Fire-Flyer AI-HPC: A Cost-Effective Software-Hardware Co-Design for Deep Learning
作者: Wei An, Xiao Bi, Guanting Chen, Shanhuang Chen, Chengqi Deng, Honghui Ding, Kai Dong, Qiushi Du, Wenjun Gao, Kang Guan, Jianzhong Guo, Yongqiang Guo, Zhe Fu, Ying He, Panpan Huang, Jiashi Li, Wenfeng Liang, Xiaodong Liu, Xin Liu, Yiyuan Liu, Yuxuan Liu, Shanghao Lu, Xuan Lu, Xiaotao Nie, Tian Pei, Junjie Qiu, Hui Qu, Zehui Ren, Zhangli Sha, Xuecheng Su, Xiaowen Sun, Yixuan Tan, Minghui Tang, Shiyu Wang, Yaohui Wang, Yongji Wang, Ziwei Xie, Yiliang Xiong, Yanhong Xu, Shengfeng Ye, Shuiping Yu, Yukun Zha, Liyue Zhang, Haowei Zhang, Mingchuan Zhang, Wentao Zhang, Yichao Zhang, Chenggang Zhao, Yao Zhao, Shangyan Zhou, Shunfeng Zhou, Yuheng Zou
分类: cs.DC, cs.AI
发布日期: 2024-08-26 (更新: 2024-08-31)
备注: This is the preprint version of the paper accepted for presentation at the 2024 International Conference for High Performance Computing, Networking, Storage, and Analysis (SC'24). \c{opyright} 2024 IEEE. Personal use of this material is permitted. For other uses, permission from IEEE must be obtained. Please refer to IEEE Xplore for the final published version
💡 一句话要点
Fire-Flyer AI-HPC:一种高性价比的深度学习软硬件协同设计方案
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: AI-HPC 深度学习 软硬件协同设计 高性能计算 GPU集群
📋 核心要点
- 深度学习模型对算力和带宽的需求激增,导致高性能计算集群的构建成本显著上升。
- Fire-Flyer AI-HPC 架构通过软硬件协同设计,旨在降低深度学习训练的成本和能耗。
- Fire-Flyer 2 集群使用 10,000 个 A100 GPU,在深度学习训练中实现了接近 DGX-A100 的性能,同时降低了成本和能耗。
📝 摘要(中文)
深度学习(DL)和大型语言模型(LLM)的快速发展呈指数级地增加了对计算能力和带宽的需求。再加上更快的计算芯片和互连的高成本,显著提高了高性能计算(HPC)的建设成本。为了应对这些挑战,我们推出了Fire-Flyer AI-HPC架构,这是一个协同的软硬件协同设计框架及其最佳实践。对于DL训练,我们部署了具有10,000个PCIe A100 GPU的Fire-Flyer 2,实现了接近DGX-A100的性能,同时降低了50%的成本和40%的能耗。我们专门设计了HFReduce来加速allreduce通信,并实施了多项措施来保持我们的计算-存储集成网络无拥塞。通过我们的软件栈,包括HaiScale、3FS和HAI-Platform,我们通过重叠计算和通信实现了显著的可扩展性。我们从DL训练中获得的系统级经验为推动AI-HPC的未来发展提供了宝贵的见解。
🔬 方法详解
问题定义:论文旨在解决深度学习训练中日益增长的算力需求和高昂的硬件成本之间的矛盾。现有方法,如直接购买高性能计算设备(例如DGX-A100),成本过高,且能耗巨大,限制了深度学习研究的普及和发展。
核心思路:论文的核心思路是通过软硬件协同设计,在保证深度学习训练性能的前提下,显著降低硬件成本和能耗。具体而言,通过优化通信协议、存储系统和软件栈,充分利用现有硬件资源,提高资源利用率,从而实现高性价比的AI-HPC平台。
技术框架:Fire-Flyer AI-HPC 架构包含以下几个主要模块:1) 硬件基础设施:由10,000个PCIe A100 GPU组成的Fire-Flyer 2集群;2) 通信优化:HFReduce加速allreduce通信,并采取措施避免网络拥塞;3) 存储系统:计算-存储集成网络;4) 软件栈:HaiScale、3FS和HAI-Platform,用于实现计算和通信的重叠,提高可扩展性。
关键创新:论文的关键创新在于软硬件协同设计的整体思路,以及针对深度学习训练特点进行的优化。例如,HFReduce针对allreduce通信进行了专门优化,计算-存储集成网络的设计考虑了深度学习训练的数据访问模式,软件栈的设计旨在最大化资源利用率。
关键设计:HFReduce的具体实现细节未知,但其目标是减少allreduce通信的延迟和带宽占用。计算-存储集成网络的具体拓扑结构和存储管理策略未知,但其目标是提供低延迟、高带宽的数据访问。HaiScale、3FS和HAI-Platform的具体实现细节未知,但其目标是实现计算和通信的重叠,提高可扩展性。
🖼️ 关键图片
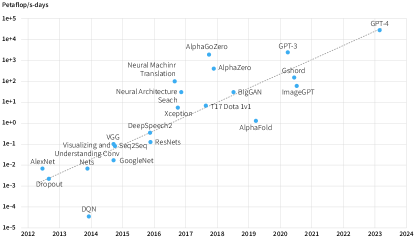
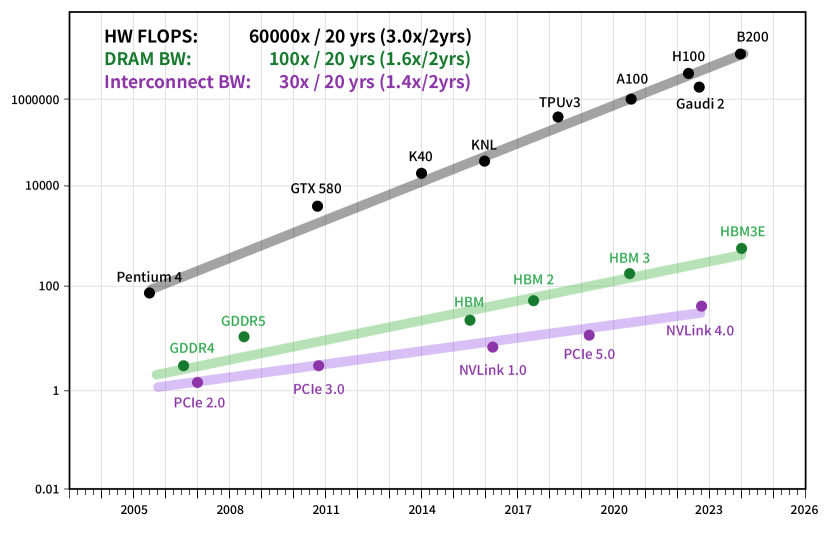
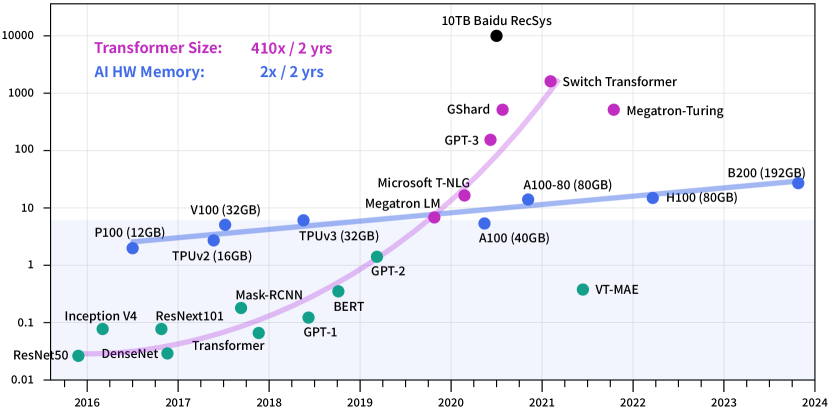
📊 实验亮点
Fire-Flyer 2 集群使用 10,000 个 PCIe A100 GPU,在深度学习训练中实现了接近 DGX-A100 的性能,同时降低了 50% 的成本和 40% 的能耗。HFReduce 能够有效加速 allreduce 通信,显著提升了集群的整体训练效率。通过 HaiScale、3FS 和 HAI-Platform 等软件栈的优化,实现了计算和通信的重叠,进一步提高了集群的可扩展性。
🎯 应用场景
Fire-Flyer AI-HPC 架构可应用于各种需要大规模深度学习训练的场景,例如自然语言处理、计算机视觉、推荐系统等。该架构的低成本和低能耗特性使其更易于部署和使用,有助于推动深度学习技术在各行各业的应用。
📄 摘要(原文)
The rapid progress in Deep Learning (DL) and Large Language Models (LLMs) has exponentially increased demands of computational power and bandwidth. This, combined with the high costs of faster computing chips and interconnects, has significantly inflated High Performance Computing (HPC) construction costs. To address these challenges, we introduce the Fire-Flyer AI-HPC architecture, a synergistic hardware-software co-design framework and its best practices. For DL training, we deployed the Fire-Flyer 2 with 10,000 PCIe A100 GPUs, achieved performance approximating the DGX-A100 while reducing costs by half and energy consumption by 40%. We specifically engineered HFReduce to accelerate allreduce communication and implemented numerous measures to keep our Computation-Storage Integrated Network congestion-free. Through our software stack, including HaiScale, 3FS, and HAI-Platform, we achieved substantial scalability by overlapping computation and communication. Our system-oriented experience from DL training provides valuable insights to drive future advancements in AI-HPC.