Atari-GPT: Benchmarking Multimodal Large Language Models as Low-Level Policies in Atari Games
作者: Nicholas R. Waytowich, Devin White, MD Sunbeam, Vinicius G. Goecks
分类: cs.AI
发布日期: 2024-08-28 (更新: 2024-12-02)
备注: Currently under review
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
Atari-GPT:评估多模态大语言模型在Atari游戏中作为底层策略的性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 Atari游戏 底层控制策略 零样本学习 强化学习 视觉推理 空间推理
📋 核心要点
- 现有强化学习方法在Atari游戏中需要针对每个环境和奖励函数进行训练,泛化能力弱。
- 本研究探索多模态大语言模型作为Atari游戏的底层策略,利用其预训练的多模态知识直接与环境交互。
- 实验结果表明,当前的多模态大语言模型在零样本底层策略方面表现不佳,视觉和空间推理能力是瓶颈。
📝 摘要(中文)
近年来,大型语言模型(LLM)的能力已扩展到传统文本任务之外的多模态领域,集成了视觉、听觉和文本数据。虽然多模态LLM已在机器人和游戏等领域的高级规划中得到广泛探索,但它们作为底层控制器的潜力在很大程度上尚未开发。本文介绍了一种新的基准,旨在测试多模态LLM在Atari游戏中作为底层策略的新兴能力。与需要针对每个新环境和奖励函数规范进行训练的传统强化学习(RL)方法不同,这些LLM利用预先存在的多模态知识直接与游戏环境交互。我们的研究评估了多个多模态LLM相对于传统RL智能体、人类玩家和随机智能体的性能,重点关注它们理解复杂视觉场景并制定战略响应的能力。结果表明,这些多模态LLM尚未能作为零样本底层策略。此外,我们发现这部分是由于它们的视觉和空间推理能力不足。更多结果和视频可在我们的项目网页上找到:https://dev1nw.github.io/atari-gpt/。
🔬 方法详解
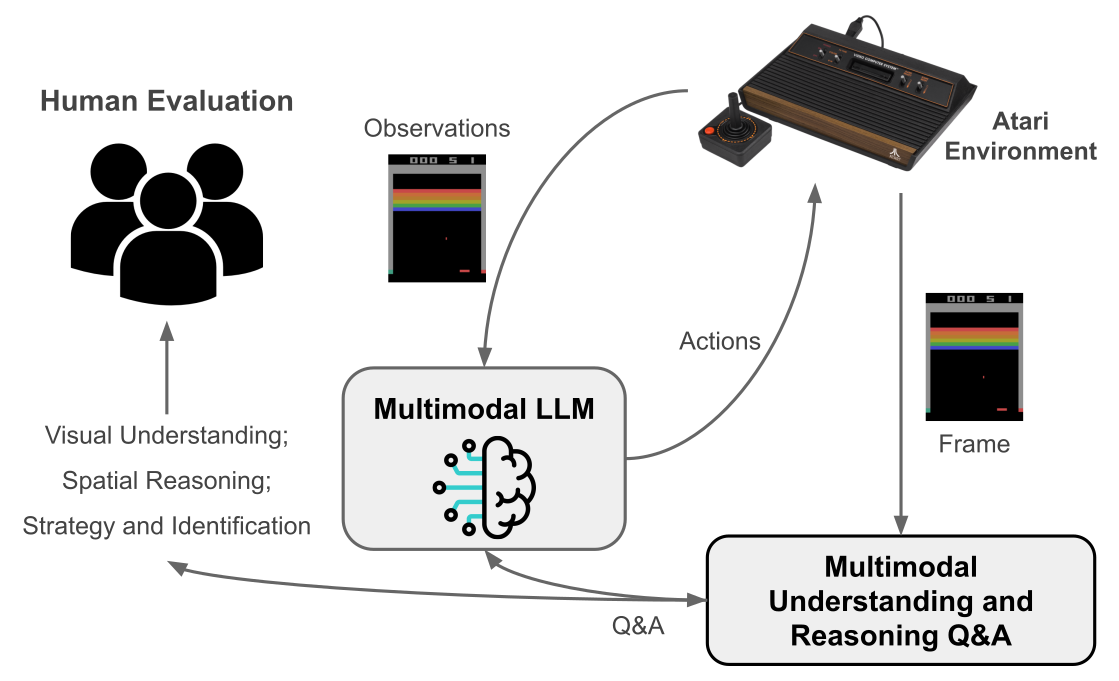
问题定义:论文旨在评估多模态大语言模型(MLLM)在Atari游戏中作为底层控制策略的有效性。现有强化学习方法需要针对每个游戏环境进行单独训练,缺乏通用性和泛化能力。MLLM拥有预训练的多模态知识,有望直接应用于新的游戏环境,实现零样本控制,但其在低层控制方面的潜力尚未被充分探索。
核心思路:论文的核心思路是利用MLLM的视觉理解和语言推理能力,将其直接应用于Atari游戏环境,无需额外的训练。通过将游戏画面作为输入,MLLM生成相应的游戏控制指令,从而实现与环境的交互。这种方法旨在利用MLLM的通用知识,克服传统强化学习方法对特定环境的依赖。
技术框架:整体框架包括以下几个主要步骤:1)将Atari游戏画面作为MLLM的输入;2)MLLM根据画面内容生成游戏控制指令(例如,向上、向下、向左、向右、开火等);3)将控制指令发送给游戏环境,执行相应的动作;4)观察游戏环境的反馈(新的游戏画面和奖励);5)重复以上步骤,直到游戏结束。该框架的核心是MLLM,它负责理解游戏画面并生成合理的控制指令。
关键创新:论文的关键创新在于将MLLM应用于Atari游戏的底层控制,并将其作为一个零样本学习问题进行研究。与传统的强化学习方法不同,该方法不需要针对每个游戏环境进行训练,而是直接利用MLLM的预训练知识。此外,该研究还提出了一个评估MLLM在Atari游戏中性能的基准,为未来的研究提供了参考。
关键设计:论文中,MLLM接收游戏画面的像素数据作为输入,并输出离散的动作指令。具体的技术细节包括:选择合适的MLLM架构(例如,基于Transformer的模型),设计合适的输入格式(例如,将像素数据转换为图像嵌入),以及定义合适的输出格式(例如,将动作指令编码为文本)。此外,论文还可能涉及到一些超参数的调整,例如学习率、批量大小等。损失函数的设计可能涉及到模仿学习或强化学习的思想,例如,最小化MLLM生成的动作与人类玩家或专家智能体生成的动作之间的差异。
🖼️ 关键图片


📊 实验亮点
实验结果表明,当前的多模态大语言模型在Atari游戏中作为零样本底层策略的表现不如传统的强化学习智能体、人类玩家甚至随机智能体。这表明,虽然MLLM在高级规划方面表现出色,但在低层控制方面仍存在局限性,尤其是在视觉和空间推理方面。该研究强调了MLLM在理解复杂视觉场景和制定战略响应方面的不足,为未来的研究指明了方向。
🎯 应用场景
该研究的潜在应用领域包括游戏AI、机器人控制和自动化。通过利用多模态大语言模型的通用知识,可以开发出更加智能和灵活的控制系统,从而降低开发成本和提高效率。例如,可以将该方法应用于机器人导航和操作,使其能够更好地理解周围环境并执行复杂的任务。此外,该研究还可以促进多模态大语言模型在其他领域的应用,例如智能家居和自动驾驶。
📄 摘要(原文)
Recent advancements in large language models (LLMs) have expanded their capabilities beyond traditional text-based tasks to multimodal domains, integrating visual, auditory, and textual data. While multimodal LLMs have been extensively explored for high-level planning in domains like robotics and games, their potential as low-level controllers remains largely untapped. In this paper, we introduce a novel benchmark aimed at testing the emergent capabilities of multimodal LLMs as low-level policies in Atari games. Unlike traditional reinforcement learning (RL) methods that require training for each new environment and reward function specification, these LLMs utilize pre-existing multimodal knowledge to directly engage with game environments. Our study assesses the performances of multiple multimodal LLMs against traditional RL agents, human players, and random agents, focusing on their ability to understand and interact with complex visual scenes and formulate strategic responses. Our results show that these multimodal LLMs are not yet capable of being zero-shot low-level policies. Furthermore, we see that this is, in part, due to their visual and spatial reasoning. Additional results and videos are available on our project webpage: https://dev1nw.github.io/atari-gpt/.