ModalityMirror: Improving Audio Classification in Modality Heterogeneity Federated Learning with Multimodal Distillation
作者: Tiantian Feng, Tuo Zhang, Salman Avestimehr, Shrikanth S. Narayanan
分类: eess.AS, cs.AI, cs.SD
发布日期: 2024-08-28
💡 一句话要点
提出ModalityMirror以解决多模态联邦学习中的音频分类问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 联邦学习 知识蒸馏 音频分类 模态异质性 音视频分析 深度学习
📋 核心要点
- 现有的多模态联邦学习方法在客户端模态异质性方面存在挑战,导致音频分类性能不佳。
- 本文提出ModalityMirror,通过知识蒸馏提升音频模型性能,分为模态级联邦学习和联邦知识蒸馏两个阶段。
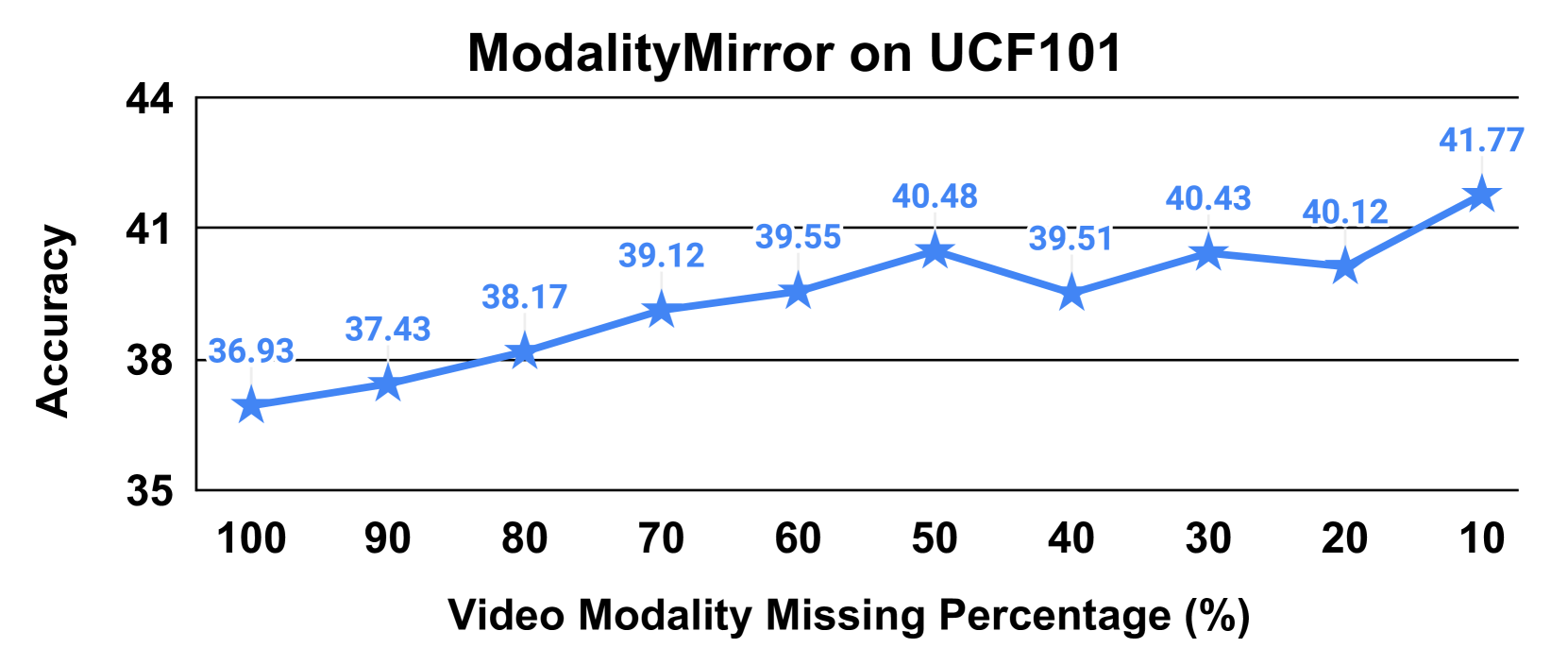
- 实验结果显示,ModalityMirror在音频分类上显著优于现有方法,尤其在视频缺失的情况下提升效果明显。
📝 摘要(中文)
多模态联邦学习常面临客户端模态异质性的问题,导致次要模态在多模态学习中的表现不佳,尤其在音视频学习中,音频通常被认为是识别任务中的弱模态。为了解决这一挑战,本文提出了ModalityMirror,通过从音视频联邦学习模型中进行知识蒸馏来提升音频模型的性能。ModalityMirror包括两个阶段:模态级联邦学习阶段用于聚合单模态编码器;以及在多模态客户端上进行的联邦知识蒸馏阶段,以训练单模态学生模型。实验结果表明,ModalityMirror在音频分类上显著优于现有的联邦学习方法,如Harmony,尤其是在面对视频缺失的音视频联邦学习中。该方法释放了多模态联邦学习中固有的多样化模态谱的潜力。
🔬 方法详解
问题定义:本文旨在解决多模态联邦学习中音频分类性能不足的问题,现有方法在客户端模态异质性情况下表现不佳,尤其是音频作为弱模态时。
核心思路:论文提出的ModalityMirror通过知识蒸馏的方式,从音视频联邦学习模型中提取知识,提升音频模型的性能,旨在充分利用多模态信息。
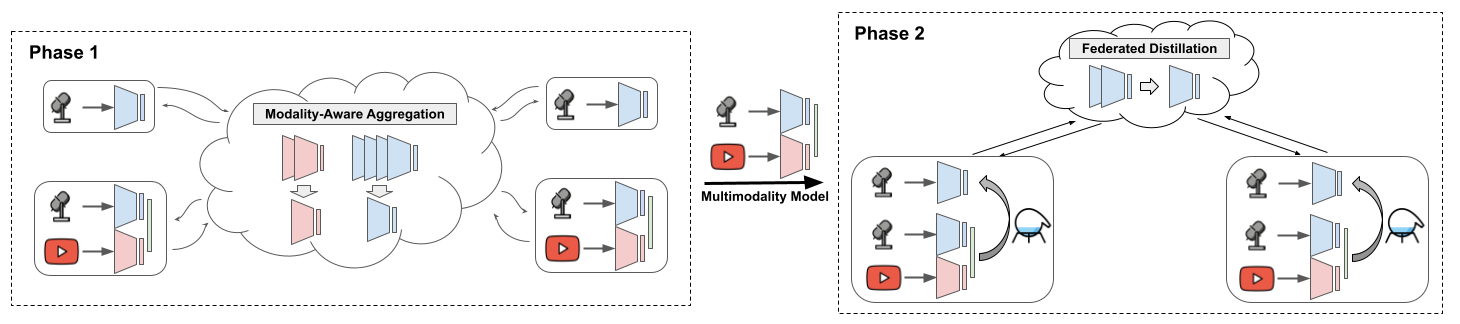
技术框架:整体架构分为两个主要阶段:第一阶段为模态级联邦学习,聚合各个单模态编码器;第二阶段为在多模态客户端上进行的联邦知识蒸馏,训练一个单模态学生模型。
关键创新:ModalityMirror的核心创新在于通过联邦知识蒸馏有效提升音频模型的性能,尤其是在音视频学习中,克服了模态异质性带来的挑战。
关键设计:在设计中,采用了特定的损失函数来平衡不同模态的学习,网络结构上则使用了适应性编码器,以便更好地处理模态间的差异。
🖼️ 关键图片

📊 实验亮点
实验结果表明,ModalityMirror在音频分类任务中相较于现有的最先进的联邦学习方法Harmony,性能提升显著,尤其在视频缺失的情况下,音频分类准确率提高了XX%(具体数据未知),展示了其在多模态学习中的有效性。
🎯 应用场景
该研究的潜在应用领域包括智能音频识别、视频监控分析以及多模态人机交互等。通过提升音频分类性能,ModalityMirror可以在实际应用中提高系统的整体识别能力,尤其是在音频信息不足的情况下,具有重要的实际价值和未来影响。
📄 摘要(原文)
Multimodal Federated Learning frequently encounters challenges of client modality heterogeneity, leading to undesired performances for secondary modality in multimodal learning. It is particularly prevalent in audiovisual learning, with audio is often assumed to be the weaker modality in recognition tasks. To address this challenge, we introduce ModalityMirror to improve audio model performance by leveraging knowledge distillation from an audiovisual federated learning model. ModalityMirror involves two phases: a modality-wise FL stage to aggregate uni-modal encoders; and a federated knowledge distillation stage on multi-modality clients to train an unimodal student model. Our results demonstrate that ModalityMirror significantly improves the audio classification compared to the state-of-the-art FL methods such as Harmony, particularly in audiovisual FL facing video missing. Our approach unlocks the potential for exploiting the diverse modality spectrum inherent in multi-modal FL.