ProteinGPT: Multimodal LLM for Protein Property Prediction and Structure Understanding
作者: Yijia Xiao, Edward Sun, Yiqiao Jin, Qifan Wang, Wei Wang
分类: cs.AI, cs.CE, cs.LG, q-bio.BM
发布日期: 2024-08-21 (更新: 2025-04-17)
备注: Spotlight, Machine Learning for Genomics Explorations @ ICLR 2025
🔗 代码/项目: GITHUB
💡 一句话要点
ProteinGPT:用于蛋白质性质预测和结构理解的多模态LLM
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 蛋白质性质预测 蛋白质结构理解 多模态学习 大型语言模型 指令调优
📋 核心要点
- 传统蛋白质研究耗时且复杂,需要深入分析蛋白质结构和功能,而现有方法难以高效应对。
- ProteinGPT通过整合蛋白质序列和结构编码器,并利用大型语言模型,实现了对蛋白质性质的预测和结构理解。
- 实验结果表明,ProteinGPT在蛋白质相关问题的回答上,显著优于基线模型和通用LLM。
📝 摘要(中文)
本文提出了一种名为ProteinGPT的先进多模态大型语言模型,用于蛋白质的全面分析。用户可以上传蛋白质序列和/或结构,进行深入分析和响应式查询。ProteinGPT集成了蛋白质序列和结构编码器,并通过线性投影层确保精确的表示适应。利用大型语言模型(LLM)生成准确且上下文相关的响应。为了训练ProteinGPT,构建了一个包含132,092个蛋白质的大规模数据集,每个蛋白质都标有20-30个属性标签和5-10个问答对,并使用GPT-4o优化了指令调优过程。实验表明,ProteinGPT能够有效地生成信息丰富的蛋白质相关问题答案,在语义和词汇指标上均表现出色,并且在理解和响应蛋白质相关查询方面明显优于基线模型和通用LLM。
🔬 方法详解
问题定义:蛋白质结构和功能的分析是生物过程理解、药物开发和生物技术进步的关键。传统方法耗时且复杂,需要大量实验和计算。现有方法在整合蛋白质序列和结构信息,以及生成上下文相关的响应方面存在不足。
核心思路:ProteinGPT的核心思路是利用多模态大型语言模型(LLM),将蛋白质序列和结构信息编码为统一的表示,并利用LLM的生成能力,对蛋白质相关问题进行回答。通过指令调优,使模型能够理解用户意图并生成准确的响应。
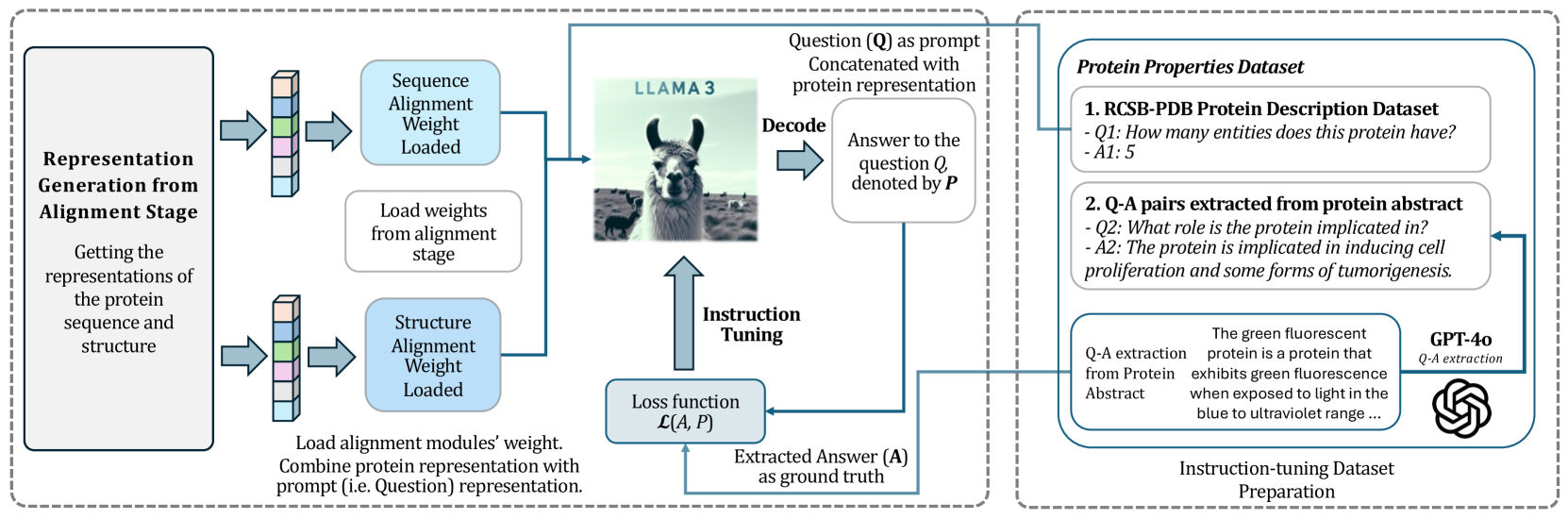
技术框架:ProteinGPT的整体架构包括以下几个主要模块:1) 蛋白质序列编码器:用于将蛋白质序列转换为向量表示。2) 蛋白质结构编码器:用于将蛋白质结构转换为向量表示。3) 线性投影层:用于将序列和结构编码器的输出投影到相同的向量空间。4) 大型语言模型(LLM):用于接收序列和结构信息的向量表示,并生成对蛋白质相关问题的回答。
关键创新:ProteinGPT的关键创新在于其多模态融合能力,能够同时利用蛋白质序列和结构信息进行分析。此外,通过构建大规模的蛋白质数据集并进行指令调优,显著提升了模型在蛋白质相关问题回答上的性能。与现有方法相比,ProteinGPT能够更全面地理解蛋白质信息,并生成更准确、更具上下文相关性的响应。
关键设计:ProteinGPT的关键设计包括:1) 大规模数据集的构建,包含蛋白质序列、结构、属性标签和问答对。2) 使用GPT-4o进行指令调优,优化模型的生成能力。3) 线性投影层的设计,确保序列和结构信息的有效融合。具体的参数设置、损失函数和网络结构等细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
ProteinGPT在蛋白质相关问题的回答上表现出色,在语义和词汇指标上均取得了高分。实验结果表明,ProteinGPT显著优于基线模型和通用LLM,能够更准确、更具上下文相关性地回答蛋白质相关问题。具体的性能数据和提升幅度未在摘要中给出,属于未知信息。
🎯 应用场景
ProteinGPT具有广泛的应用前景,包括药物发现、蛋白质工程、生物过程理解等领域。它可以帮助研究人员快速分析蛋白质结构和功能,预测蛋白质性质,并加速药物开发过程。未来,ProteinGPT有望成为蛋白质研究的重要工具,推动生物技术的发展。
📄 摘要(原文)
Understanding biological processes, drug development, and biotechnological advancements requires a detailed analysis of protein structures and functions, a task that is inherently complex and time-consuming in traditional protein research. To streamline this process, we introduce ProteinGPT, a state-of-the-art multimodal large language model for proteins that enables users to upload protein sequences and/or structures for comprehensive analysis and responsive inquiries. ProteinGPT integrates protein sequence and structure encoders with linear projection layers to ensure precise representation adaptation and leverages a large language model (LLM) to generate accurate, contextually relevant responses. To train ProteinGPT, we constructed a large-scale dataset of 132,092 proteins, each annotated with 20-30 property tags and 5-10 QA pairs per protein, and optimized the instruction-tuning process using GPT-4o. Experiments demonstrate that ProteinGPT effectively generates informative responses to protein-related questions, achieving high performance on both semantic and lexical metrics and significantly outperforming baseline models and general-purpose LLMs in understanding and responding to protein-related queries. Our code and data are available at https://github.com/ProteinGPT/ProteinGPT.