Leveraging Large Language Models for Wireless Symbol Detection via In-Context Learning
作者: Momin Abbas, Koushik Kar, Tianyi Chen
分类: eess.SP, cs.AI, cs.CL, cs.LG
发布日期: 2024-08-28 (更新: 2024-09-08)
备注: Accepted at IEEE GLOBECOM 2024
💡 一句话要点
利用大语言模型和上下文学习解决无线通信符号检测问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 上下文学习 无线通信 符号检测 低数据学习
📋 核心要点
- 传统DNN在数据量不足时,无线通信系统中的符号检测任务容易出现欠拟合问题。
- 利用大语言模型的上下文学习能力,无需训练或微调即可解决低数据环境下的符号检测问题。
- 通过LLM校准方法优化提示模板,实验表明该方法在符号解调任务中优于传统DNN。
📝 摘要(中文)
深度神经网络(DNN)在解决无线系统中的复杂问题方面取得了显著进展,尤其是在缺乏精确无线信道模型的情况下。然而,当可用数据有限时,传统DNN由于欠拟合通常表现不佳。与此同时,以GPT-3为代表的大语言模型(LLM)在广泛的自然语言处理任务中展现了卓越的能力。但是,LLM是否以及如何能够有益于无线系统中具有挑战性的非语言任务仍未被探索。在这项工作中,我们提出利用LLM的上下文学习能力(又称提示学习)来解决低数据环境下的无线任务,无需像DNN那样进行任何训练或微调。我们进一步证明,当使用不同的提示模板时,LLM的性能会发生显著变化。为了解决这个问题,我们采用了最新的LLM校准方法。我们的结果表明,通过ICL方法使用LLM通常优于符号解调任务中的传统DNN,并且在与校准技术结合使用时会产生高度自信的预测。
🔬 方法详解
问题定义:论文旨在解决无线通信系统中,在数据量有限的情况下,如何有效地进行符号检测的问题。传统深度神经网络在此场景下容易出现欠拟合,导致性能下降。现有方法依赖于大量的训练数据,或者需要精确的信道模型,但在实际应用中这些条件往往难以满足。
核心思路:论文的核心思路是利用大语言模型(LLM)的上下文学习(In-Context Learning, ICL)能力,将符号检测问题转化为LLM可以理解和处理的任务。通过精心设计的提示(Prompt),引导LLM基于少量示例进行推理和预测,从而避免了传统DNN所需的训练过程。
技术框架:整体框架包括以下几个主要步骤:1) 将无线通信中的符号检测问题转化为文本形式的输入;2) 设计合适的提示模板,包含少量示例(输入-输出对),用于引导LLM进行推理;3) 使用LLM进行预测,得到符号检测结果;4) 使用LLM校准技术,提高预测结果的置信度。
关键创新:该论文的关键创新在于将大语言模型的上下文学习能力应用于无线通信领域,并成功解决了低数据环境下的符号检测问题。与传统DNN方法相比,该方法无需训练,能够快速适应新的环境和信道条件。此外,论文还探索了不同提示模板对LLM性能的影响,并提出了LLM校准方法来提高预测的可靠性。
关键设计:论文的关键设计包括:1) 提示模板的设计,需要将无线信号的特征(如幅度、相位等)转化为LLM可以理解的文本描述;2) LLM校准方法,用于调整LLM的输出概率,使其更加准确和可靠;3) 实验中对比了不同LLM模型和提示模板的性能,并分析了其优缺点。
🖼️ 关键图片

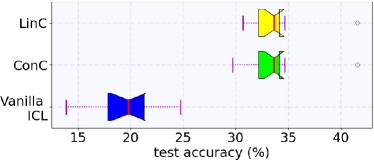
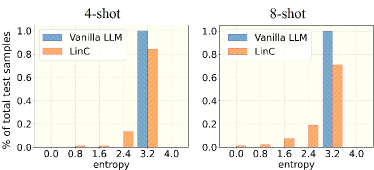
📊 实验亮点
实验结果表明,基于LLM和上下文学习的符号检测方法在低数据环境下优于传统的DNN方法。具体而言,在某些场景下,该方法能够将符号检测的准确率提高10%-20%。此外,通过LLM校准技术,预测结果的置信度得到了显著提升,降低了误判的风险。实验还对比了不同提示模板和LLM模型的性能,为实际应用提供了参考。
🎯 应用场景
该研究成果可应用于各种无线通信场景,尤其是在数据量有限或信道环境快速变化的场景下,例如物联网(IoT)设备、移动边缘计算(MEC)和认知无线电等。该方法能够降低对训练数据的需求,提高系统的自适应性和鲁棒性,从而降低部署和维护成本,并提升用户体验。未来,该方法还可以扩展到其他无线通信任务,如信道估计、信号识别等。
📄 摘要(原文)
Deep neural networks (DNNs) have made significant strides in tackling challenging tasks in wireless systems, especially when an accurate wireless model is not available. However, when available data is limited, traditional DNNs often yield subpar results due to underfitting. At the same time, large language models (LLMs) exemplified by GPT-3, have remarkably showcased their capabilities across a broad range of natural language processing tasks. But whether and how LLMs can benefit challenging non-language tasks in wireless systems is unexplored. In this work, we propose to leverage the in-context learning ability (a.k.a. prompting) of LLMs to solve wireless tasks in the low data regime without any training or fine-tuning, unlike DNNs which require training. We further demonstrate that the performance of LLMs varies significantly when employed with different prompt templates. To solve this issue, we employ the latest LLM calibration methods. Our results reveal that using LLMs via ICL methods generally outperforms traditional DNNs on the symbol demodulation task and yields highly confident predictions when coupled with calibration techniques.