LegalBench-RAG: A Benchmark for Retrieval-Augmented Generation in the Legal Domain
作者: Nicholas Pipitone, Ghita Houir Alami
分类: cs.AI
发布日期: 2024-08-19
🔗 代码/项目: GITHUB
💡 一句话要点
LegalBench-RAG:法律领域检索增强生成评测基准,关注精准检索片段
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 法律领域 评测基准 信息检索 大型语言模型 RAG系统 文本片段检索
📋 核心要点
- 现有法律领域RAG系统缺乏专门的检索评估基准,难以有效衡量和提升检索组件的性能。
- LegalBench-RAG通过构建包含专家标注的查询-答案对数据集,专注于评估从法律文本中精确检索相关片段的能力。
- 该基准包含完整版和轻量版,为法律RAG系统的检索评估和快速迭代提供了有效工具。
📝 摘要(中文)
检索增强生成(RAG)系统在AI驱动的法律应用中展现出巨大潜力。现有基准,如LegalBench,评估了大型语言模型(LLM)在法律领域的生成能力,但评估RAG系统检索组件方面存在关键差距。为此,我们推出了LegalBench-RAG,这是首个专门用于评估法律领域RAG流水线检索步骤的基准。LegalBench-RAG强调精确检索,侧重于从法律文件中提取最小、高度相关的文本片段。相比于检索文档ID或大段不精确的文本块,这种方式更优,因为后者可能超出上下文窗口的限制。长上下文窗口处理成本更高,延迟更高,并可能导致LLM遗忘或产生幻觉。此外,精确的结果允许LLM为最终用户生成引用。LegalBench-RAG基准通过将LegalBench查询中使用的上下文追溯到法律语料库中的原始位置来构建,从而形成一个包含6,858个查询-答案对的数据集,语料库超过7900万字符,完全由法律专家人工标注。我们还推出了LegalBench-RAG-mini,一个用于快速迭代和实验的轻量级版本。通过为法律检索提供专用基准,LegalBench-RAG为专注于提高法律领域RAG系统准确性和性能的公司和研究人员提供了一个关键工具。LegalBench-RAG数据集可在https://github.com/zeroentropy-cc/legalbenchrag公开获取。
🔬 方法详解
问题定义:现有法律领域的RAG系统评估主要集中在生成能力上,缺乏对检索环节的有效评估。现有方法通常检索整个文档或较大文本块,导致上下文窗口限制、处理成本高、延迟高以及LLM产生幻觉等问题。因此,需要一个专门的基准来评估RAG系统在法律领域精确检索相关文本片段的能力。
核心思路:LegalBench-RAG的核心思路是构建一个高质量的法律领域检索数据集,该数据集包含查询、答案以及从法律文本中提取的最小、高度相关的文本片段。通过评估RAG系统检索这些精确片段的能力,可以更有效地评估其检索性能,并促进RAG系统在法律领域的应用。
技术框架:LegalBench-RAG的构建流程主要包括以下几个步骤:1) 回溯LegalBench查询中使用的上下文到原始法律文本;2) 由法律专家人工标注与查询相关的最小文本片段;3) 构建包含查询-答案对和对应文本片段的数据集。此外,还提供了一个轻量级版本LegalBench-RAG-mini,用于快速迭代和实验。
关键创新:LegalBench-RAG的关键创新在于其专注于评估RAG系统在法律领域精确检索相关文本片段的能力。与现有方法不同,LegalBench-RAG不评估文档级别的检索,而是关注更细粒度的文本片段检索,这更符合法律领域对精确信息检索的需求。
关键设计:LegalBench-RAG数据集包含6,858个查询-答案对,语料库超过7900万字符,完全由法律专家人工标注。数据集的构建过程保证了查询和答案之间的高度相关性,以及文本片段的最小化和精确性。LegalBench-RAG-mini则是一个更小的数据集,方便快速实验和迭代。
🖼️ 关键图片

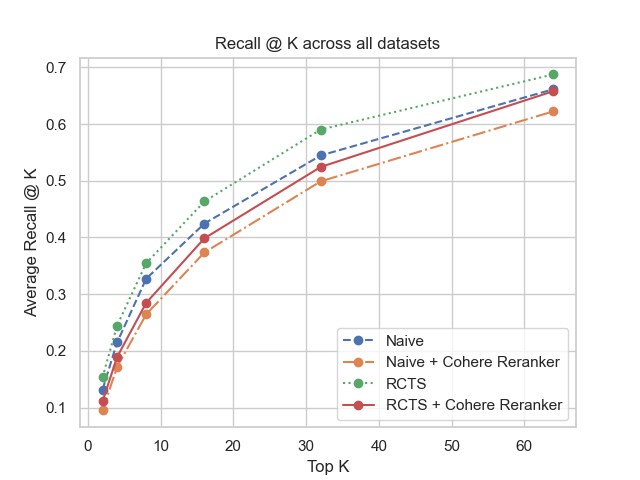
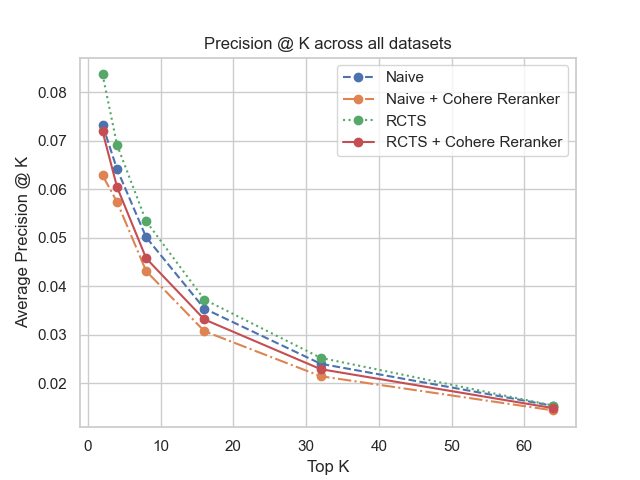
📊 实验亮点
LegalBench-RAG构建了一个包含6,858个查询-答案对的法律领域检索数据集,由法律专家人工标注,语料库超过7900万字符。该数据集专注于评估RAG系统精确检索相关文本片段的能力,为法律RAG系统的检索评估提供了可靠的基准。同时,LegalBench-RAG-mini的轻量级设计方便了快速迭代和实验。
🎯 应用场景
LegalBench-RAG可用于评估和改进法律领域的RAG系统,提升法律咨询、案例分析、法律文件起草等应用的智能化水平。通过精确检索相关法律条文和案例,RAG系统可以为法律专业人士提供更准确、高效的信息支持,降低工作成本,提高工作效率。未来,LegalBench-RAG可以扩展到其他法律领域,并与其他法律知识图谱和数据库相结合,构建更强大的法律智能系统。
📄 摘要(原文)
Retrieval-Augmented Generation (RAG) systems are showing promising potential, and are becoming increasingly relevant in AI-powered legal applications. Existing benchmarks, such as LegalBench, assess the generative capabilities of Large Language Models (LLMs) in the legal domain, but there is a critical gap in evaluating the retrieval component of RAG systems. To address this, we introduce LegalBench-RAG, the first benchmark specifically designed to evaluate the retrieval step of RAG pipelines within the legal space. LegalBench-RAG emphasizes precise retrieval by focusing on extracting minimal, highly relevant text segments from legal documents. These highly relevant snippets are preferred over retrieving document IDs, or large sequences of imprecise chunks, both of which can exceed context window limitations. Long context windows cost more to process, induce higher latency, and lead LLMs to forget or hallucinate information. Additionally, precise results allow LLMs to generate citations for the end user. The LegalBench-RAG benchmark is constructed by retracing the context used in LegalBench queries back to their original locations within the legal corpus, resulting in a dataset of 6,858 query-answer pairs over a corpus of over 79M characters, entirely human-annotated by legal experts. We also introduce LegalBench-RAG-mini, a lightweight version for rapid iteration and experimentation. By providing a dedicated benchmark for legal retrieval, LegalBench-RAG serves as a critical tool for companies and researchers focused on enhancing the accuracy and performance of RAG systems in the legal domain. The LegalBench-RAG dataset is publicly available at https://github.com/zeroentropy-cc/legalbenchrag.