言和LLMs进行重复和可比较的评估。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLMs)自动生成的代码的质量和正确性。现有方法缺乏对不同LLM、编程语言和时间因素的系统性对比评估,无法全面了解LLM代码生成能力的现状和潜在问题。
核心思路:论文的核心思路是通过设计受控实验,让LLMs生成特定算法的Java和Python代码以及相应的单元测试,然后评估生成代码的正确性和测试覆盖率。通过对比不同LLM、语言和时间点的实验结果,揭示LLM代码生成能力的差异和演变趋势。
技术框架:该研究采用实验评估方法,主要包含以下几个阶段:1) 选择ChatGPT和Copilot作为评估对象;2) 选取一组简单的算法作为代码生成任务;3) 指示LLMs生成Java和Python代码以及对应的单元测试;4) 运行生成的单元测试,评估代码的正确性和测试覆盖率;5) 分析实验结果,对比不同LLM、语言和时间点之间的差异。
关键创新:该研究的关键创新在于其系统性的实验评估方法,能够对LLM生成的代码进行量化评估,并揭示不同因素对代码质量的影响。该方法为后续研究提供了可重复和可比较的评估框架。
关键设计:实验中,算法的选择需要保证其简单性,以便于评估代码的正确性。测试覆盖率的评估需要选择合适的工具和指标。实验结果的分析需要采用统计方法,以确保结论的可靠性。论文未明确提及具体的参数设置、损失函数或网络结构,因为其重点在于实验评估而非模型设计。
🖼️ 关键图片
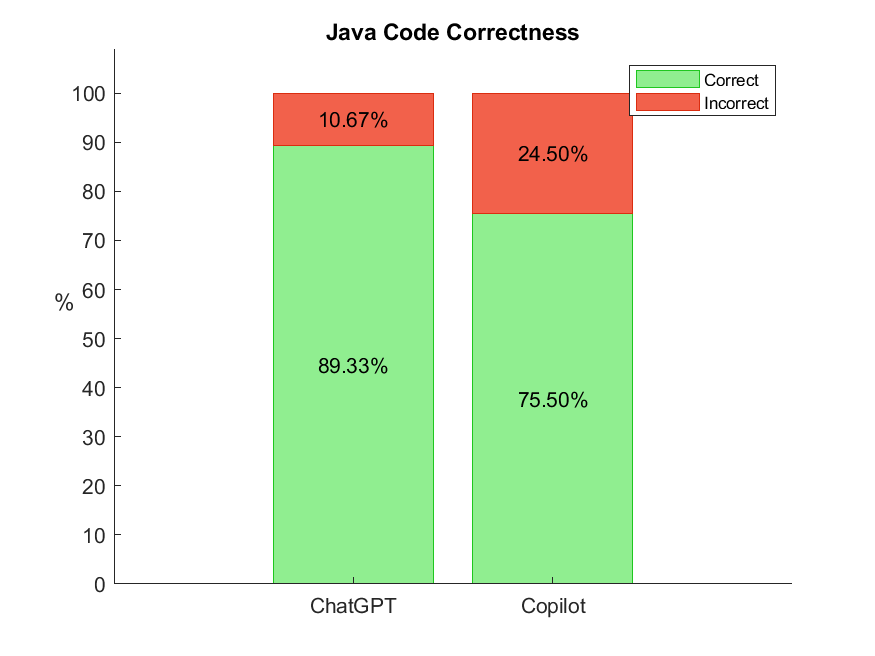


📊 实验亮点
实验结果表明,ChatGPT和Copilot在代码生成能力上存在显著差异。不同编程语言(Java和Python)的代码生成质量也存在差异。此外,随着时间的推移,LLM的代码生成能力也可能发生变化。具体的性能数据和提升幅度在摘要中未明确给出,需要在论文正文中查找。
🎯 应用场景
该研究成果可应用于软件开发工具的改进、代码自动生成技术的优化以及程序员教育的提升。通过了解LLM代码生成能力的优势和局限性,可以更好地利用LLM来提高软件开发效率和质量,并为程序员提供更有效的辅助工具。此外,该研究也为评估其他代码生成模型的性能提供了参考。
📄 摘要(原文)
Large language models (LLMs), such as ChatGPT and Copilot, are transforming software development by automating code generation and, arguably, enable rapid prototyping, support education, and boost productivity. Therefore, correctness and quality of the generated code should be on par with manually written code. To assess the current state of LLMs in generating correct code of high quality, we conducted controlled experiments with ChatGPT and Copilot: we let the LLMs generate simple algorithms in Java and Python along with the corresponding unit tests and assessed the correctness and the quality (coverage) of the generated (test) codes. We observed significant differences between the LLMs, between the languages, between algorithm and test codes, and over time. The present paper reports these results together with the experimental methods allowing repeated and comparable assessments for more algorithms, languages, and LLMs over time.