An Empirical Study on Self-correcting Large Language Models for Data Science Code Generation
作者: Thai Tang Quoc, Duc Ha Minh, Tho Quan Thanh, Anh Nguyen-Duc
分类: cs.SE, cs.AI
发布日期: 2024-08-28
💡 一句话要点
提出CoT-SelfEvolve框架,通过自纠正机制提升LLM在数据科学代码生成中的准确性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 代码生成 自纠正 思维链 数据科学 DS-1000 Python
📋 核心要点
- 现有LLM代码生成易出错,需外部修正,限制了其在复杂数据科学任务中的应用。
- CoT-SelfEvolve利用思维链和自纠正机制,迭代优化LLM生成的代码,提升准确性。
- 在DS-1000数据集上,CoT-SelfEvolve显著优于现有模型,并在迭代中持续提升性能。
📝 摘要(中文)
大型语言模型(LLMs)在软件工程任务,特别是代码生成方面取得了显著进展。然而,LLMs生成的代码常常存在不准确和幻觉问题,需要外部输入进行修正。一种新兴策略是利用模型自身的输出来改进生成的代码(自增强)。本文提出了一种名为CoT-SelfEvolve的新方法。CoT-SelfEvolve通过一个自纠正过程迭代地、自动地改进代码,该过程由从真实编程问题反馈构建的思维链引导。专注于数据科学代码,包括NumPy和Pandas等Python库,在DS-1000数据集上的评估表明,CoT-SelfEvolve在解决复杂问题方面显著优于现有模型。该框架在初始代码生成和后续迭代中均表现出显著改进,模型的准确性随着每次迭代的增加而显著提高。这突出了使用思维链提示来解决程序执行器回溯错误消息所揭示的复杂性的有效性。我们还讨论了如何将CoT-SelfEvolve集成到持续软件工程环境中,为改进基于LLM的代码生成提供了一个实用的解决方案。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在数据科学代码生成中存在的准确性和幻觉问题。现有方法生成的代码往往需要人工干预或外部输入进行修正,这降低了开发效率,限制了LLMs在复杂数据科学任务中的应用。现有方法无法有效利用程序执行反馈信息进行自纠正,导致代码质量难以保证。
核心思路:论文的核心思路是利用LLM自身的能力,通过迭代的自纠正过程来提升代码质量。具体而言,模型首先生成初始代码,然后利用程序执行器的反馈信息(例如,错误消息)构建思维链(Chain-of-Thought, CoT),指导模型进行代码修正。通过多次迭代,模型逐步完善代码,最终达到满足要求的准确性。这种自增强的方法避免了对外部输入的依赖,提高了代码生成的自动化程度。
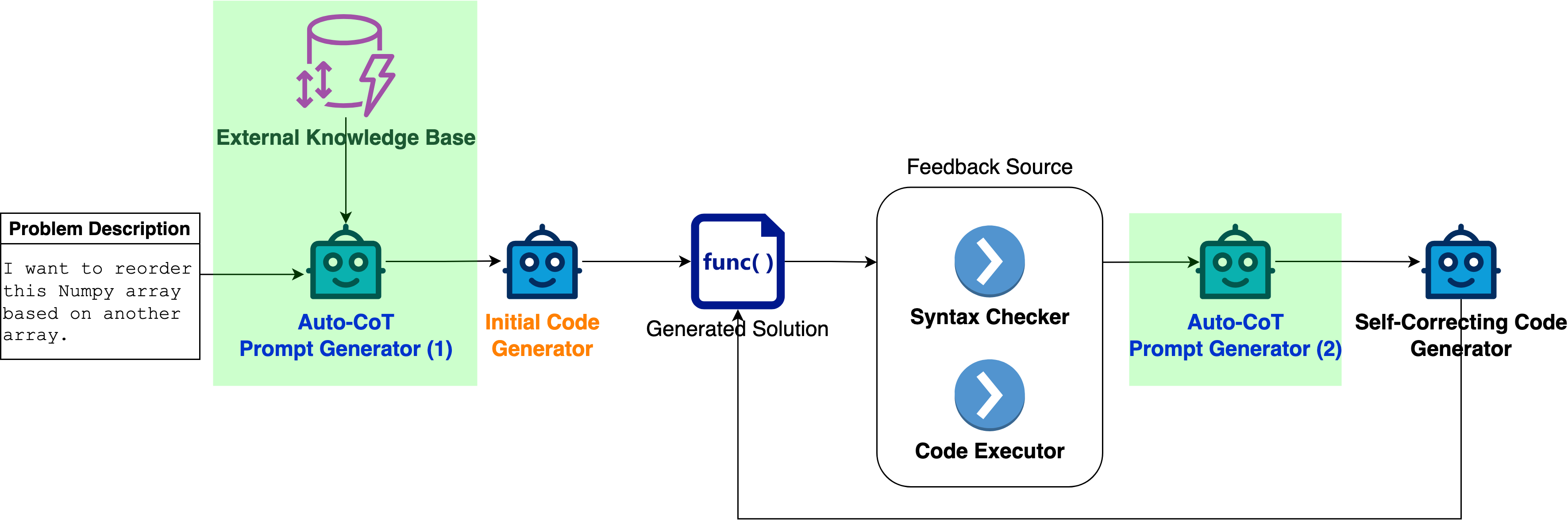
技术框架:CoT-SelfEvolve框架包含以下主要阶段:1) 初始代码生成:LLM根据给定的问题描述生成初始代码。2) 程序执行与反馈:执行生成的代码,并获取程序执行器的反馈信息(例如,错误消息、警告)。3) 思维链构建:利用反馈信息构建思维链,分析错误原因,并提出修正方案。4) 代码修正:根据思维链的指导,LLM对代码进行修正。5) 迭代优化:重复步骤2-4,直到代码通过所有测试用例或达到最大迭代次数。
关键创新:CoT-SelfEvolve的关键创新在于其自纠正机制,它能够利用程序执行器的反馈信息,通过思维链引导LLM进行代码修正。与传统的代码生成方法相比,CoT-SelfEvolve无需人工干预,能够自动地提升代码质量。此外,该方法还能够有效地利用LLM自身的知识和推理能力,从而生成更准确、更可靠的代码。
关键设计:CoT-SelfEvolve的关键设计包括:1) 思维链的构建方式:如何从程序执行器的反馈信息中提取关键信息,并构建有效的思维链,是影响模型性能的关键因素。论文可能采用了特定的提示工程技巧来引导LLM生成高质量的思维链。2) 迭代次数的设置:迭代次数决定了模型修正代码的次数,过少的迭代可能无法充分提升代码质量,而过多的迭代则可能导致计算资源的浪费。论文可能对迭代次数进行了优化。3) 提示词工程:论文使用了特定的提示词来引导LLM生成代码、分析错误和修正代码。这些提示词的设计对模型的性能至关重要。
🖼️ 关键图片

📊 实验亮点
CoT-SelfEvolve在DS-1000数据集上取得了显著的性能提升,超越了现有模型。实验结果表明,该方法不仅能够生成更准确的初始代码,而且能够在后续迭代中持续提升代码质量。模型的准确性随着迭代次数的增加而显著提高,验证了自纠正机制的有效性。具体性能数据(例如,通过测试用例的比例)未知,但摘要强调了显著优于现有模型。
🎯 应用场景
CoT-SelfEvolve可应用于自动化数据科学工作流程,例如自动生成数据清洗、特征工程和模型训练代码。该方法能够降低对人工干预的依赖,提高数据科学项目的开发效率。此外,CoT-SelfEvolve还可以集成到持续软件工程环境中,实现代码的持续集成和持续交付,从而加速软件开发过程。
📄 摘要(原文)
Large Language Models (LLMs) have recently advanced many applications on software engineering tasks, particularly the potential for code generation. Among contemporary challenges, code generated by LLMs often suffers from inaccuracies and hallucinations, requiring external inputs to correct. One recent strategy to fix these issues is to refine the code generated from LLMs using the input from the model itself (self-augmented). In this work, we proposed a novel method, namely CoT-SelfEvolve. CoT-SelfEvolve iteratively and automatically refines code through a self-correcting process, guided by a chain of thought constructed from real-world programming problem feedback. Focusing on data science code, including Python libraries such as NumPy and Pandas, our evaluations on the DS-1000 dataset demonstrate that CoT-SelfEvolve significantly outperforms existing models in solving complex problems. The framework shows substantial improvements in both initial code generation and subsequent iterations, with the model's accuracy increasing significantly with each additional iteration. This highlights the effectiveness of using chain-of-thought prompting to address complexities revealed by program executor traceback error messages. We also discuss how CoT-SelfEvolve can be integrated into continuous software engineering environments, providing a practical solution for improving LLM-based code generation.