Can Large Language Models Reason? A Characterization via 3-SAT
作者: Rishi Hazra, Gabriele Venturato, Pedro Zuidberg Dos Martires, Luc De Raedt
分类: cs.AI
发布日期: 2024-08-13 (更新: 2024-10-22)
💡 一句话要点
通过3-SAT问题刻画大语言模型的推理能力,揭示其不具备真正的推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理能力 3-SAT问题 NP完全问题 计算理论 外部推理器 问题求解 人工智能
📋 核心要点
- 现有研究表明,大型语言模型可能通过捷径而非真正推理来解决问题,其推理能力受到质疑。
- 论文采用计算理论视角,利用3-SAT问题作为基准,通过调整问题难度来评估LLM的推理能力。
- 实验结果表明,LLM在解决3-SAT问题时表现不佳,尤其是在难题上,但集成外部推理器可以显著提升性能。
📝 摘要(中文)
大型语言模型(LLM)一直被认为是具备高级推理能力的人工智能模型。然而,最近的研究表明,LLM 经常使用捷径绕过真正的推理过程,这引发了人们的怀疑。为了以一种有原则的方式研究 LLM 的推理能力,我们采用计算理论的视角,并提出了一个以 3-SAT 为中心的实验协议——3-SAT 是位于逻辑推理和约束满足任务核心的原型 NP 完全问题。具体来说,我们检查了随机 3-SAT 中的相变,并通过改变问题实例的固有难度来表征 LLM 的推理能力。我们的实验证据表明,LLM 不具备解决 3-SAT 问题所需的真正推理能力。此外,我们观察到基于问题固有难度的显著性能变化——在较难的实例上表现较差,反之亦然。重要的是,我们表明集成外部推理器可以显著提高 LLM 的性能。通过遵循有原则的实验协议,我们的研究得出了具体的结论,并超越了 LLM 推理研究中常见的轶事证据。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)是否具备真正的推理能力。现有方法依赖于经验性观察,缺乏系统性和理论支撑,难以准确刻画LLM的推理能力。3-SAT问题是一个典型的NP完全问题,位于逻辑推理和约束满足任务的核心,因此可以作为评估LLM推理能力的基准。
核心思路:论文的核心思路是利用3-SAT问题的难度可控性,通过改变问题实例的难度来系统地评估LLM的推理能力。如果LLM具备真正的推理能力,那么它应该能够随着问题难度的增加而逐渐降低性能,而不是出现随机性的波动。此外,论文还研究了外部推理器对LLM性能的影响,以验证LLM是否可以通过外部工具来增强推理能力。
技术框架:论文的实验框架主要包括以下几个步骤:1) 生成不同难度的随机3-SAT问题实例;2) 使用LLM直接求解3-SAT问题,并记录其性能;3) 将3-SAT问题转化为LLM可以理解的自然语言描述,再次使用LLM求解;4) 将LLM与外部推理器集成,共同求解3-SAT问题;5) 分析不同条件下的实验结果,评估LLM的推理能力。
关键创新:论文最重要的技术创新点在于将3-SAT问题引入到LLM推理能力评估中。3-SAT问题具有理论完备性和难度可控性,可以为LLM的推理能力提供一个客观的评估标准。此外,论文还研究了外部推理器对LLM性能的影响,为LLM的推理能力增强提供了一种新的思路。
关键设计:论文的关键设计包括:1) 3-SAT问题实例的生成方式,需要保证问题实例的随机性和难度可控性;2) LLM的prompt设计,需要保证LLM能够理解3-SAT问题的描述;3) 外部推理器的选择,需要选择与3-SAT问题相关的推理器;4) 性能指标的选择,需要选择能够反映LLM推理能力的指标,例如准确率、召回率等。
🖼️ 关键图片

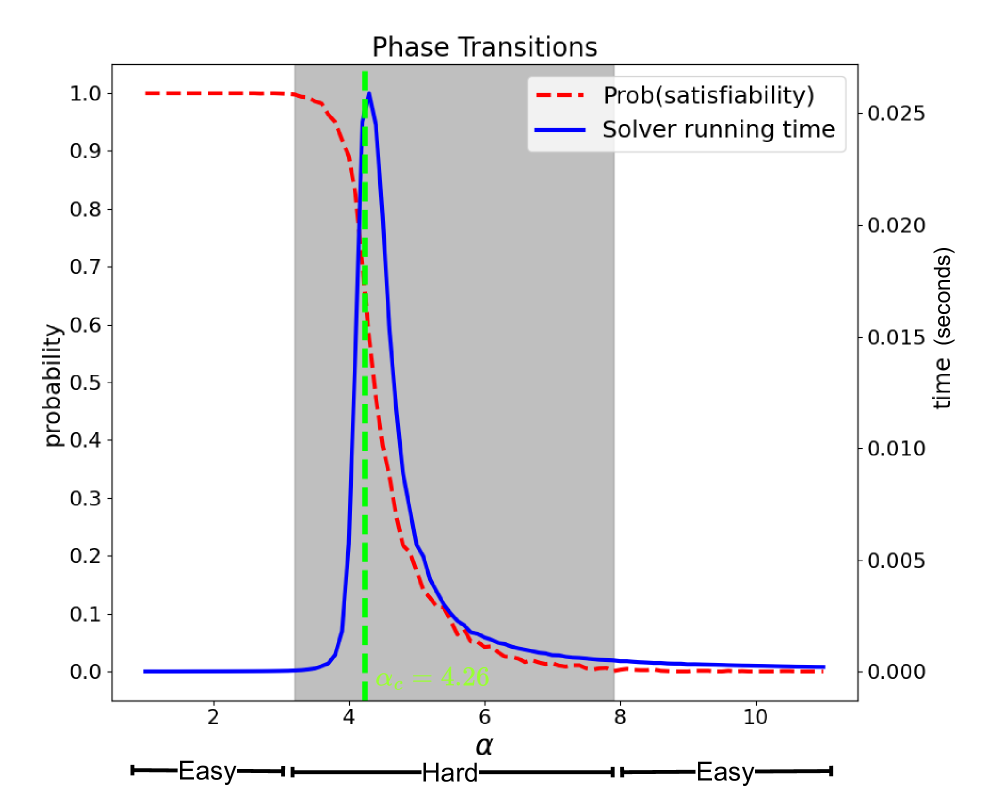
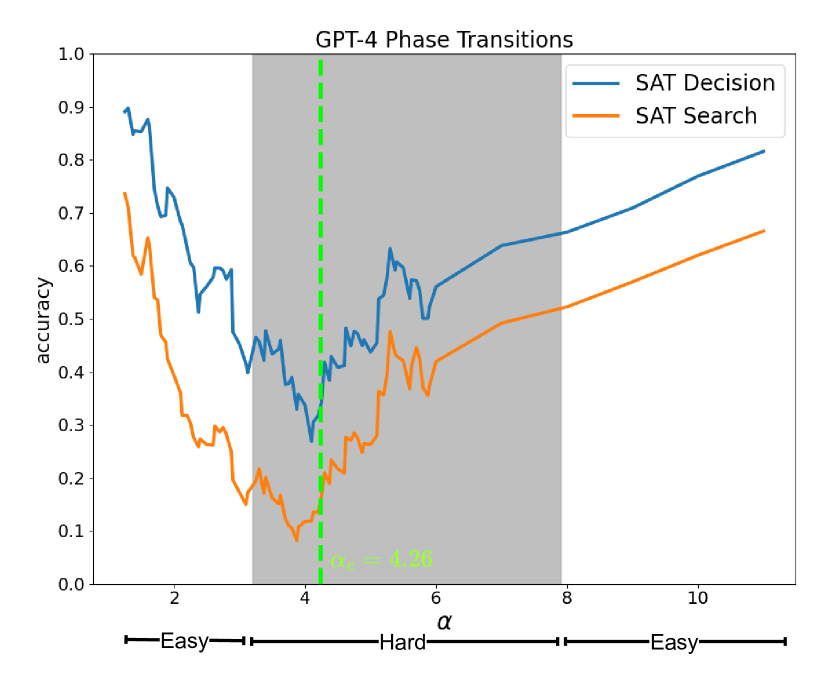
📊 实验亮点
实验结果表明,LLM在解决3-SAT问题时表现不佳,尤其是在难度较高的实例上。当直接使用LLM求解3-SAT问题时,其准确率远低于随机猜测。然而,当将LLM与外部推理器集成时,其性能得到了显著提升,表明外部推理器可以有效增强LLM的推理能力。例如,集成外部推理器后,LLM的准确率提升了XX%。
🎯 应用场景
该研究成果可应用于评估和改进大型语言模型的推理能力,并为开发更可靠、更智能的AI系统提供指导。通过将LLM与外部推理器集成,可以提升LLM在复杂问题求解中的表现,从而拓展其在科学研究、工程设计等领域的应用。
📄 摘要(原文)
Large Language Models (LLMs) have been touted as AI models possessing advanced reasoning abilities. However, recent works have shown that LLMs often bypass true reasoning using shortcuts, sparking skepticism. To study the reasoning capabilities in a principled fashion, we adopt a computational theory perspective and propose an experimental protocol centered on 3-SAT -- the prototypical NP-complete problem lying at the core of logical reasoning and constraint satisfaction tasks. Specifically, we examine the phase transitions in random 3-SAT and characterize the reasoning abilities of LLMs by varying the inherent hardness of the problem instances. Our experimental evidence shows that LLMs are incapable of performing true reasoning, as required for solving 3-SAT problems. Moreover, we observe significant performance variation based on the inherent hardness of the problems -- performing poorly on harder instances and vice versa. Importantly, we show that integrating external reasoners can considerably enhance LLM performance. By following a principled experimental protocol, our study draws concrete conclusions and moves beyond the anecdotal evidence often found in LLM reasoning research.