DreamFactory: Pioneering Multi-Scene Long Video Generation with a Multi-Agent Framework
作者: Zhifei Xie, Daniel Tang, Dingwei Tan, Jacques Klein, Tegawend F. Bissyand, Saad Ezzini
分类: cs.AI, cs.CL, cs.CV, cs.SE
发布日期: 2024-08-21
备注: 13 pages, 8 figures
💡 一句话要点
DreamFactory:基于多智能体框架的多场景长视频生成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频生成 多智能体系统 关键帧迭代 思维链 风格一致性 多场景视频 视频生成模型
📋 核心要点
- 现有视频生成模型难以生成长时、多场景且风格一致的视频内容。
- DreamFactory采用多智能体协作和关键帧迭代设计,保证长视频的连贯性和风格一致性。
- 论文提出了新的评估指标,并构建了包含人工标注视频的多场景视频数据集。
📝 摘要(中文)
现有的视频生成模型擅长创建短而逼真的片段,但在较长的多场景视频方面表现不佳。我们提出了 exttt{DreamFactory},这是一个基于LLM的框架,旨在解决这一挑战。 exttt{DreamFactory}利用多智能体协作原则和关键帧迭代设计方法,以确保长视频的一致性和风格。它利用思维链(COT)来解决大型语言模型中固有的不确定性。 exttt{DreamFactory}生成风格连贯且复杂的长视频。评估这些长视频提出了挑战。我们提出了新的指标,如跨场景人脸距离得分和跨场景风格一致性得分。为了进一步研究该领域,我们贡献了包含超过150个人工评估视频的多场景视频数据集。
🔬 方法详解
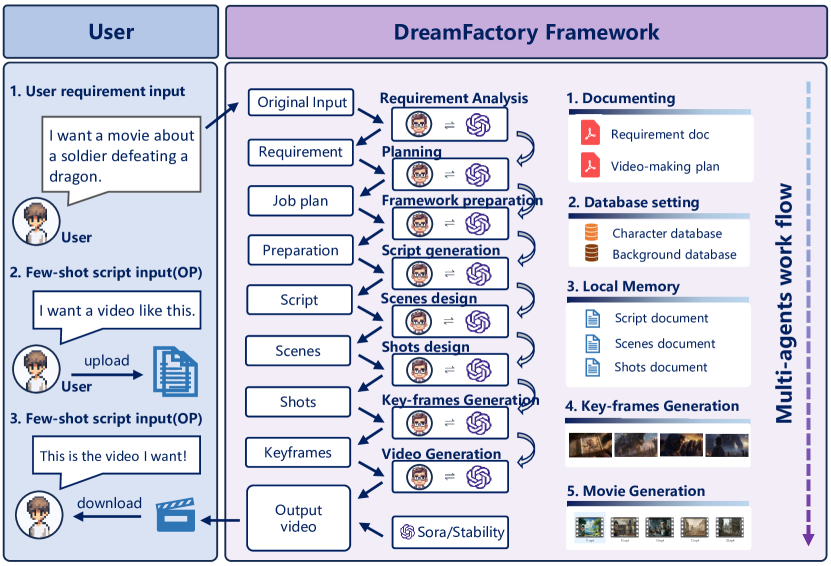
问题定义:当前视频生成模型在生成短视频片段方面表现出色,但难以生成具有多个场景的长视频,尤其是在保持场景间风格一致性和内容连贯性方面存在挑战。现有方法难以有效利用大型语言模型(LLM)的推理能力,并且缺乏针对长视频生成特点的评估指标。
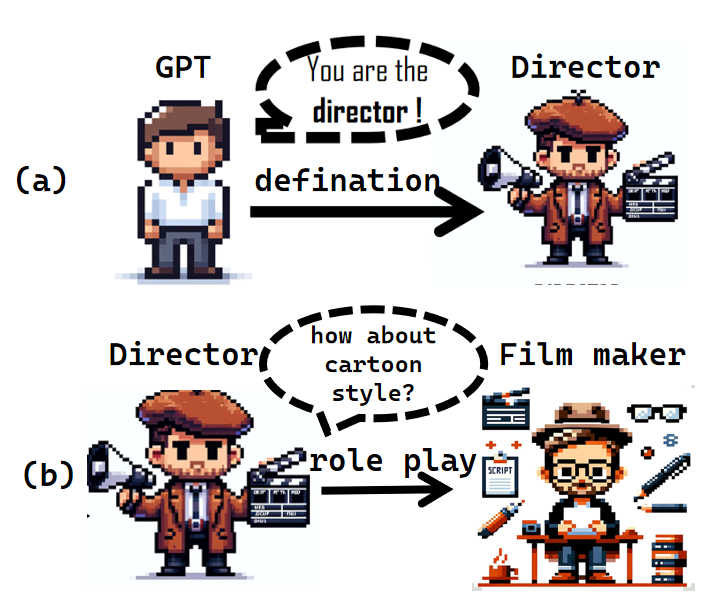
核心思路:DreamFactory的核心思路是利用多智能体协作框架,将长视频生成任务分解为多个子任务,每个智能体负责生成视频中的一个或多个关键帧。通过关键帧迭代设计方法,逐步完善视频内容,并确保场景间的风格一致性。同时,利用思维链(Chain of Thought, COT)技术,提高LLM在生成过程中的推理能力和决策质量。
技术框架:DreamFactory的整体框架包含以下几个主要模块:1) 场景规划器:负责根据用户输入的文本描述,规划视频的场景和关键事件。2) 关键帧生成器:利用LLM和图像生成模型,根据场景规划生成关键帧。3) 风格一致性模块:通过跨场景人脸距离得分和跨场景风格一致性得分等指标,评估并调整关键帧的风格,确保场景间的一致性。4) 视频组装器:将生成的关键帧组装成完整的长视频。
关键创新:DreamFactory的关键创新在于:1) 提出了基于多智能体协作的长视频生成框架,有效分解了复杂任务。2) 引入了关键帧迭代设计方法,逐步完善视频内容,提高生成质量。3) 利用思维链技术,增强了LLM的推理能力。4) 提出了新的评估指标,用于评估长视频的风格一致性和内容连贯性。
关键设计:DreamFactory的关键设计包括:1) 多智能体的角色分配和协作机制。2) 关键帧的选择和迭代策略。3) 跨场景人脸距离得分和跨场景风格一致性得分的计算方法。4) LLM的prompt设计,包括如何利用思维链技术引导LLM生成高质量的内容。具体的参数设置、损失函数和网络结构等技术细节在论文中进行了详细描述。
🖼️ 关键图片

📊 实验亮点
论文提出了跨场景人脸距离得分和跨场景风格一致性得分等新指标,用于评估长视频的质量。实验结果表明,DreamFactory生成的长视频在风格一致性和内容连贯性方面优于现有方法。通过人工评估,DreamFactory生成的视频在真实感和故事性方面也取得了显著提升。具体性能数据未知,但论文强调了在长视频生成方面的显著进步。
🎯 应用场景
DreamFactory具有广泛的应用前景,例如电影制作、广告创意、教育内容生成等。它可以帮助用户快速生成高质量的长视频,降低视频制作的成本和门槛。此外,该研究提出的多智能体协作框架和关键帧迭代设计方法,也可以应用于其他长序列生成任务,例如故事创作、音乐生成等。未来,DreamFactory有望成为一种强大的视频创作工具,推动视频内容的创新和发展。
📄 摘要(原文)
Current video generation models excel at creating short, realistic clips, but struggle with longer, multi-scene videos. We introduce \texttt{DreamFactory}, an LLM-based framework that tackles this challenge. \texttt{DreamFactory} leverages multi-agent collaboration principles and a Key Frames Iteration Design Method to ensure consistency and style across long videos. It utilizes Chain of Thought (COT) to address uncertainties inherent in large language models. \texttt{DreamFactory} generates long, stylistically coherent, and complex videos. Evaluating these long-form videos presents a challenge. We propose novel metrics such as Cross-Scene Face Distance Score and Cross-Scene Style Consistency Score. To further research in this area, we contribute the Multi-Scene Videos Dataset containing over 150 human-rated videos.