Exploring Large Language Models for Feature Selection: A Data-centric Perspective
作者: Dawei Li, Zhen Tan, Huan Liu
分类: cs.AI
发布日期: 2024-08-21 (更新: 2024-10-23)
备注: Accepted by SIGKDD Explorations (December 2024)
💡 一句话要点
探索基于大型语言模型(LLM)的特征选择方法,并从数据中心视角进行分析。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 特征选择 数据中心视角 文本驱动 数据驱动 语义理解 医疗应用
📋 核心要点
- 现有特征选择方法在处理复杂数据时存在局限性,难以有效利用语义信息。
- 利用LLM的强大语义理解能力,论文探索了数据驱动和文本驱动两种特征选择方法。
- 实验结果表明,基于文本的特征选择方法具有更好的有效性和鲁棒性,并在医疗领域展现潜力。
📝 摘要(中文)
本文旨在从数据中心视角探索和理解基于大型语言模型(LLM)的特征选择方法。我们将现有的基于LLM的特征选择方法分为两类:数据驱动的特征选择,它需要样本的数值来进行统计推断;以及基于文本的特征选择,它利用LLM的先验知识,使用描述性上下文进行语义关联。我们在分类和回归任务中,使用不同规模的LLM(例如GPT-4、ChatGPT和LLaMA-2)进行了实验。我们的研究结果强调了基于文本的特征选择方法的有效性和鲁棒性,并展示了其在真实医疗应用中的潜力。我们还讨论了在特征选择中应用LLM的挑战和未来机遇,为该新兴领域的进一步研究和发展提供了见解。
🔬 方法详解
问题定义:论文旨在解决传统特征选择方法无法有效利用数据中蕴含的语义信息的问题。现有方法通常依赖于数值计算,忽略了特征描述中的知识,导致在某些场景下性能受限。
核心思路:论文的核心思路是将大型语言模型(LLM)引入特征选择过程,利用LLM的语义理解和推理能力,从数据和文本两个角度进行特征选择。通过LLM对特征进行语义分析,从而选择更具代表性和相关性的特征。
技术框架:论文将基于LLM的特征选择方法分为两类:数据驱动的特征选择和文本驱动的特征选择。数据驱动方法利用样本的数值特征进行统计推断,而文本驱动方法则利用LLM的先验知识进行语义关联。研究人员使用不同规模的LLM(GPT-4、ChatGPT、LLaMA-2)在分类和回归任务中进行实验,评估两种方法的性能。
关键创新:论文的关键创新在于提出了从数据中心视角分析基于LLM的特征选择方法,并区分了数据驱动和文本驱动两种方法。强调了文本驱动方法在特征选择中的潜力,尤其是在需要利用语义信息的场景下。
关键设计:论文没有详细描述具体的参数设置、损失函数或网络结构,而是侧重于对不同LLM在特征选择任务中的表现进行评估和比较。文本驱动的方法依赖于LLM本身的预训练知识,无需额外的训练或微调。
🖼️ 关键图片


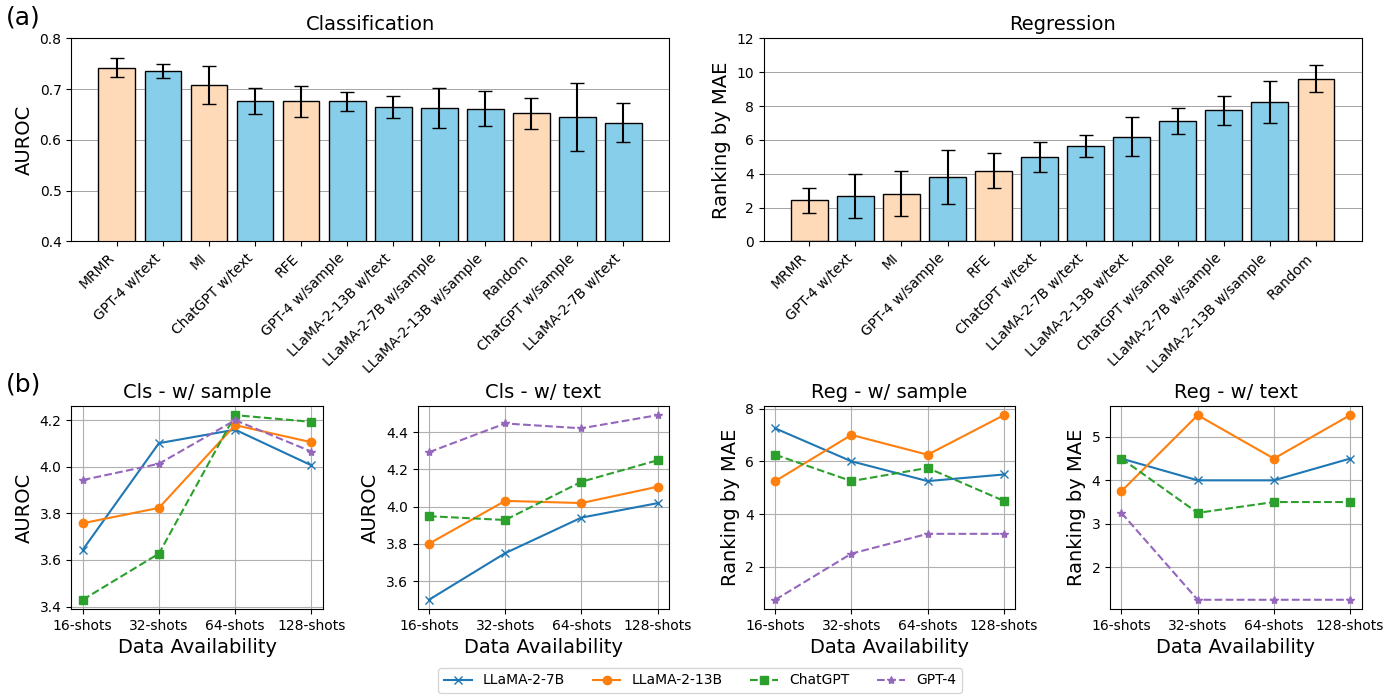
📊 实验亮点
实验结果表明,基于文本的特征选择方法在分类和回归任务中表现出良好的有效性和鲁棒性。特别是在医疗应用中,该方法能够选择出与疾病相关的关键特征,从而提高诊断准确率。研究结果强调了LLM在特征选择中的潜力,并为未来的研究方向提供了指导。
🎯 应用场景
该研究成果可应用于医疗诊断、金融风控、推荐系统等领域。通过利用LLM进行特征选择,可以提高模型的准确性和鲁棒性,从而提升决策质量。未来,该方法有望在更多需要处理复杂数据和利用语义信息的场景中发挥重要作用。
📄 摘要(原文)
The rapid advancement of Large Language Models (LLMs) has significantly influenced various domains, leveraging their exceptional few-shot and zero-shot learning capabilities. In this work, we aim to explore and understand the LLMs-based feature selection methods from a data-centric perspective. We begin by categorizing existing feature selection methods with LLMs into two groups: data-driven feature selection which requires numerical values of samples to do statistical inference and text-based feature selection which utilizes prior knowledge of LLMs to do semantical associations using descriptive context. We conduct experiments in both classification and regression tasks with LLMs in various sizes (e.g., GPT-4, ChatGPT and LLaMA-2). Our findings emphasize the effectiveness and robustness of text-based feature selection methods and showcase their potentials using a real-world medical application. We also discuss the challenges and future opportunities in employing LLMs for feature selection, offering insights for further research and development in this emerging field.