Agent Q: Advanced Reasoning and Learning for Autonomous AI Agents
作者: Pranav Putta, Edmund Mills, Naman Garg, Sumeet Motwani, Chelsea Finn, Divyansh Garg, Rafael Rafailov
分类: cs.AI, cs.LG
发布日期: 2024-08-13
💡 一句话要点
Agent Q:结合蒙特卡洛树搜索与偏好优化的自主AI Agent推理与学习框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自主Agent 大型语言模型 蒙特卡洛树搜索 直接偏好优化 强化学习 交互式环境 WebShop
📋 核心要点
- 现有方法难以使LLM agent在动态环境中进行复杂决策,监督微调易受复合误差和探索数据限制。
- Agent Q结合引导式MCTS、自我批评和离策略DPO,使agent能从成功和失败经验中学习。
- 实验表明,Agent Q在WebShop和真实预订场景中显著优于基线,并超越人类水平。
📝 摘要(中文)
大型语言模型(LLMs)在需要复杂推理的自然语言任务中表现出卓越的能力,但它们在交互式环境中进行agentic、多步骤推理的应用仍然是一个难题。传统的在静态数据集上的监督预训练不足以支持自主agent在动态环境中执行复杂决策的能力,例如网页导航。先前通过在精心策划的专家演示上进行监督微调的尝试,通常会遭受复合误差和有限的探索数据,从而导致次优的策略结果。为了克服这些挑战,我们提出了一个框架,该框架结合了引导式蒙特卡洛树搜索(MCTS)与自我批评机制,并使用直接偏好优化(DPO)算法的离策略变体对agent交互进行迭代微调。我们的方法允许LLM agent有效地从成功和不成功的轨迹中学习,从而提高它们在复杂的多步骤推理任务中的泛化能力。我们在WebShop环境中验证了我们的方法——一个模拟的电子商务平台,在该平台中,它始终优于行为克隆和强化微调基线,并且在具备在线搜索能力时击败了平均人类表现。在真实世界的预订场景中,我们的方法将Llama-3 70B模型的零样本性能从18.6%提高到81.7%的成功率(相对增长340%),并且通过在线搜索进一步提高到95.4%。我们相信这代表了自主agent能力的巨大飞跃,为现实世界环境中更复杂和可靠的决策铺平了道路。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在交互式环境中进行复杂、多步骤推理的难题。现有方法,如监督微调,依赖于专家演示,容易受到复合误差的影响,并且探索数据有限,导致agent在动态环境中的决策能力不足。
核心思路:论文的核心思路是结合蒙特卡洛树搜索(MCTS)的规划能力和直接偏好优化(DPO)的强化学习能力,使agent能够从自身的交互经验中学习,并进行自我改进。通过引导式MCTS,agent可以探索更有希望的行动序列;通过DPO,agent可以学习区分成功和失败的轨迹,从而优化策略。
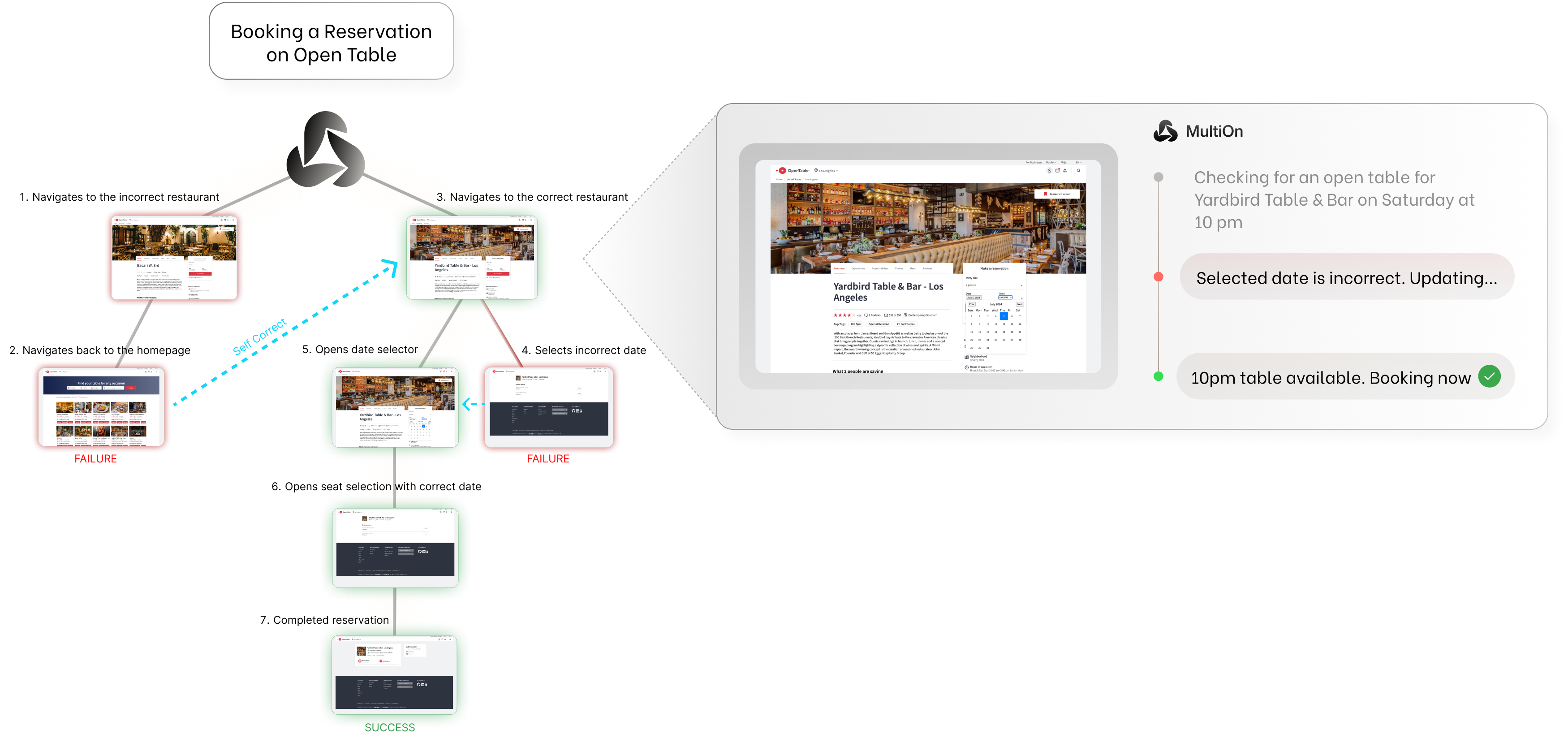
技术框架:Agent Q的整体框架包含以下几个主要模块:1) 引导式蒙特卡洛树搜索(MCTS):用于探索潜在的行动序列,并选择最有希望的行动。2) 自我批评机制:用于评估agent的行动轨迹,并生成反馈信号。3) 离策略直接偏好优化(DPO):用于根据反馈信号优化agent的策略。agent首先使用MCTS进行探索,然后根据自我批评机制的反馈,使用DPO进行策略更新,迭代提升性能。
关键创新:Agent Q的关键创新在于将引导式MCTS与离策略DPO相结合,形成一个闭环的agent学习框架。与传统的监督学习或强化学习方法相比,Agent Q能够更有效地利用agent自身的交互经验,从而提高在复杂环境中的泛化能力。此外,自我批评机制的设计也使得agent能够从失败的经验中学习,进一步提升了学习效率。
关键设计:在MCTS中,使用LLM作为先验知识来指导搜索过程,减少了搜索空间。DPO算法采用离策略的方式,允许agent从历史数据中学习,提高了样本利用率。损失函数的设计目标是最大化成功轨迹的概率,同时最小化失败轨迹的概率。具体参数设置未知。
🖼️ 关键图片

📊 实验亮点
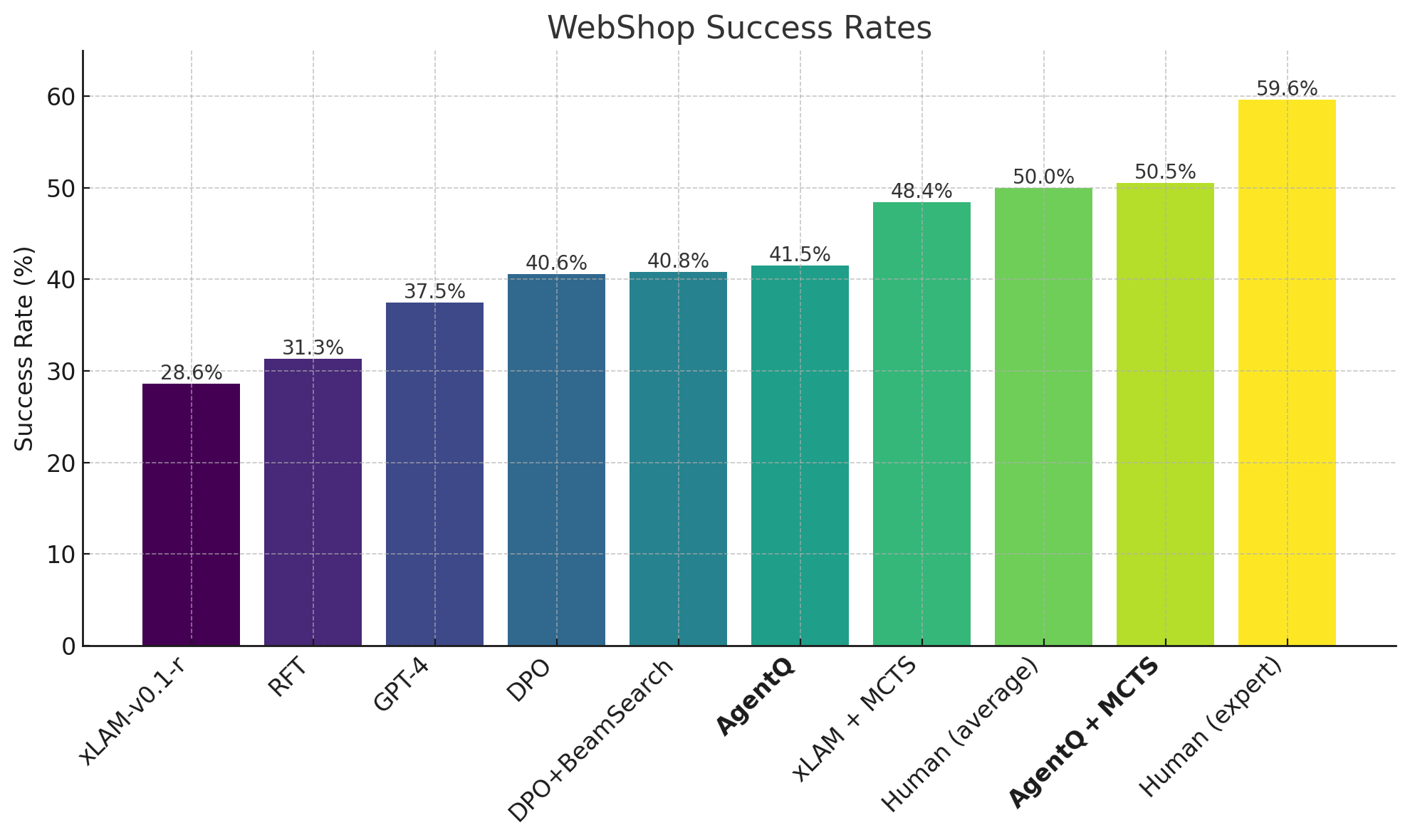
Agent Q 在 WebShop 环境中超越了行为克隆和强化学习基线,并在具备在线搜索能力时击败了平均人类水平。在真实世界的预订场景中,Llama-3 70B 模型的零样本性能从 18.6% 提高到 81.7%(相对增长 340%),通过在线搜索进一步提高到 95.4%。这些结果表明 Agent Q 在复杂任务中具有显著的性能提升。
🎯 应用场景
Agent Q 的研究成果可应用于各种需要自主决策的场景,例如:智能客服、自动化网页浏览、智能家居控制、以及其他需要复杂推理和规划的机器人任务。该研究为构建更智能、更可靠的自主AI agent奠定了基础,具有广阔的应用前景。
📄 摘要(原文)
Large Language Models (LLMs) have shown remarkable capabilities in natural language tasks requiring complex reasoning, yet their application in agentic, multi-step reasoning within interactive environments remains a difficult challenge. Traditional supervised pre-training on static datasets falls short in enabling autonomous agent capabilities needed to perform complex decision-making in dynamic settings like web navigation. Previous attempts to bridge this ga-through supervised fine-tuning on curated expert demonstrations-often suffer from compounding errors and limited exploration data, resulting in sub-optimal policy outcomes. To overcome these challenges, we propose a framework that combines guided Monte Carlo Tree Search (MCTS) search with a self-critique mechanism and iterative fine-tuning on agent interactions using an off-policy variant of the Direct Preference Optimization (DPO) algorithm. Our method allows LLM agents to learn effectively from both successful and unsuccessful trajectories, thereby improving their generalization in complex, multi-step reasoning tasks. We validate our approach in the WebShop environment-a simulated e-commerce platform where it consistently outperforms behavior cloning and reinforced fine-tuning baseline, and beats average human performance when equipped with the capability to do online search. In real-world booking scenarios, our methodology boosts Llama-3 70B model's zero-shot performance from 18.6% to 81.7% success rate (a 340% relative increase) after a single day of data collection and further to 95.4% with online search. We believe this represents a substantial leap forward in the capabilities of autonomous agents, paving the way for more sophisticated and reliable decision-making in real-world settings.