Casper: Prompt Sanitization for Protecting User Privacy in Web-Based Large Language Models
作者: Chun Jie Chong, Chenxi Hou, Zhihao Yao, Seyed Mohammadjavad Seyed Talebi
分类: cs.CR, cs.AI
发布日期: 2024-08-13
DOI: 10.1109/CSCloud66326.2025.00027
💡 一句话要点
Casper:一种用于保护Web LLM用户隐私的Prompt清洗技术
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Prompt清洗 用户隐私保护 大型语言模型 命名实体识别 客户端安全
📋 核心要点
- Web LLM服务及其第三方插件存在隐私风险,敏感prompt数据可能被存储、处理和共享。
- Casper是一种在用户设备上运行的prompt清洗技术,通过多层过滤机制检测并删除敏感信息。
- 实验表明Casper能有效过滤个人身份信息和隐私敏感主题,准确率分别达到98.5%和89.9%。
📝 摘要(中文)
基于Web的大型语言模型(LLM)服务已被广泛采用,成为我们互联网体验的重要组成部分。第三方插件通过访问真实世界的数据和服务来增强LLM的功能。然而,与这些服务及其第三方插件相关的隐私后果尚未得到充分理解。敏感的prompt数据由基于云的LLM提供商和第三方插件存储、处理和共享。在本文中,我们提出了Casper,一种prompt清洗技术,旨在通过在将用户输入发送到LLM服务之前检测并删除敏感信息来保护用户隐私。Casper作为浏览器扩展完全在用户设备上运行,不需要对在线LLM服务进行任何更改。Casper的核心是一个三层清洗机制,包括一个基于规则的过滤器、一个基于机器学习(ML)的命名实体识别器和一个基于浏览器的本地LLM主题标识符。我们在一个包含4000个合成prompt的数据集上评估了Casper,结果表明它可以有效地过滤掉个人身份信息(PII)和隐私敏感主题,准确率分别高达98.5%和89.9%。
🔬 方法详解
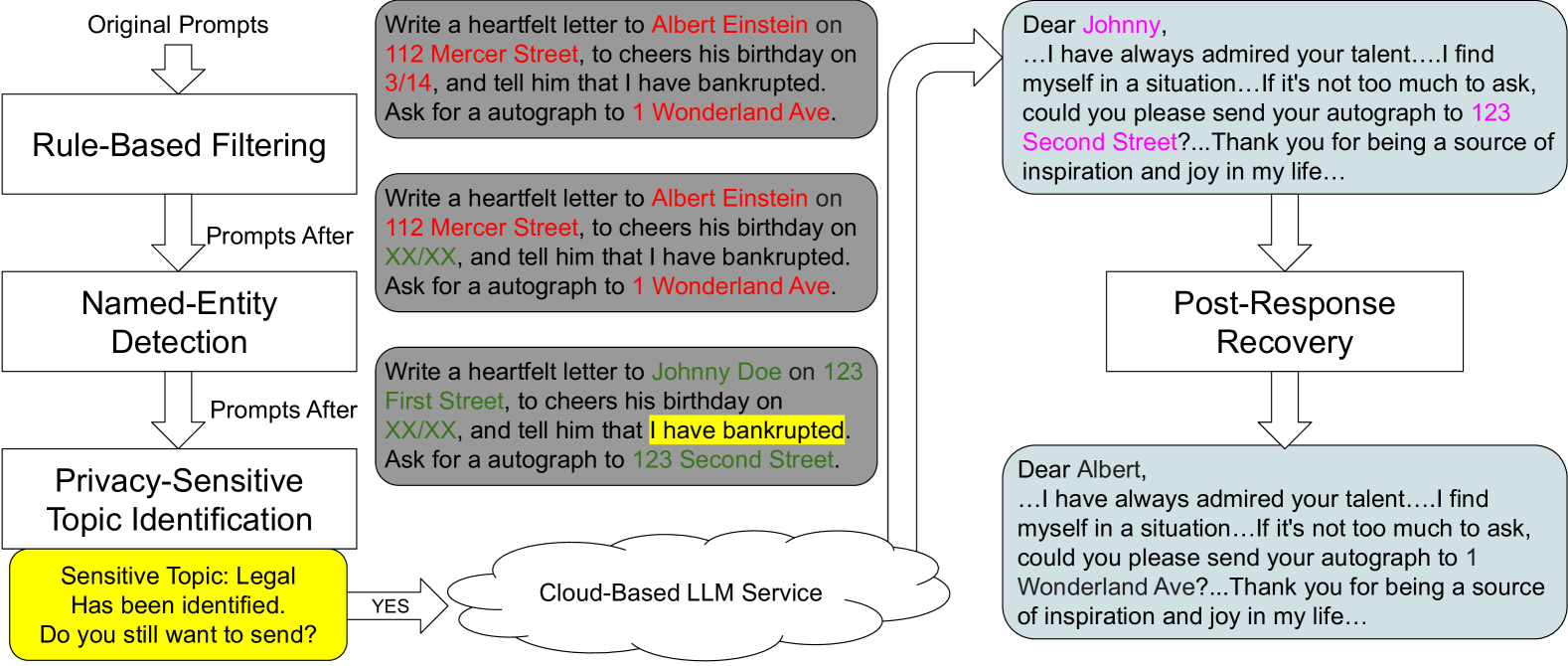
问题定义:Web LLM服务及其第三方插件会收集用户的prompt数据,这些数据可能包含个人身份信息(PII)和隐私敏感信息。现有方法缺乏有效的客户端隐私保护机制,用户隐私面临泄露风险。因此,需要一种在客户端对prompt进行清洗的方法,以保护用户隐私。
核心思路:Casper的核心思路是在用户设备端,通过多层过滤机制对用户输入的prompt进行清洗,在将prompt发送到LLM服务之前,移除其中的敏感信息。这种客户端清洗方法避免了将敏感数据发送到服务器,从而保护了用户隐私。
技术框架:Casper作为一个浏览器扩展运行,包含三个主要模块:1) 基于规则的过滤器:使用预定义的规则和正则表达式来检测和删除常见的PII,如电话号码、电子邮件地址等。2) 基于机器学习的命名实体识别器:使用预训练的命名实体识别模型来识别和删除prompt中的实体,如人名、地名、组织机构名等。3) 基于浏览器的本地LLM主题标识符:使用本地LLM来识别prompt的主题,并根据预定义的隐私敏感主题列表来判断prompt是否包含敏感信息。
关键创新:Casper的关键创新在于其客户端prompt清洗架构,以及多层过滤机制的结合。与传统的服务器端隐私保护方法不同,Casper在客户端进行隐私保护,避免了将敏感数据发送到服务器。此外,Casper结合了基于规则的过滤、基于机器学习的命名实体识别和基于本地LLM的主题识别,从而提高了隐私保护的准确性和覆盖范围。
关键设计:基于规则的过滤器使用预定义的正则表达式匹配常见PII;命名实体识别器使用预训练的BERT模型进行微调;本地LLM主题标识符使用DistilBERT模型,并使用预定义的隐私敏感主题列表进行训练。为了平衡性能和隐私保护效果,Casper在客户端运行,并对模型进行了优化,以减少计算开销。
🖼️ 关键图片


📊 实验亮点
Casper在包含4000个合成prompt的数据集上进行了评估,实验结果表明,Casper能够以98.5%的准确率过滤掉个人身份信息(PII),并以89.9%的准确率过滤掉隐私敏感主题。这些结果表明,Casper是一种有效的prompt清洗技术,可以显著提高Web LLM服务的用户隐私保护水平。
🎯 应用场景
Casper可应用于各种基于Web的LLM服务,例如聊天机器人、文本生成工具等。通过在客户端对用户输入进行清洗,Casper可以有效保护用户隐私,防止敏感信息泄露。该技术还可以应用于企业内部的LLM应用,以满足合规性要求,并降低数据泄露的风险。未来,Casper可以扩展到支持更多语言和更多类型的敏感信息。
📄 摘要(原文)
Web-based Large Language Model (LLM) services have been widely adopted and have become an integral part of our Internet experience. Third-party plugins enhance the functionalities of LLM by enabling access to real-world data and services. However, the privacy consequences associated with these services and their third-party plugins are not well understood. Sensitive prompt data are stored, processed, and shared by cloud-based LLM providers and third-party plugins. In this paper, we propose Casper, a prompt sanitization technique that aims to protect user privacy by detecting and removing sensitive information from user inputs before sending them to LLM services. Casper runs entirely on the user's device as a browser extension and does not require any changes to the online LLM services. At the core of Casper is a three-layered sanitization mechanism consisting of a rule-based filter, a Machine Learning (ML)-based named entity recognizer, and a browser-based local LLM topic identifier. We evaluate Casper on a dataset of 4000 synthesized prompts and show that it can effectively filter out Personal Identifiable Information (PII) and privacy-sensitive topics with high accuracy, at 98.5% and 89.9%, respectively.