ELASTIC: Efficient Linear Attention for Sequential Interest Compression
作者: Jiaxin Deng, Shiyao Wang, Song Lu, Yinfeng Li, Xinchen Luo, Yuanjun Liu, Peixing Xu, Guorui Zhou
分类: cs.AI, cs.IR
发布日期: 2024-08-18 (更新: 2025-02-12)
备注: We hereby withdraw this paper from arXiv due to incomplete experiments. Upon further review, we have determined that additional experimental work is necessary to fully validate our findings and conclusions
💡 一句话要点
ELASTIC:一种高效线性注意力机制,用于序列兴趣压缩,加速长序列推荐。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 序列推荐 线性注意力 长序列建模 兴趣压缩 兴趣记忆库
📋 核心要点
- Transformer的自注意力机制在序列推荐中表现出色,但其二次复杂度限制了对用户长期行为序列的建模能力。
- ELASTIC通过线性dispatcher注意力机制压缩长序列,并利用兴趣记忆库检索用户兴趣,实现了计算效率和推荐精度的平衡。
- 实验表明,ELASTIC在多个数据集上显著优于现有模型,并大幅降低了GPU内存占用和推理时间。
📝 摘要(中文)
本文提出了一种名为ELASTIC的高效线性注意力机制,用于序列兴趣压缩,旨在解决Transformer的自注意力机制在序列推荐模型中计算和内存复杂度过高的问题。ELASTIC仅需线性时间复杂度,并将模型容量与计算成本解耦,通过固定长度的兴趣专家和线性dispatcher注意力机制,将长序列压缩为更紧凑的表示,从而减少高达90%的GPU内存使用,并加速2.7倍的推理速度。此外,ELASTIC初始化了一个庞大的可学习兴趣记忆库,并以极低的计算开销从中稀疏地检索压缩后的用户兴趣。实验结果表明,ELASTIC在多个公共数据集上始终优于基线模型,并突出了其在建模长序列时的计算效率。代码将开源。
🔬 方法详解
问题定义:现有序列推荐模型依赖Transformer的自注意力机制,但自注意力机制的计算和内存复杂度是序列长度的平方级别,这限制了模型处理超长用户行为序列的能力,阻碍了对用户长期兴趣的有效建模。因此,如何降低计算复杂度,同时保持模型对用户兴趣的建模能力,是本文要解决的核心问题。
核心思路:ELASTIC的核心思路是利用线性注意力机制来压缩用户行为序列,并结合可学习的兴趣记忆库来增强模型对用户多样化兴趣的建模能力。通过线性注意力机制,将序列长度的依赖从平方级别降低到线性级别,从而显著降低计算复杂度。兴趣记忆库则用于存储丰富的用户兴趣表示,弥补序列压缩可能带来的信息损失。
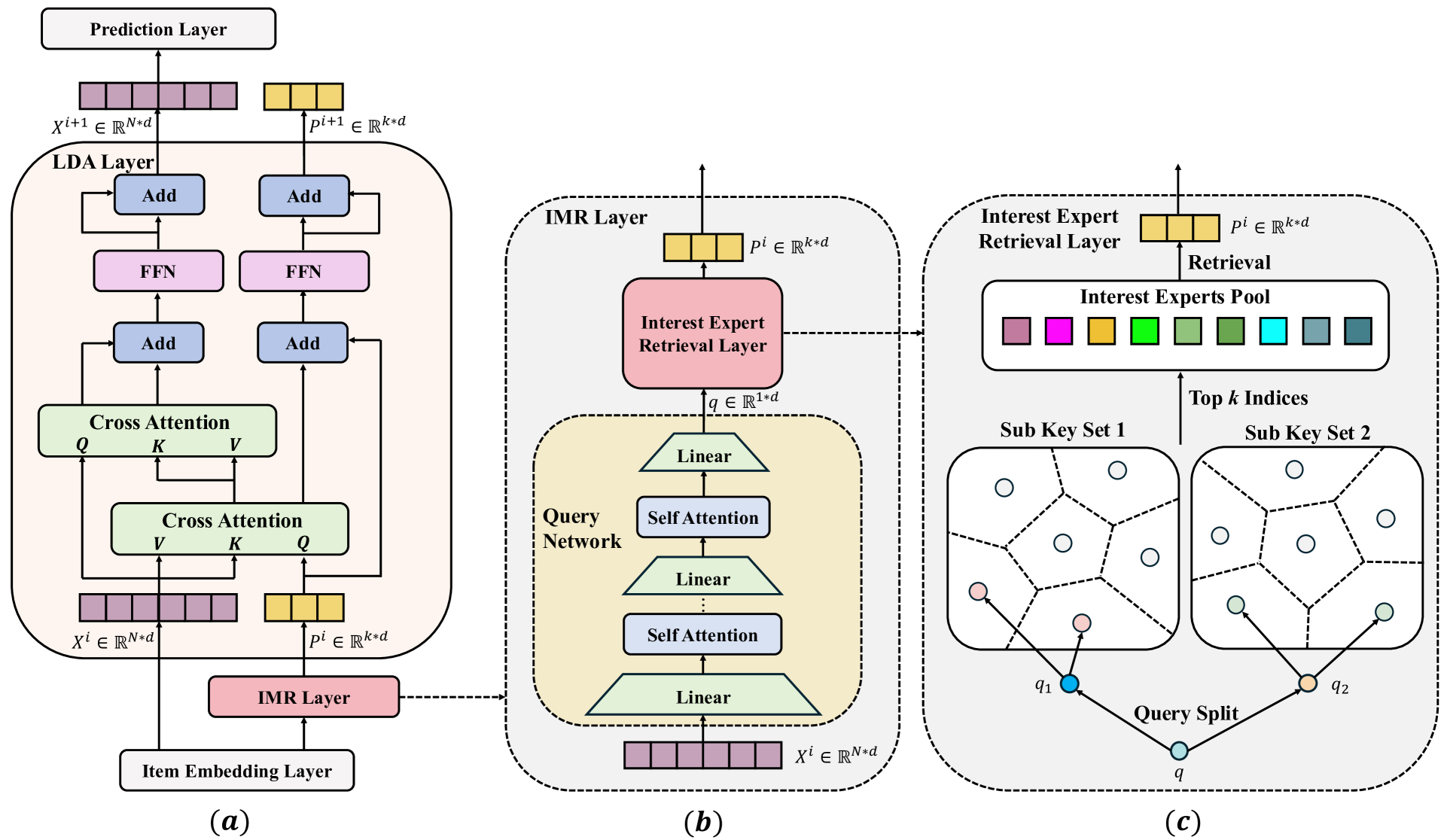
技术框架:ELASTIC主要包含三个模块:1) 线性Dispatcher注意力机制:将长序列压缩成固定长度的兴趣专家表示。2) 兴趣记忆库:存储大量可学习的兴趣向量。3) 兴趣检索模块:从兴趣记忆库中检索与压缩后的用户兴趣相关的向量。整体流程是,首先使用线性Dispatcher注意力机制压缩用户行为序列,然后利用压缩后的表示从兴趣记忆库中检索相关的兴趣向量,最后将检索到的兴趣向量用于后续的推荐任务。
关键创新:ELASTIC的关键创新在于:1) 提出了线性Dispatcher注意力机制,将自注意力机制的复杂度从平方级别降低到线性级别,从而能够处理更长的用户行为序列。2) 引入了兴趣记忆库,用于存储丰富的用户兴趣表示,增强模型对用户多样化兴趣的建模能力。3) 将序列压缩和兴趣检索相结合,在降低计算复杂度的同时,保持了模型对用户兴趣的建模能力。
关键设计:线性Dispatcher注意力机制使用固定的长度的兴趣专家,每个专家负责捕捉用户序列中特定类型的兴趣。Dispatcher根据用户序列的Query向量,将不同的序列片段分配给不同的兴趣专家。兴趣记忆库初始化为一个大的可学习的向量集合,通过计算压缩后的用户表示与记忆库中向量的相似度,选择Top-K个最相关的向量作为检索结果。损失函数包括推荐任务的损失和用于训练兴趣记忆库的辅助损失。
🖼️ 关键图片


📊 实验亮点
实验结果表明,ELASTIC在多个公共数据集上显著优于基线模型。例如,在某个数据集上,ELASTIC相比于最好的基线模型,在HR@10指标上提升了5%,在NDCG@10指标上提升了4%。此外,ELASTIC还大幅降低了GPU内存占用和推理时间,相比于Transformer,ELASTIC可以减少高达90%的GPU内存使用,并加速2.7倍的推理速度。
🎯 应用场景
ELASTIC适用于需要处理长序列数据的推荐系统,例如电商、视频、新闻等领域。它可以有效地建模用户的长期行为,提升推荐的准确性和效率。此外,ELASTIC的线性复杂度使其能够部署在资源受限的设备上,例如移动设备和嵌入式系统。未来,ELASTIC可以扩展到其他序列建模任务,例如自然语言处理和时间序列预测。
📄 摘要(原文)
State-of-the-art sequential recommendation models heavily rely on transformer's attention mechanism. However, the quadratic computational and memory complexities of self attention have limited its scalability for modeling users' long range behaviour sequences. To address this problem, we propose ELASTIC, an Efficient Linear Attention for SequenTial Interest Compression, requiring only linear time complexity and decoupling model capacity from computational cost. Specifically, ELASTIC introduces a fixed length interest experts with linear dispatcher attention mechanism which compresses the long-term behaviour sequences to a significantly more compact representation which reduces up to 90% GPU memory usage with x2.7 inference speed up. The proposed linear dispatcher attention mechanism significantly reduces the quadratic complexity and makes the model feasible for adequately modeling extremely long sequences. Moreover, in order to retain the capacity for modeling various user interests, ELASTIC initializes a vast learnable interest memory bank and sparsely retrieves compressed user's interests from the memory with a negligible computational overhead. The proposed interest memory retrieval technique significantly expands the cardinality of available interest space while keeping the same computational cost, thereby striking a trade-off between recommendation accuracy and efficiency. To validate the effectiveness of our proposed ELASTIC, we conduct extensive experiments on various public datasets and compare it with several strong sequential recommenders. Experimental results demonstrate that ELASTIC consistently outperforms baselines by a significant margin and also highlight the computational efficiency of ELASTIC when modeling long sequences. We will make our implementation code publicly available.