HateSieve: A Contrastive Learning Framework for Detecting and Segmenting Hateful Content in Multimodal Memes
作者: Xuanyu Su, Yansong Li, Diana Inkpen, Nathalie Japkowicz
分类: cs.AI, cs.CL, cs.MM, cs.SI
发布日期: 2024-08-11 (更新: 2025-04-30)
备注: Accepted at NAACL 2025 Findings; camera-ready version
期刊: Findings Assoc. Comput. Linguistics: NAACL 2025, 5201-5215 (2025)
💡 一句话要点
HateSieve:用于检测和分割多模态Meme中仇恨内容的对比学习框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 仇恨言论检测 多模态学习 对比学习 Meme分析 图像文本对齐
📋 核心要点
- 现有大型多模态模型在处理复杂内容时,难以有效检测混淆Meme中微妙的仇恨内容。
- HateSieve框架通过对比学习,利用对比Meme生成器和图像-文本对齐模块,提升仇恨内容的检测和分割能力。
- 实验结果表明,HateSieve在Hateful Meme数据集上超越现有LMM,并能精确定位仇恨内容,参数量更少。
📝 摘要(中文)
随着大型多模态模型(LMMs)的兴起及其在生成和解释复杂内容中的广泛应用,传播带有偏见和有害Meme的风险仍然显著。现有的安全措施通常无法检测到巧妙地融入在“混淆Meme”中的仇恨内容。为了解决这个问题,我们引入了 extsc{HateSieve},这是一个旨在增强Meme中仇恨元素检测和分割的新框架。 extsc{HateSieve} 具有新颖的对比Meme生成器,可创建语义配对的Meme,一个用于对比学习的定制三元组数据集,以及一个图像-文本对齐模块,该模块可生成上下文感知的嵌入以实现准确的Meme分割。在Hateful Meme数据集上的经验实验表明, extsc{HateSieve}不仅以更少的训练参数超越了现有的LMM的性能,而且还提供了一种强大的机制来精确识别和隔离仇恨内容。
🔬 方法详解
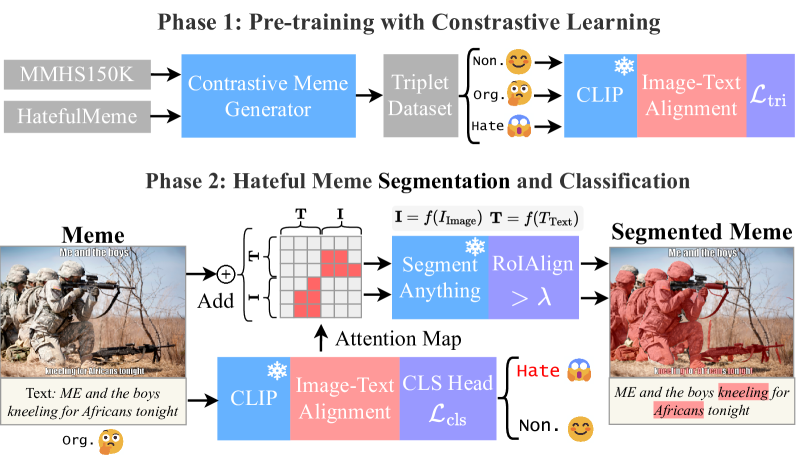
问题定义:论文旨在解决大型多模态模型在检测和分割Meme中仇恨内容时面临的挑战,特别是对于那些巧妙隐藏在“混淆Meme”中的仇恨信息。现有方法往往无法有效识别这些微妙的仇恨表达,导致有害信息的传播。
核心思路:论文的核心思路是利用对比学习,通过构建语义相关的Meme对,让模型学习区分仇恨内容和正常内容之间的细微差别。通过这种方式,模型能够更好地理解Meme的上下文,并准确地识别出其中的仇恨元素。
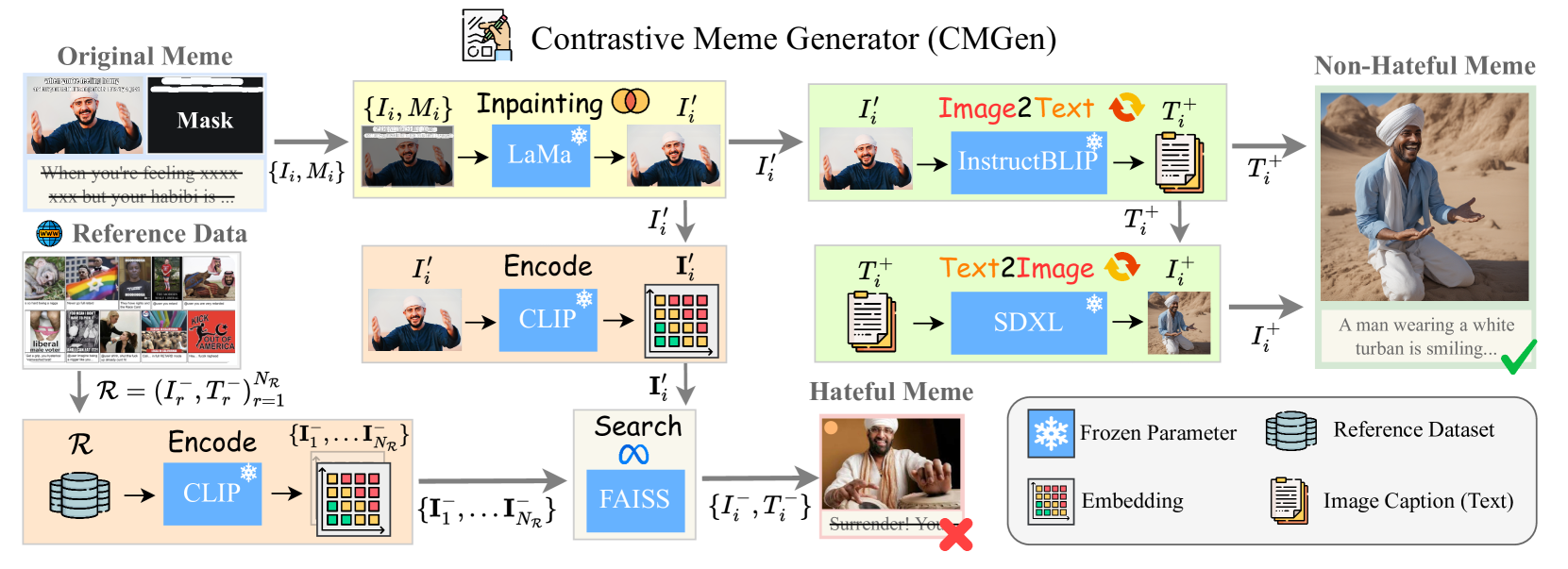
技术框架:HateSieve框架主要包含三个模块:对比Meme生成器、定制三元组数据集和图像-文本对齐模块。对比Meme生成器负责生成语义配对的Meme,用于对比学习。定制三元组数据集用于训练模型,使其能够区分仇恨内容和正常内容。图像-文本对齐模块则用于生成上下文感知的嵌入,从而实现准确的Meme分割。
关键创新:该论文的关键创新在于提出了对比Meme生成器,能够自动生成语义相关的Meme对,从而为对比学习提供了有效的数据。此外,图像-文本对齐模块能够更好地融合图像和文本信息,从而提高仇恨内容检测的准确性。
关键设计:对比Meme生成器的具体实现细节未知。定制三元组数据集的构建方式未知。图像-文本对齐模块的网络结构和损失函数等技术细节也未知。
🖼️ 关键图片

📊 实验亮点
HateSieve在Hateful Meme数据集上取得了显著的性能提升,超越了现有的LMM模型,并且使用了更少的训练参数。该框架能够精确识别和隔离Meme中的仇恨内容,为内容审核提供了更有效的工具。具体的性能数据和对比基线信息未知。
🎯 应用场景
该研究成果可应用于社交媒体平台的内容审核,帮助自动检测和过滤包含仇恨言论的Meme,从而减少有害信息的传播。此外,该方法还可以扩展到其他多模态内容,如视频和新闻文章,以提高内容审核的效率和准确性。未来,该技术有望应用于更广泛的领域,例如在线教育和智能客服,以确保信息的安全和健康。
📄 摘要(原文)
Amidst the rise of Large Multimodal Models (LMMs) and their widespread application in generating and interpreting complex content, the risk of propagating biased and harmful memes remains significant. Current safety measures often fail to detect subtly integrated hateful content within ``Confounder Memes''. To address this, we introduce \textsc{HateSieve}, a new framework designed to enhance the detection and segmentation of hateful elements in memes. \textsc{HateSieve} features a novel Contrastive Meme Generator that creates semantically paired memes, a customized triplet dataset for contrastive learning, and an Image-Text Alignment module that produces context-aware embeddings for accurate meme segmentation. Empirical experiments on the Hateful Meme Dataset show that \textsc{HateSieve} not only surpasses existing LMMs in performance with fewer trainable parameters but also offers a robust mechanism for precisely identifying and isolating hateful content. \textcolor{red}{Caution: Contains academic discussions of hate speech; viewer discretion advised.}