CodeSift: An LLM-Based Reference-Less Framework for Automatic Code Validation
作者: Pooja Aggarwal, Oishik Chatterjee, Ting Dai, Prateeti Mohapatra, Brent Paulovicks, Brad Blancett, Arthur De Magalhaes
分类: cs.SE, cs.AI
发布日期: 2024-08-28
💡 一句话要点
CodeSift:基于LLM的无参考代码自动验证框架,提升代码质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码验证 大型语言模型 自动化测试 代码质量 静态分析
📋 核心要点
- 传统代码验证方法耗时且易错,难以应对大规模代码生成带来的挑战。
- CodeSift利用LLM进行代码验证,无需参考代码或人工干预,降低验证成本。
- 实验结果表明,CodeSift优于现有代码评估方法,并与人类专家偏好一致。
📝 摘要(中文)
大型语言模型(LLMs)的出现极大地促进了代码生成,但确保生成代码的功能正确性仍然是一个挑战。传统的验证方法通常耗时、容易出错,并且对于大量代码来说不切实际。我们介绍CodeSift,这是一个新颖的框架,它利用LLM作为代码验证的第一道防线,无需执行、参考代码或人工反馈,从而减少验证工作量。我们在包含两种编程语言的三个不同数据集上评估了我们方法的有效性。我们的结果表明,CodeSift优于最先进的代码评估方法。与主题专家进行的内部测试表明,CodeSift生成的输出与人类偏好一致,从而增强了其作为可靠的自动化代码验证工具的有效性。
🔬 方法详解
问题定义:论文旨在解决大规模代码生成后,如何高效、准确地验证代码功能正确性的问题。现有代码验证方法,如基于测试用例的验证,需要大量人工编写测试用例,耗时且覆盖率有限;基于参考代码的验证,依赖于高质量的参考实现,实际应用中难以获取。这些方法难以满足快速增长的代码验证需求。
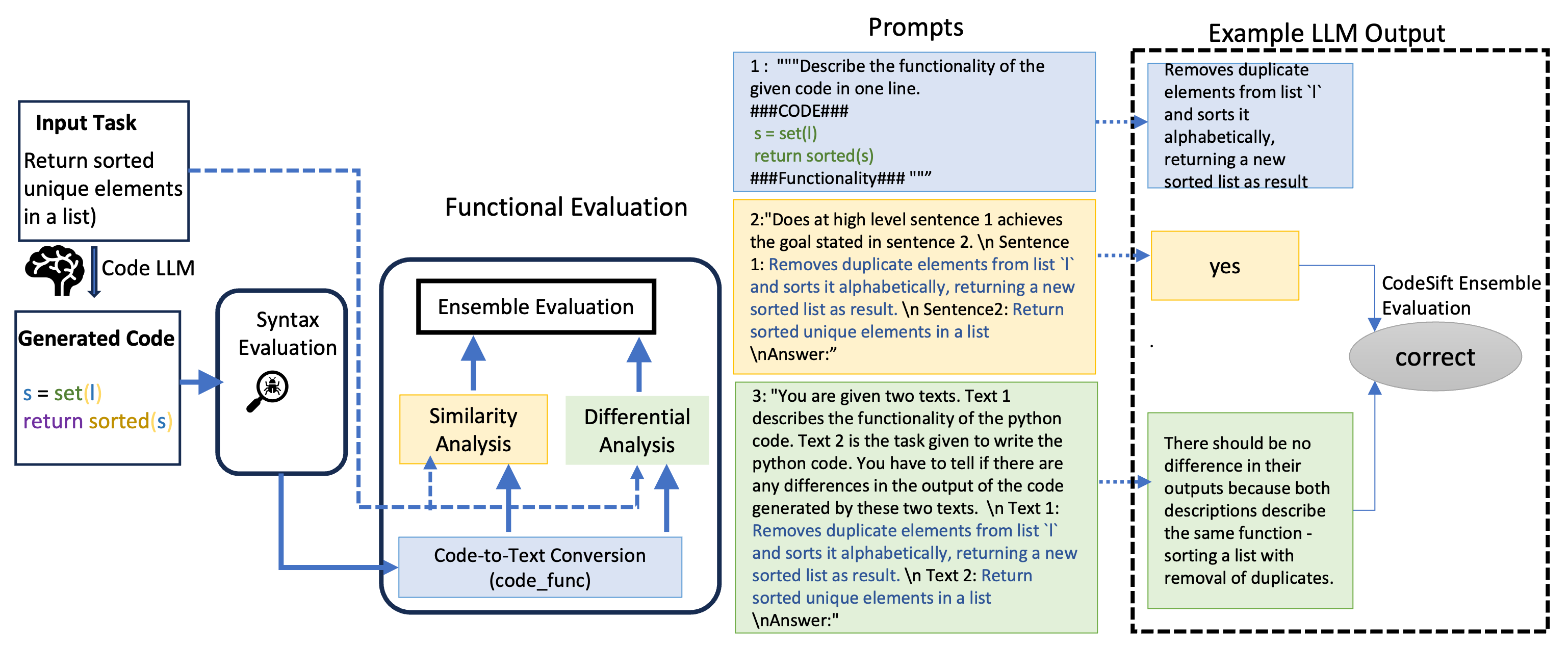
核心思路:CodeSift的核心思路是利用LLM强大的代码理解和推理能力,直接对生成的代码进行静态分析和评估,判断其是否符合预期功能和编码规范。通过将LLM作为代码验证的第一道防线,可以快速过滤掉明显错误的代码,从而减少后续验证所需的人工干预。
技术框架:CodeSift框架主要包含以下几个阶段:1) 代码输入:接收待验证的代码片段。2) LLM评估:使用预训练的LLM对代码进行分析和评估,判断其功能正确性、代码质量和潜在风险。3) 结果输出:输出LLM的评估结果,包括代码质量评分、潜在错误提示和修改建议。该框架无需执行代码或参考代码,即可实现自动化的代码验证。
关键创新:CodeSift的关键创新在于将LLM应用于代码验证领域,并设计了一种无参考代码的验证方法。与传统的基于测试或参考代码的方法不同,CodeSift直接利用LLM的知识和推理能力,对代码进行静态分析和评估,从而避免了对大量测试用例或参考代码的依赖。
关键设计:论文中没有明确给出关键参数设置、损失函数或网络结构的具体细节。推测可能使用了预训练的LLM,并通过prompt engineering来引导LLM进行代码评估。具体的prompt设计和LLM的选择可能是影响CodeSift性能的关键因素,但论文中未详细描述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CodeSift在代码验证任务上优于现有方法。具体而言,CodeSift在三个不同的数据集上都取得了更好的性能,并且与人类专家的评估结果更加一致。内部测试表明,CodeSift的输出与人类偏好一致,证明了其作为自动化代码验证工具的有效性。
🎯 应用场景
CodeSift可应用于软件开发、代码生成、自动化测试等领域。它可以帮助开发者快速验证生成的代码,提高代码质量,减少人工验证成本。此外,CodeSift还可以用于代码审查、代码风格检查等方面,促进代码规范化和标准化。未来,CodeSift有望成为自动化软件开发流程中的重要组成部分。
📄 摘要(原文)
The advent of large language models (LLMs) has greatly facilitated code generation, but ensuring the functional correctness of generated code remains a challenge. Traditional validation methods are often time-consuming, error-prone, and impractical for large volumes of code. We introduce CodeSift, a novel framework that leverages LLMs as the first-line filter of code validation without the need for execution, reference code, or human feedback, thereby reducing the validation effort. We assess the effectiveness of our method across three diverse datasets encompassing two programming languages. Our results indicate that CodeSift outperforms state-of-the-art code evaluation methods. Internal testing conducted with subject matter experts reveals that the output generated by CodeSift is in line with human preference, reinforcing its effectiveness as a dependable automated code validation tool.