BI-MDRG: Bridging Image History in Multimodal Dialogue Response Generation
作者: Hee Suk Yoon, Eunseop Yoon, Joshua Tian Jin Tee, Kang Zhang, Yu-Jung Heo, Du-Seong Chang, Chang D. Yoo
分类: cs.AI, cs.LG, cs.MM
发布日期: 2024-08-12
备注: ECCV 2024
💡 一句话要点
提出BI-MDRG,通过桥接图像历史信息提升多模态对话生成质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态对话生成 图像历史信息 回复一致性 图像文本对齐 对话系统
📋 核心要点
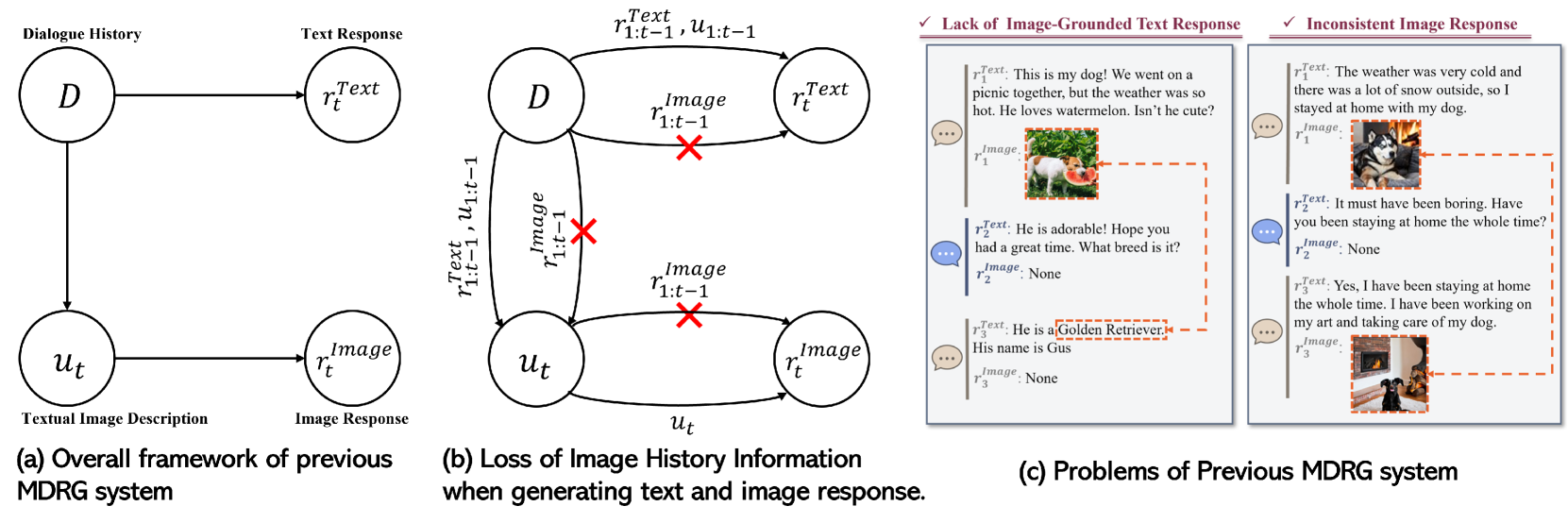
- 现有MDRG方法依赖文本模态作为图像输入输出的中间步骤,忽略了图像的关键信息,导致文本回复与图像内容相关性不足,图像回复对象一致性差。
- BI-MDRG通过桥接图像历史信息,增强文本回复与图像内容的相关性,并提升图像回复中对象在连续对话中的一致性。
- 实验表明,BI-MDRG能有效提升多模态对话质量。同时,论文还构建了一个新的数据集用于评估图像一致性。
📝 摘要(中文)
多模态对话回复生成(MDRG)是一项新兴任务,模型需要根据对话上下文生成文本、图像或两者的混合回复。由于缺乏专门针对此任务的大规模数据集,以及利用强大预训练模型的优势,先前的工作依赖于文本模态作为模型图像输入和输出的中间步骤,而不是采用端到端的方法。然而,这种方法可能会忽略关于图像的关键信息,阻碍1)基于图像的文本回复和2)图像回复中对象的一致性。在本文中,我们提出了BI-MDRG,它桥接了回复生成路径,从而利用图像历史信息来增强文本回复与图像内容的相关性,以及顺序图像回复中对象的一致性。通过在多模态对话基准数据集上的大量实验,我们表明BI-MDRG可以有效地提高多模态对话的质量。此外,认识到用于评估多模态对话中图像一致性的基准数据集的差距,我们创建了一个精心策划的包含300个对话的数据集,并对其进行了注释,以跟踪对话中的对象一致性。
🔬 方法详解
问题定义:多模态对话回复生成任务旨在根据对话历史生成合适的文本、图像或混合回复。现有方法主要依赖文本模态作为图像输入和输出的桥梁,忽略了图像本身的信息,导致生成的文本回复与图像内容关联性不强,并且在连续的图像回复中,对象的一致性难以保证。
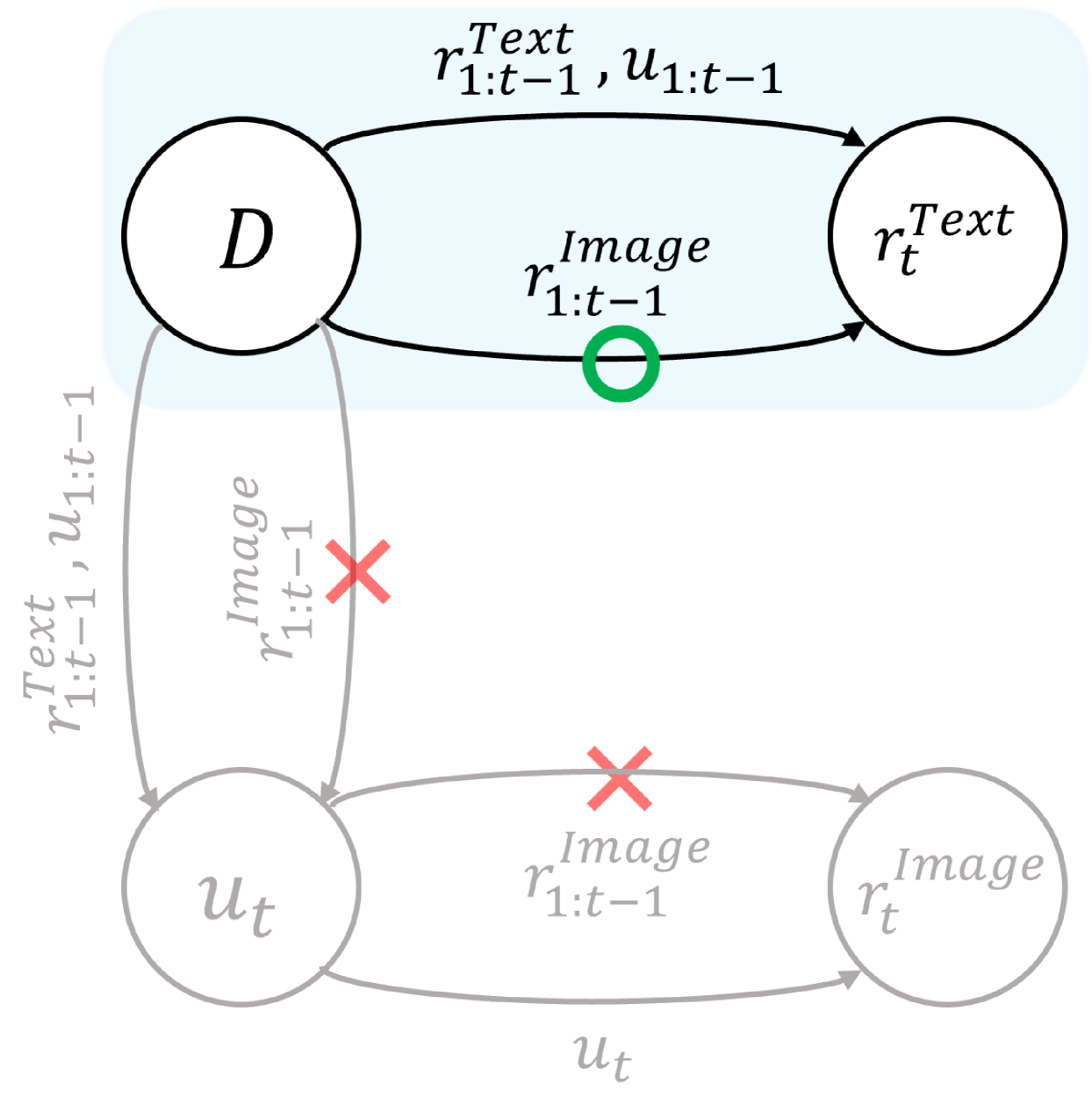
核心思路:BI-MDRG的核心思路是利用图像历史信息来弥补现有方法的不足。通过将图像历史信息融入到回复生成过程中,模型可以更好地理解图像内容,从而生成更相关的文本回复,并保持图像回复中对象的一致性。
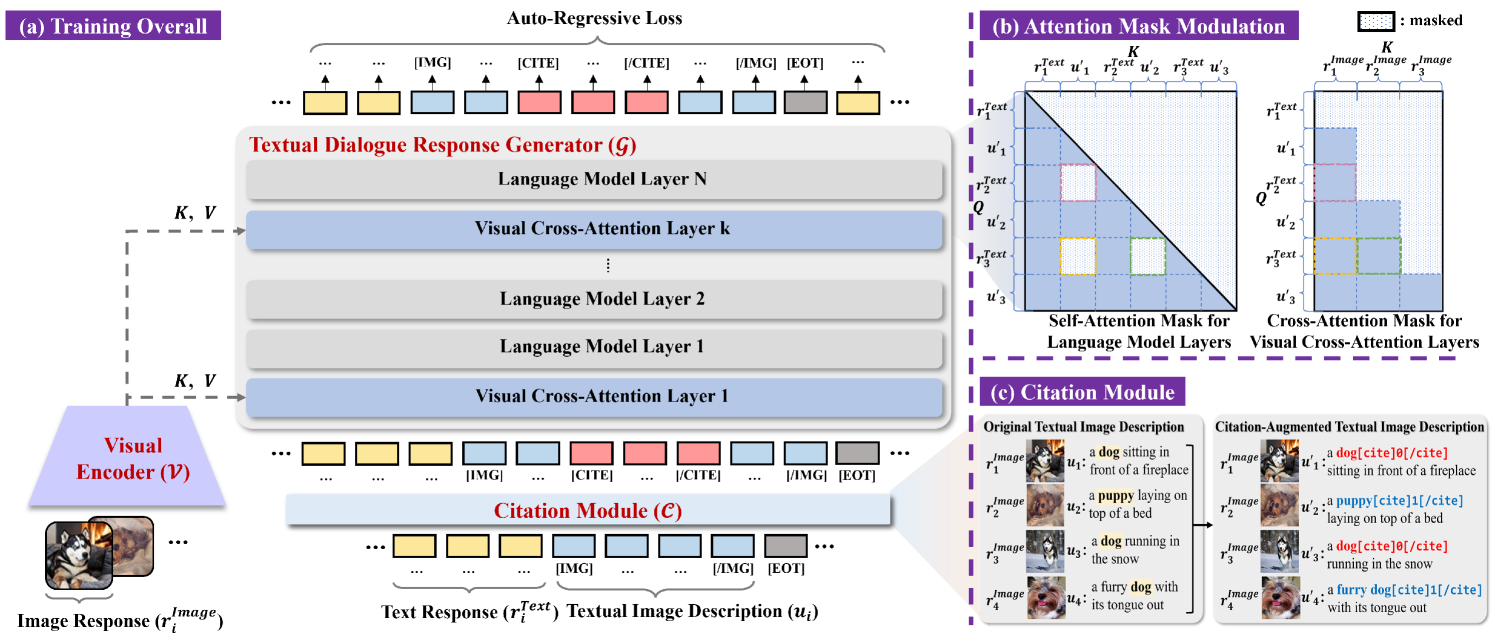
技术框架:BI-MDRG的具体架构未知,但可以推测其包含以下主要模块:1) 对话历史编码器:用于编码对话历史信息;2) 图像历史编码器:用于编码图像历史信息;3) 多模态融合模块:用于融合对话历史和图像历史信息;4) 回复生成器:用于生成文本或图像回复。整体流程是,首先分别编码对话历史和图像历史,然后通过多模态融合模块将二者融合,最后使用回复生成器生成最终的回复。
关键创新:BI-MDRG的关键创新在于桥接了图像历史信息,使得模型能够更好地利用图像信息进行回复生成。这与现有方法仅依赖文本模态作为图像输入输出的桥梁形成了鲜明对比。
关键设计:论文中没有详细描述BI-MDRG的具体技术细节,例如图像历史编码器的具体实现方式、多模态融合模块的设计、以及回复生成器的结构等。这些都是未知信息。
🖼️ 关键图片
📊 实验亮点
论文通过在多模态对话基准数据集上进行实验,证明了BI-MDRG可以有效提高多模态对话的质量。此外,论文还构建了一个新的数据集,用于评估多模态对话中图像的一致性,为后续研究提供了有价值的资源。具体的性能数据和提升幅度未知。
🎯 应用场景
BI-MDRG可应用于智能客服、虚拟助手、社交媒体等领域,提升多模态对话系统的交互体验。例如,在电商场景中,用户可以通过对话与机器人互动,机器人可以根据用户的提问和上传的图片,生成相关的文本回复和商品图片,从而帮助用户更好地了解商品信息。
📄 摘要(原文)
Multimodal Dialogue Response Generation (MDRG) is a recently proposed task where the model needs to generate responses in texts, images, or a blend of both based on the dialogue context. Due to the lack of a large-scale dataset specifically for this task and the benefits of leveraging powerful pre-trained models, previous work relies on the text modality as an intermediary step for both the image input and output of the model rather than adopting an end-to-end approach. However, this approach can overlook crucial information about the image, hindering 1) image-grounded text response and 2) consistency of objects in the image response. In this paper, we propose BI-MDRG that bridges the response generation path such that the image history information is utilized for enhanced relevance of text responses to the image content and the consistency of objects in sequential image responses. Through extensive experiments on the multimodal dialogue benchmark dataset, we show that BI-MDRG can effectively increase the quality of multimodal dialogue. Additionally, recognizing the gap in benchmark datasets for evaluating the image consistency in multimodal dialogue, we have created a curated set of 300 dialogues annotated to track object consistency across conversations.