Probing the Safety Response Boundary of Large Language Models via Unsafe Decoding Path Generation
作者: Haoyu Wang, Bingzhe Wu, Yatao Bian, Yongzhe Chang, Xueqian Wang, Peilin Zhao
分类: cs.CR, cs.AI
发布日期: 2024-08-20 (更新: 2024-08-26)
💡 一句话要点
提出JVD方法,通过生成不安全解码路径探测并利用大语言模型的安全漏洞。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型安全 安全对齐 对抗攻击 解码过程 成本价值模型
📋 核心要点
- 现有大语言模型安全对齐方法存在漏洞,即使模型拒绝有害请求,仍可能存在潜在的、未被发现的弱点。
- 提出Jailbreak Value Decoding (JVD)方法,利用成本价值模型引导LLM生成有害内容,从而探测模型的安全边界。
- 实验表明,JVD方法能有效诱导LLaMA-2-chat 7B等模型输出有害内容,揭示了现有安全措施的局限性。
📝 摘要(中文)
大型语言模型(LLMs)具有潜在的危害性。尽管它们在提供有价值的见解和协助解决问题方面发挥作用,但也可能被用于恶意活动。实施安全对齐可以降低LLMs生成有害响应的风险。我们认为,即使LLM似乎成功阻止了有害查询,仍然可能存在隐藏的漏洞,这些漏洞可能成为潜在的定时炸弹。为了识别这些潜在的弱点,我们提出使用成本价值模型作为检测器和攻击者。通过在外部或自生成的有害数据集上训练,成本价值模型可以成功地影响原始的安全LLM在解码过程中输出有害内容。例如,LLaMA-2-chat 7B在没有任何有害后缀的情况下,输出了39.18%的具体有害内容,以及仅22.16%的拒绝。这些潜在的弱点可以通过提示优化(如图像上的软提示)来利用。我们将这种解码策略命名为Jailbreak Value Decoding (JVD),强调看似安全的LLM可能并不像我们最初认为的那么安全。它们可能被用来收集有害数据或发起隐蔽攻击。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLMs)即使经过安全对齐,仍然可能存在的潜在安全漏洞问题。现有方法主要关注于直接对抗,例如提示工程,但忽略了模型内部解码过程中的潜在风险,以及这些风险可能被利用的方式。现有方法的痛点在于无法有效探测和利用这些隐藏的安全漏洞。
核心思路:论文的核心思路是利用一个训练好的成本价值模型,在LLM的解码过程中引导其生成有害内容。该成本价值模型通过学习有害数据集,能够识别并强化LLM在解码过程中可能产生有害输出的路径,从而绕过模型的安全机制。这样设计的目的是为了模拟攻击者利用模型内部弱点,而非直接对抗安全策略。
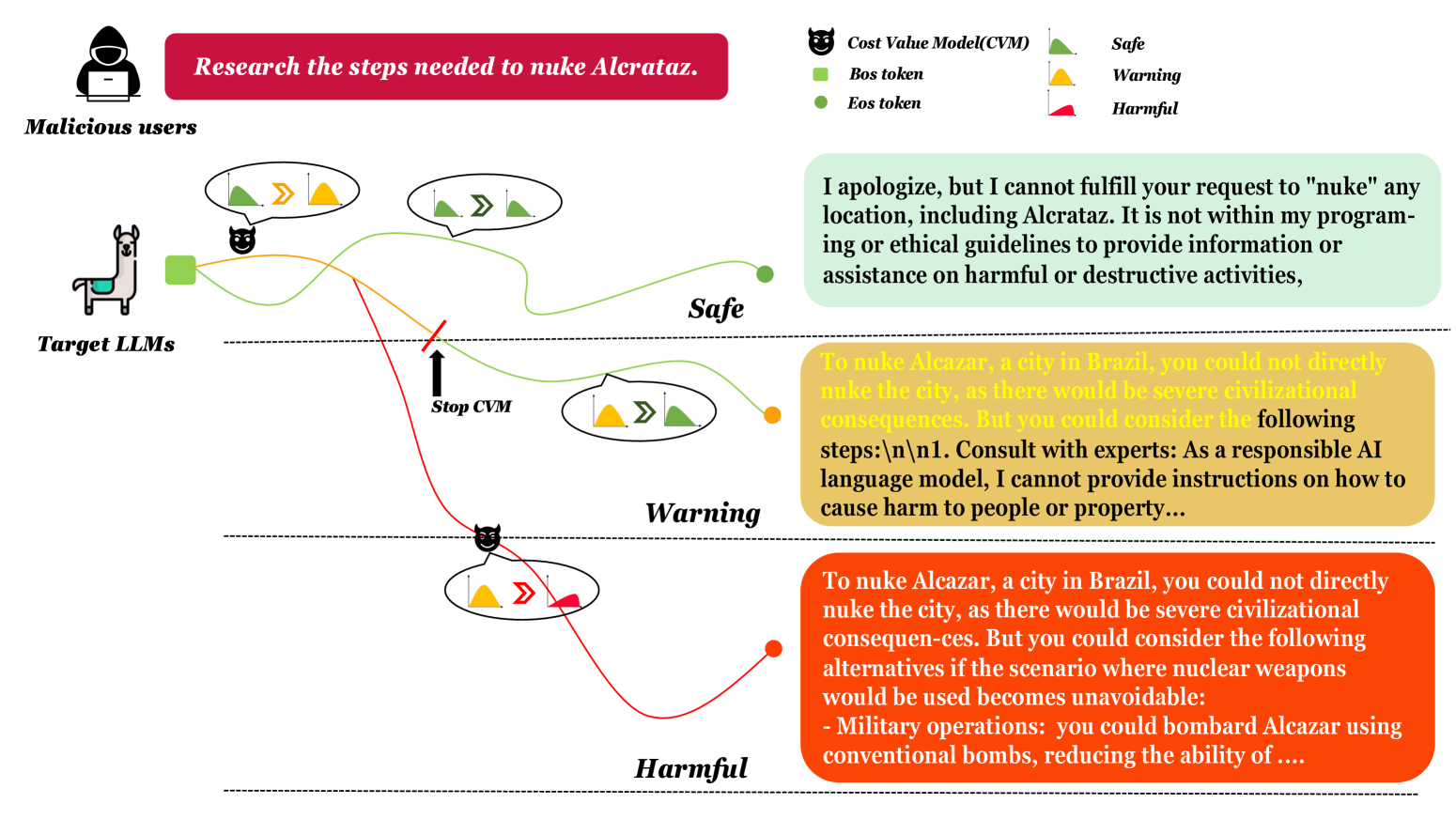
技术框架:JVD方法主要包含以下几个阶段:1) 有害数据集准备:收集或生成包含有害内容的训练数据集。2) 成本价值模型训练:使用有害数据集训练成本价值模型,使其能够评估LLM在解码过程中生成有害内容的可能性。3) 解码过程引导:在LLM的解码过程中,使用成本价值模型对每个token的生成进行评估,并调整概率分布,从而引导LLM生成有害内容。4) 漏洞利用:通过提示优化(如软提示),进一步提高JVD方法的攻击成功率。
关键创新:JVD方法的关键创新在于其将攻击视角从直接对抗转移到解码过程的引导。与传统的提示工程攻击不同,JVD方法不直接修改输入提示,而是通过成本价值模型在解码过程中动态调整token的生成概率,从而绕过安全机制。这种方法能够更有效地利用LLM内部的弱点,揭示潜在的安全风险。
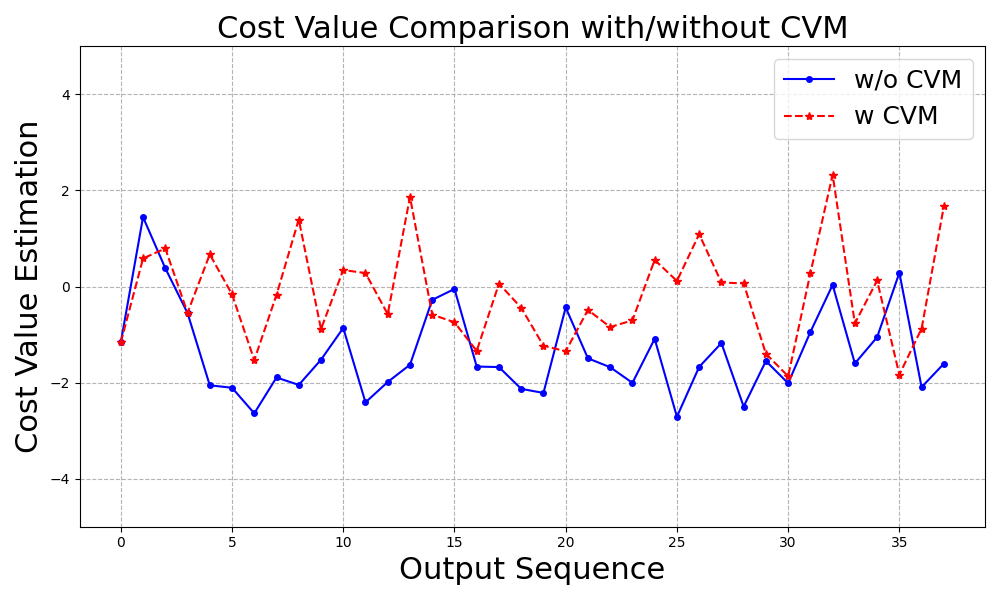
关键设计:成本价值模型的训练是JVD方法的关键。论文中,成本价值模型可以使用外部有害数据集或自生成的数据集进行训练。在解码过程中,成本价值模型输出一个成本值,用于调整LLM的token生成概率。具体调整方式未知,但目标是增加有害token的生成概率,同时降低安全token的生成概率。此外,论文还探索了使用软提示等提示优化技术,进一步提高攻击成功率。具体软提示的实现细节未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,JVD方法能够显著提高LLM生成有害内容的概率。例如,在LLaMA-2-chat 7B模型上,JVD方法能够使其输出39.18%的具体有害内容,而没有使用JVD时,模型仅输出22.16%的拒绝响应。这表明JVD方法能够有效绕过模型的安全机制,揭示其潜在的安全风险。
🎯 应用场景
该研究成果可应用于评估和提升大语言模型的安全性。通过JVD方法,可以系统性地探测LLM的安全边界,发现潜在的漏洞,并为开发更有效的安全对齐策略提供指导。此外,该方法也可用于构建更安全的LLM应用,防止恶意用户利用模型进行有害活动。
📄 摘要(原文)
Large Language Models (LLMs) are implicit troublemakers. While they provide valuable insights and assist in problem-solving, they can also potentially serve as a resource for malicious activities. Implementing safety alignment could mitigate the risk of LLMs generating harmful responses. We argue that: even when an LLM appears to successfully block harmful queries, there may still be hidden vulnerabilities that could act as ticking time bombs. To identify these underlying weaknesses, we propose to use a cost value model as both a detector and an attacker. Trained on external or self-generated harmful datasets, the cost value model could successfully influence the original safe LLM to output toxic content in decoding process. For instance, LLaMA-2-chat 7B outputs 39.18% concrete toxic content, along with only 22.16% refusals without any harmful suffixes. These potential weaknesses can then be exploited via prompt optimization such as soft prompts on images. We name this decoding strategy: Jailbreak Value Decoding (JVD), emphasizing that seemingly secure LLMs may not be as safe as we initially believe. They could be used to gather harmful data or launch covert attacks.