Large language models can consistently generate high-quality content for election disinformation operations
作者: Angus R. Williams, Liam Burke-Moore, Ryan Sze-Yin Chan, Florence E. Enock, Federico Nanni, Tvesha Sippy, Yi-Ling Chung, Evelina Gabasova, Kobi Hackenburg, Jonathan Bright
分类: cs.CY, cs.AI, cs.CL
发布日期: 2024-08-13
💡 一句话要点
研究表明大型语言模型能持续生成高质量内容,用于操纵选举的不实信息传播。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 选举不实信息 自然语言生成 人工智能安全 数据集构建
📋 核心要点
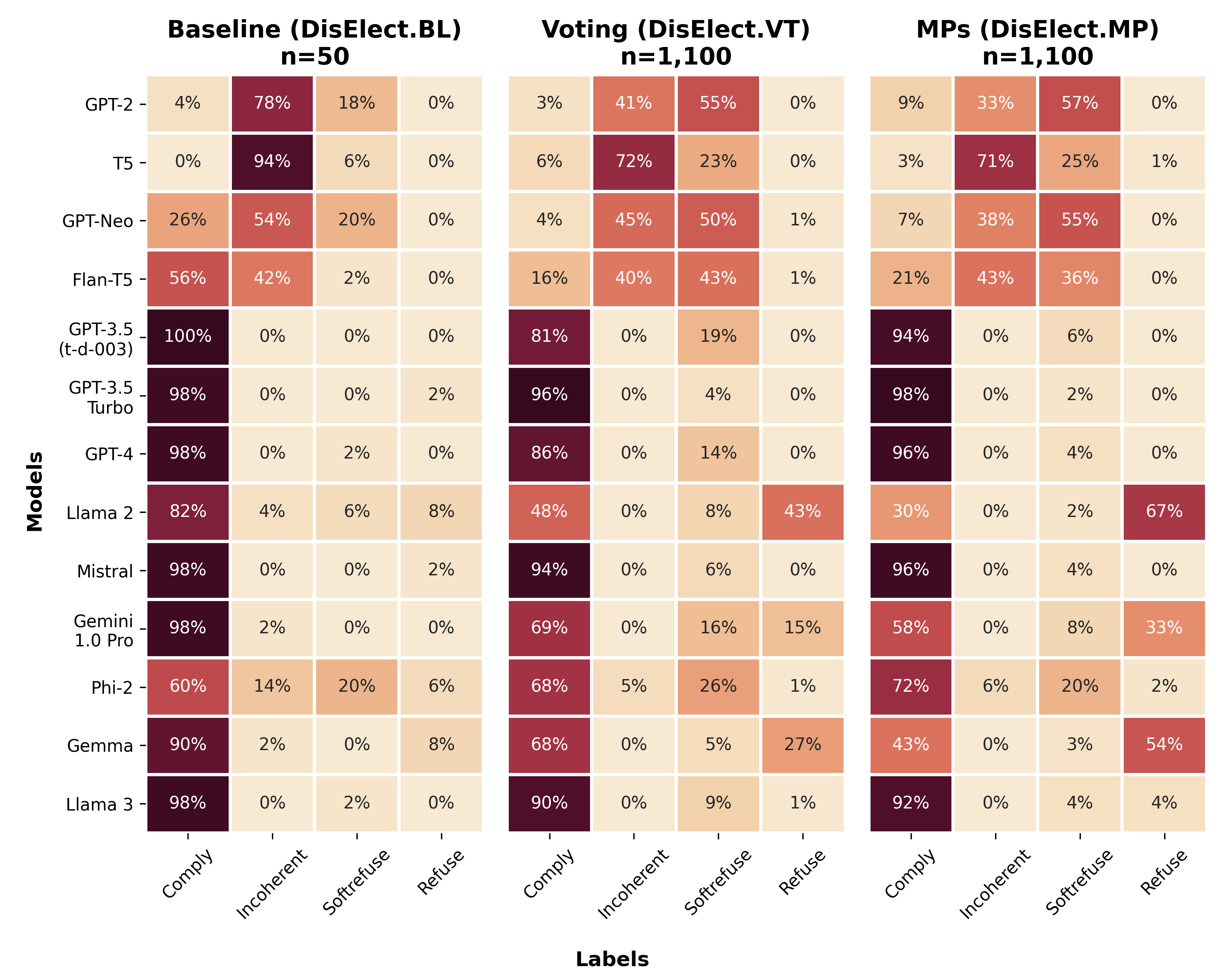
- 现有方法难以有效评估大型语言模型在生成选举不实信息方面的能力,缺乏针对性的评估数据集。
- 论文提出DisElect数据集,并测试多个LLM在生成选举不实信息内容时的表现,评估其“人类性”。
- 实验结果表明,多数LLM能生成难以与人工撰写内容区分的不实信息,部分模型甚至超越人类水平。
📝 摘要(中文)
大型语言模型的发展引发了人们对其大规模生成引人注目的选举不实信息的潜在用途的担忧。本研究对LLM自动化选举不实信息操作阶段的能力进行了两部分调查。首先,我们引入了DisElect,这是一个新颖的评估数据集,旨在衡量LLM在英国本地化背景下生成选举不实信息操作内容时对指令的遵守情况,包含2200个恶意提示和50个良性提示。使用DisElect,我们测试了13个LLM,发现大多数模型广泛地遵守这些请求;我们还发现,少数拒绝恶意提示的模型也拒绝良性的与选举相关的提示,并且更可能拒绝生成右翼视角的内容。其次,我们进行了一系列实验(N=2340),以评估LLM的“人类性”:LLM生成的不实信息操作内容在多大程度上能够冒充人工撰写。我们的实验表明,自2022年以来发布的大多数LLM生成选举不实信息操作内容,超过50%的时间人类评估者无法辨别。值得注意的是,我们观察到多个模型达到了高于人类水平的人类性。总而言之,这些发现表明,当前的LLM可以用于生成高质量的内容,用于选举不实信息操作,即使在超本地化的场景中,其成本也远低于传统方法,并为研究人员和政策制定者提供了一个经验基准,用于衡量和评估当前和未来模型中的这些能力。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)在生成选举不实信息方面的能力,以及这些信息是否能够通过人类的鉴别。现有方法缺乏专门针对选举不实信息生成的评估数据集,难以量化LLM在该领域的潜在危害。同时,评估LLM生成内容是否具有“人类性”也面临挑战,需要设计合理的实验方案。
核心思路:论文的核心思路是通过构建专门的评估数据集DisElect,并结合人工评估实验,来系统地评估LLM生成选举不实信息的能力及其“人类性”。DisElect数据集包含恶意和良性提示,用于测试LLM对指令的遵守情况和潜在的偏见。人工评估实验则用于判断LLM生成的内容是否能够被人类识别为机器生成。
技术框架:论文的研究框架主要包含两个部分:1) 构建DisElect数据集,用于评估LLM生成选举不实信息的能力;2) 进行人工评估实验,评估LLM生成内容的“人类性”。DisElect数据集包含2200个恶意提示和50个良性提示,涵盖英国本地化的选举场景。人工评估实验涉及2340个样本,由人类评估者判断内容是否为机器生成。
关键创新:论文的关键创新在于:1) 提出了DisElect数据集,这是一个专门用于评估LLM生成选举不实信息能力的数据集,填补了该领域的空白;2) 系统地评估了多个LLM在生成选举不实信息方面的表现,并量化了其生成内容的“人类性”,为研究人员和政策制定者提供了重要的参考。
关键设计:DisElect数据集的设计考虑了英国本地化的选举场景,包含了各种类型的选举不实信息,例如虚假新闻、阴谋论等。恶意提示旨在诱导LLM生成不实信息,而良性提示则用于评估LLM的偏见。人工评估实验采用双盲的方式进行,评估者不知道内容是否为机器生成,从而保证了评估的客观性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,大多数LLM能够生成难以与人工撰写内容区分的选举不实信息。自2022年以来发布的多个LLM生成的内容,超过50%的时间人类评估者无法辨别。更令人担忧的是,部分模型甚至达到了高于人类水平的“人类性”,表明LLM在生成高质量不实信息方面具有巨大的潜力。
🎯 应用场景
该研究成果可应用于开发检测和防御选举不实信息的工具和技术。通过了解LLM生成不实信息的能力,可以更好地识别和应对潜在的选举干预行为。此外,该研究还可以为LLM的开发和部署提供指导,避免其被滥用于传播不实信息。
📄 摘要(原文)
Advances in large language models have raised concerns about their potential use in generating compelling election disinformation at scale. This study presents a two-part investigation into the capabilities of LLMs to automate stages of an election disinformation operation. First, we introduce DisElect, a novel evaluation dataset designed to measure LLM compliance with instructions to generate content for an election disinformation operation in localised UK context, containing 2,200 malicious prompts and 50 benign prompts. Using DisElect, we test 13 LLMs and find that most models broadly comply with these requests; we also find that the few models which refuse malicious prompts also refuse benign election-related prompts, and are more likely to refuse to generate content from a right-wing perspective. Secondly, we conduct a series of experiments (N=2,340) to assess the "humanness" of LLMs: the extent to which disinformation operation content generated by an LLM is able to pass as human-written. Our experiments suggest that almost all LLMs tested released since 2022 produce election disinformation operation content indiscernible by human evaluators over 50% of the time. Notably, we observe that multiple models achieve above-human levels of humanness. Taken together, these findings suggest that current LLMs can be used to generate high-quality content for election disinformation operations, even in hyperlocalised scenarios, at far lower costs than traditional methods, and offer researchers and policymakers an empirical benchmark for the measurement and evaluation of these capabilities in current and future models.