Improving Global Parameter-sharing in Physically Heterogeneous Multi-agent Reinforcement Learning with Unified Action Space
作者: Xiaoyang Yu, Youfang Lin, Shuo Wang, Kai Lv, Sheng Han
分类: cs.MA, cs.AI
发布日期: 2024-08-14
💡 一句话要点
针对物理异构多智能体强化学习,提出统一动作空间以提升全局参数共享效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 物理异构 统一动作空间 参数共享 动作语义 跨组逆损失 SMAC环境
📋 核心要点
- 现有MARL算法在异构智能体间盲目全局参数共享,忽略了动作语义差异,导致协作性能下降。
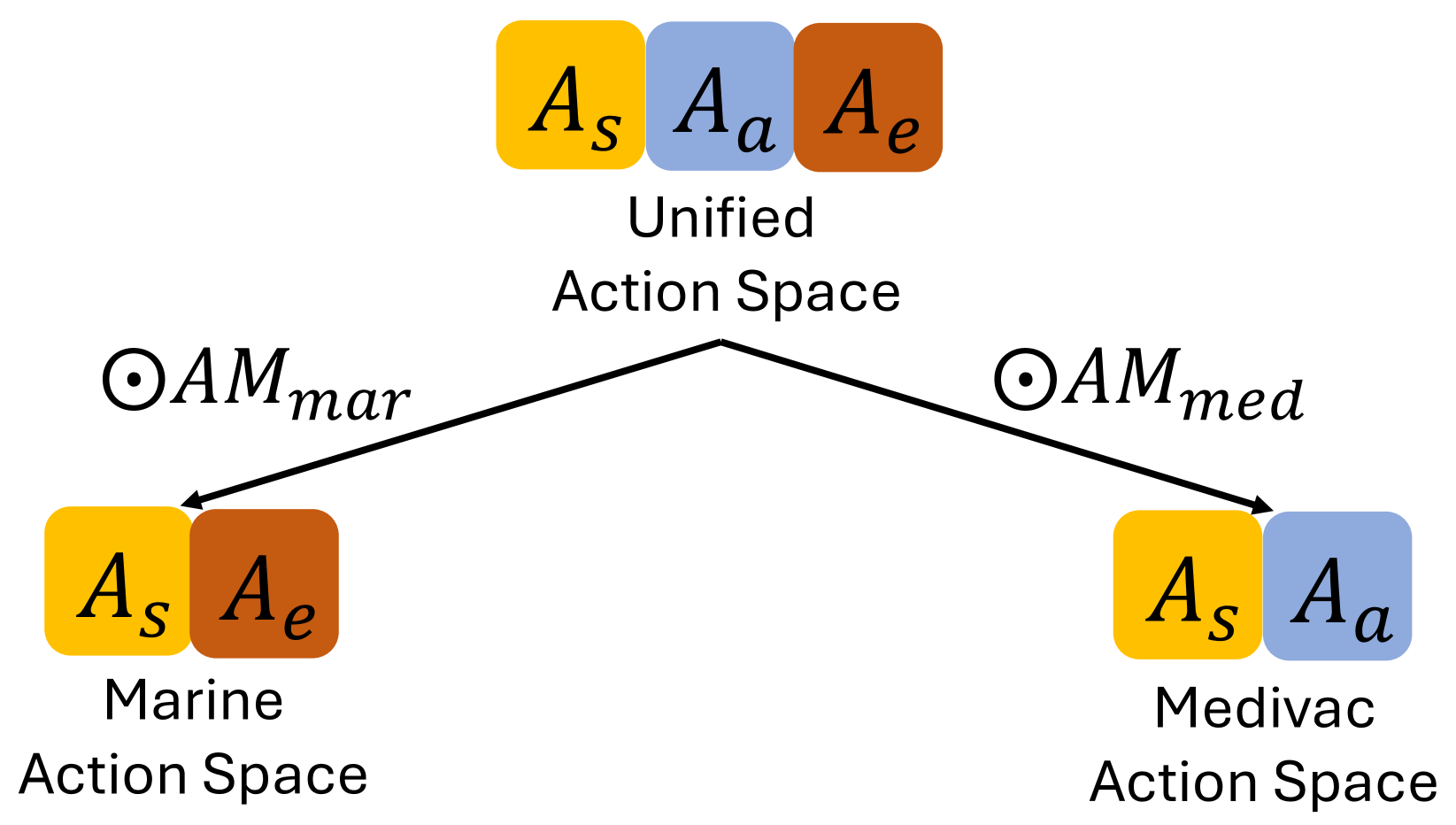
- 提出统一动作空间(UAS)方法,允许智能体在统一空间中学习表示,再通过掩码生成异构动作策略。
- 实验表明,UAS方法在SMAC环境中,显著提升了U-QMIX和U-MAPPO算法的性能,优于现有方法。
📝 摘要(中文)
在多智能体系统(MAS)中,动作语义指示了智能体动作对其他实体的影响,可用于在物理异构MAS中对智能体进行分组。以往的多智能体强化学习(MARL)算法在不同类型的异构智能体之间应用全局参数共享,而没有仔细区分不同的动作语义,这降低了复杂情况下智能体之间的合作和协调。然而,完全独立的智能体参数会显著增加计算成本和训练难度。为了受益于不同动作语义的使用,同时保持适当的参数共享结构,我们引入了统一动作空间(UAS)来满足这一需求。UAS是具有不同语义的所有智能体动作的并集。所有智能体首先在UAS中计算其统一表示,然后使用不同的可用动作掩码生成其异构动作策略。为了进一步改进额外UAS参数的训练,我们引入了跨组逆(CGI)损失,以利用轨迹信息预测其他组的智能体策略。作为解决物理异构MARL问题的通用方法,我们将UAS添加到基于值和基于策略的MARL算法中,并提出了两种实用的算法:U-QMIX和U-MAPPO。在SMAC环境中的实验结果证明了U-QMIX和U-MAPPO与几种最先进的MARL方法相比的有效性。
🔬 方法详解
问题定义:论文旨在解决物理异构多智能体强化学习中,由于智能体动作语义不同,全局参数共享策略导致协作效率低下的问题。现有方法要么盲目共享参数,忽略了动作语义的差异,要么完全独立参数,导致计算成本过高和训练困难。
核心思路:核心思路是引入统一动作空间(UAS),将所有智能体的动作空间统一到一个更大的空间中。每个智能体在这个统一空间中学习表示,然后通过一个动作掩码(available-action-mask)来选择其可执行的动作,从而生成异构的动作策略。这样既能利用参数共享的优势,又能区分不同智能体的动作语义。
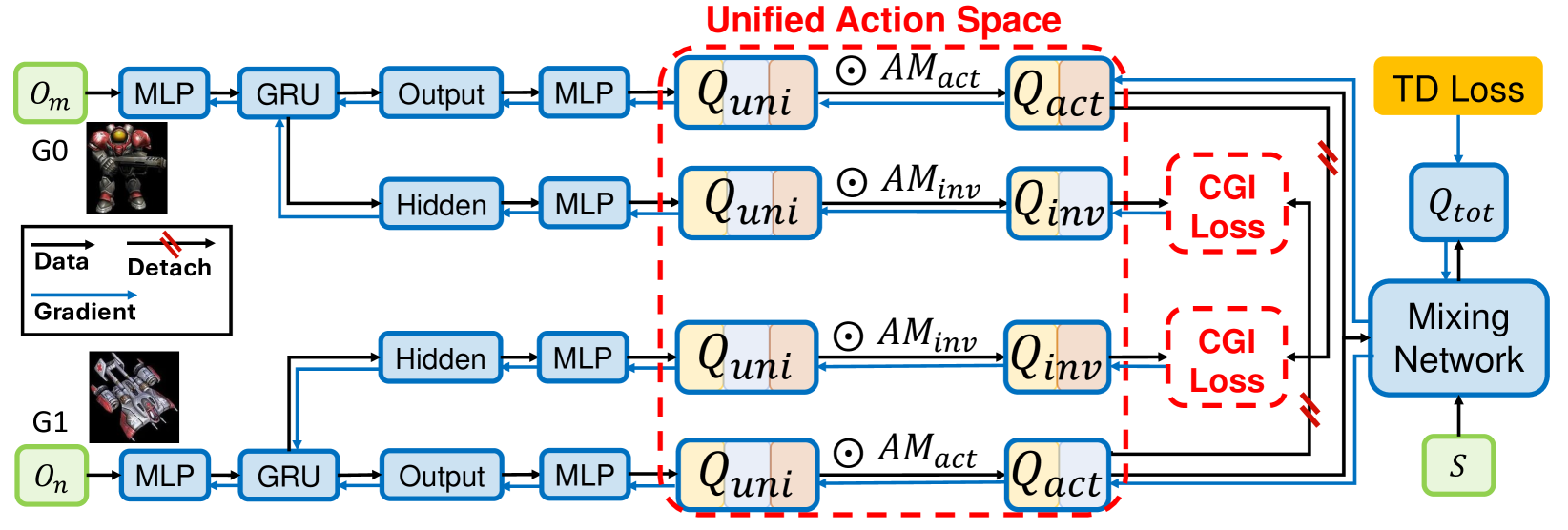
技术框架:整体框架包含以下几个主要步骤:1. 所有智能体观察环境状态。2. 每个智能体在统一动作空间(UAS)中计算其动作表示。3. 每个智能体根据自身类型和环境状态,应用动作掩码,选择可执行的动作。4. 执行选择的动作,并获得奖励和新的环境状态。5. 使用MARL算法(如QMIX或MAPPO)更新策略网络。6. 使用跨组逆(CGI)损失来进一步训练UAS参数。
关键创新:最重要的技术创新点是统一动作空间(UAS)的设计和跨组逆(CGI)损失的引入。UAS允许智能体在统一的空间中学习表示,从而实现参数共享,同时通过动作掩码区分不同智能体的动作语义。CGI损失则通过预测其他组的智能体策略,来进一步提升UAS参数的训练效果。与现有方法的本质区别在于,UAS方法在参数共享和动作异构性之间找到了一个平衡点。
关键设计:关键设计包括:1. 统一动作空间(UAS)的构建,需要合理定义统一空间中的动作表示。2. 动作掩码的设计,需要准确反映每个智能体可执行的动作集合。3. 跨组逆(CGI)损失的设计,需要选择合适的损失函数和目标策略。CGI损失的具体形式为:通过当前智能体的状态和动作,预测其他组智能体的策略,并最小化预测策略与真实策略之间的差异。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在SMAC环境中,U-QMIX和U-MAPPO算法均优于现有的MARL算法。例如,在某些复杂场景下,U-QMIX的胜率比QMIX提高了10%以上,U-MAPPO的平均奖励也显著高于MAPPO。这些结果验证了UAS方法在提升物理异构多智能体系统协作性能方面的有效性。
🎯 应用场景
该研究成果可应用于各种物理异构多智能体系统,例如机器人协同、交通调度、资源分配等领域。通过提升智能体之间的协作效率,可以显著提高系统的整体性能和鲁棒性。未来,该方法有望在更复杂的异构环境中得到应用,例如包含人类智能体的混合智能体系统。
📄 摘要(原文)
In a multi-agent system (MAS), action semantics indicates the different influences of agents' actions toward other entities, and can be used to divide agents into groups in a physically heterogeneous MAS. Previous multi-agent reinforcement learning (MARL) algorithms apply global parameter-sharing across different types of heterogeneous agents without careful discrimination of different action semantics. This common implementation decreases the cooperation and coordination between agents in complex situations. However, fully independent agent parameters dramatically increase the computational cost and training difficulty. In order to benefit from the usage of different action semantics while also maintaining a proper parameter-sharing structure, we introduce the Unified Action Space (UAS) to fulfill the requirement. The UAS is the union set of all agent actions with different semantics. All agents first calculate their unified representation in the UAS, and then generate their heterogeneous action policies using different available-action-masks. To further improve the training of extra UAS parameters, we introduce a Cross-Group Inverse (CGI) loss to predict other groups' agent policies with the trajectory information. As a universal method for solving the physically heterogeneous MARL problem, we implement the UAS adding to both value-based and policy-based MARL algorithms, and propose two practical algorithms: U-QMIX and U-MAPPO. Experimental results in the SMAC environment prove the effectiveness of both U-QMIX and U-MAPPO compared with several state-of-the-art MARL methods.