An Efficient and Explanatory Image and Text Clustering System with Multimodal Autoencoder Architecture
作者: Tiancheng Shi, Yuanchen Wei, John R. Kender
分类: cs.MM, cs.AI, cs.CV, cs.LG
发布日期: 2024-08-14
💡 一句话要点
提出基于多模态自编码器的图像文本聚类系统,用于分析不同文化对国际新闻事件的解读。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 自编码器 视频理解 文本聚类 LLM 跨文化分析 新闻事件分析
📋 核心要点
- 现有方法缺乏有效整合图像和文本信息,并提供可解释的聚类结果的能力,限制了对多模态新闻事件的深入理解。
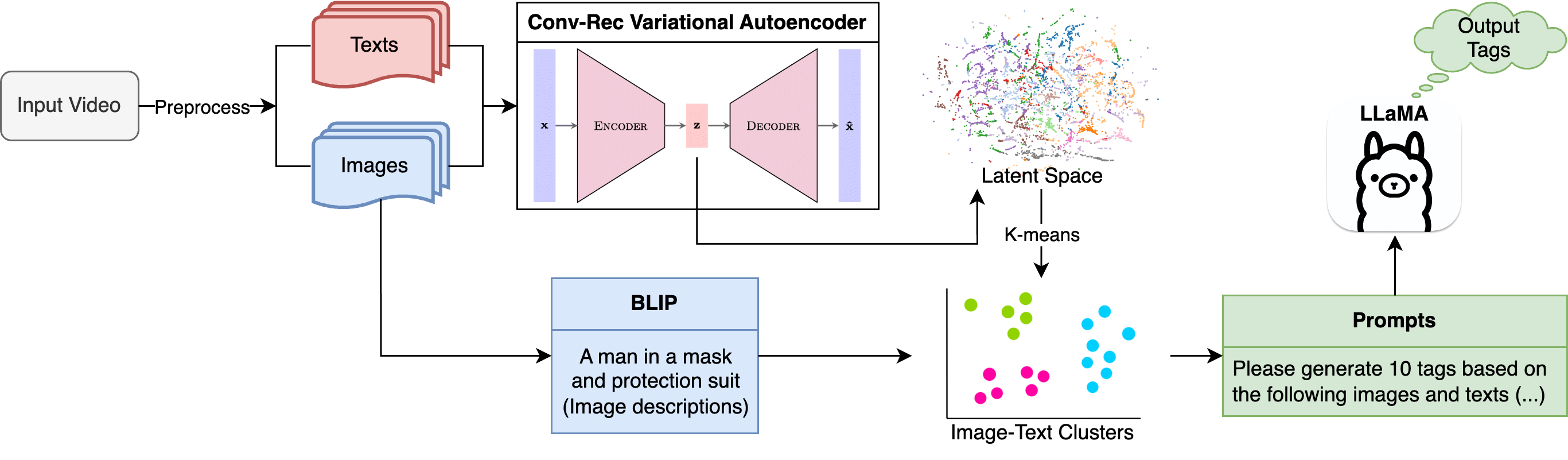
- 提出一种新的卷积-循环变分自编码器(CRVAE),结合CNN和LSTM编码,有效融合视频帧和相关文本信息,学习多模态数据的潜在表示。
- 构建包含帧-字幕对齐、潜在空间聚类和LLM聚类解释器的完整系统,能够将视频总结为主题集群,并提供LLM生成的主题描述。
📝 摘要(中文)
本文展示了对自编码器和LLM解释器进行扩展后,在比较不同文化对同一国际新闻事件的不同解读这一新颖场景下的效率和解释能力。我们开发了一种新的卷积-循环变分自编码器(CRVAE)模型,通过使用全连接潜在层并行嵌入视频帧的CNN编码以及来自音频的相关文本的LSTM编码,扩展了先前CVAE模型的多模态能力。我们将该模型集成到一个更大的系统中,该系统包括帧-字幕对齐、潜在空间向量聚类和一个新的基于LLM的聚类解释器。我们测量、调整并将该系统应用于将视频总结为三到五个主题集群的任务,每个主题由十个LLM生成的短语描述。我们将该系统应用于两个新闻主题:COVID-19和冬季奥运会,另外五个主题正在进行中。
🔬 方法详解
问题定义:现有方法在处理多模态数据(如视频和文本)时,难以有效地融合不同模态的信息,并且缺乏对聚类结果的解释能力。特别是在分析不同文化背景下对同一新闻事件的解读时,需要一个能够同时处理图像和文本信息,并提供可解释主题摘要的系统。
核心思路:论文的核心思路是利用多模态自编码器学习视频帧和相关文本的联合潜在表示,然后对潜在空间进行聚类,最后使用LLM对每个聚类进行解释。通过这种方式,可以有效地提取视频中的主题,并提供可解释的摘要。
技术框架:该系统包含以下几个主要模块:1) 帧-字幕对齐模块,用于将视频帧和对应的文本描述对齐;2) CRVAE模型,用于学习视频帧和文本的联合潜在表示;3) 潜在空间聚类模块,用于对潜在空间中的向量进行聚类;4) LLM聚类解释器,用于生成每个聚类的文本描述。整体流程是从视频中提取帧和字幕,然后通过CRVAE编码到潜在空间,对潜在空间进行聚类,最后使用LLM生成每个聚类的解释。
关键创新:该论文的关键创新在于提出了CRVAE模型,该模型能够有效地融合视频帧的CNN编码和文本的LSTM编码,学习多模态数据的联合潜在表示。此外,该系统还引入了LLM聚类解释器,能够提供对聚类结果的可解释描述。
关键设计:CRVAE模型使用CNN提取视频帧的特征,使用LSTM提取文本的特征,然后通过全连接层将两种特征融合到潜在空间。损失函数包括重构损失和KL散度损失,用于保证潜在空间的平滑性和可解释性。LLM聚类解释器使用prompt engineering技术,生成每个聚类的文本描述。
🖼️ 关键图片


📊 实验亮点
论文构建的系统能够将视频总结为三到五个主题集群,并为每个主题生成十个LLM描述短语。该系统已成功应用于COVID-19和冬季奥运会两个新闻主题,并正在进行其他五个主题的实验。实验结果表明,该系统能够有效地提取视频中的主题,并提供可解释的摘要。
🎯 应用场景
该研究成果可应用于新闻事件分析、视频内容理解、跨文化交流研究等领域。通过自动提取视频中的主题并提供可解释的摘要,可以帮助用户快速了解视频内容,并促进不同文化背景下的交流和理解。未来可扩展到其他多模态数据分析场景,如社交媒体内容分析、医学影像诊断等。
📄 摘要(原文)
We demonstrate the efficiencies and explanatory abilities of extensions to the common tools of Autoencoders and LLM interpreters, in the novel context of comparing different cultural approaches to the same international news event. We develop a new Convolutional-Recurrent Variational Autoencoder (CRVAE) model that extends the modalities of previous CVAE models, by using fully-connected latent layers to embed in parallel the CNN encodings of video frames, together with the LSTM encodings of their related text derived from audio. We incorporate the model within a larger system that includes frame-caption alignment, latent space vector clustering, and a novel LLM-based cluster interpreter. We measure, tune, and apply this system to the task of summarizing a video into three to five thematic clusters, with each theme described by ten LLM-produced phrases. We apply this system to two news topics, COVID-19 and the Winter Olympics, and five other topics are in progress.