Exploring Applications of State Space Models and Advanced Training Techniques in Sequential Recommendations: A Comparative Study on Efficiency and Performance
作者: Mark Obozov, Makar Baderko, Stepan Kulibaba, Nikolay Kutuzov, Alexander Gasnikov
分类: cs.IR, cs.AI, cs.LG, math.OC
发布日期: 2024-08-10 (更新: 2025-10-05)
备注: arXiv admin note: text overlap with arXiv:2403.07691 by other authors
💡 一句话要点
探索状态空间模型与高级训练技术在序列推荐中的应用,提升效率与性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 序列推荐 状态空间模型 大型语言模型 自适应训练 推荐系统 计算效率 用户偏好
📋 核心要点
- Transformer模型在序列推荐中效果显著,但计算成本随序列长度线性增长,限制了其应用。
- 论文探索了状态空间模型(SSM)在序列推荐中的应用,旨在降低计算成本并保持甚至提升推荐性能。
- 研究还探索了使用大型语言模型(LLM)优化推荐质量,并采用自适应算法加速训练过程。
📝 摘要(中文)
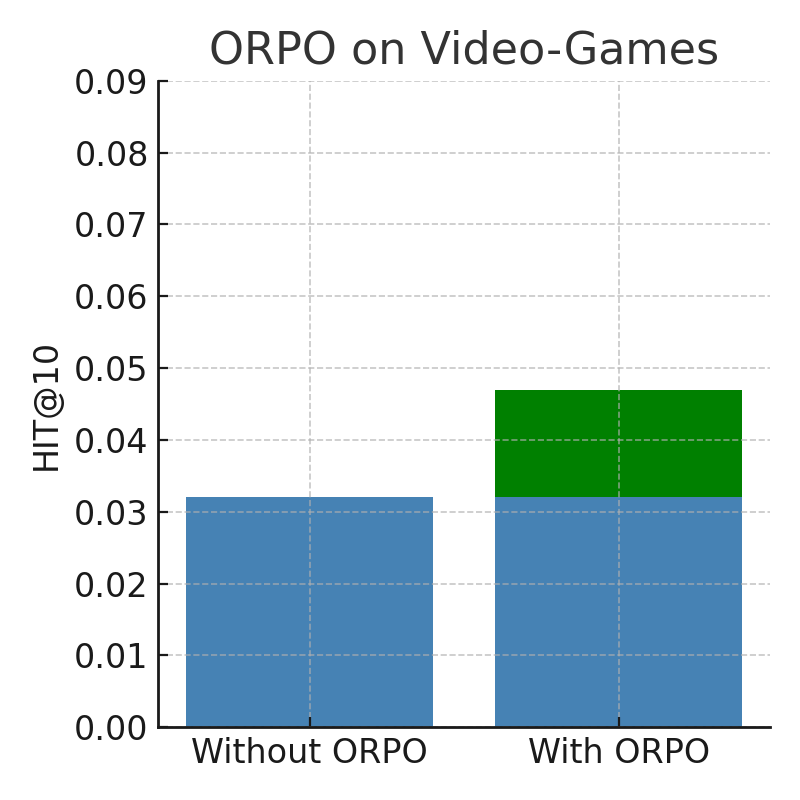
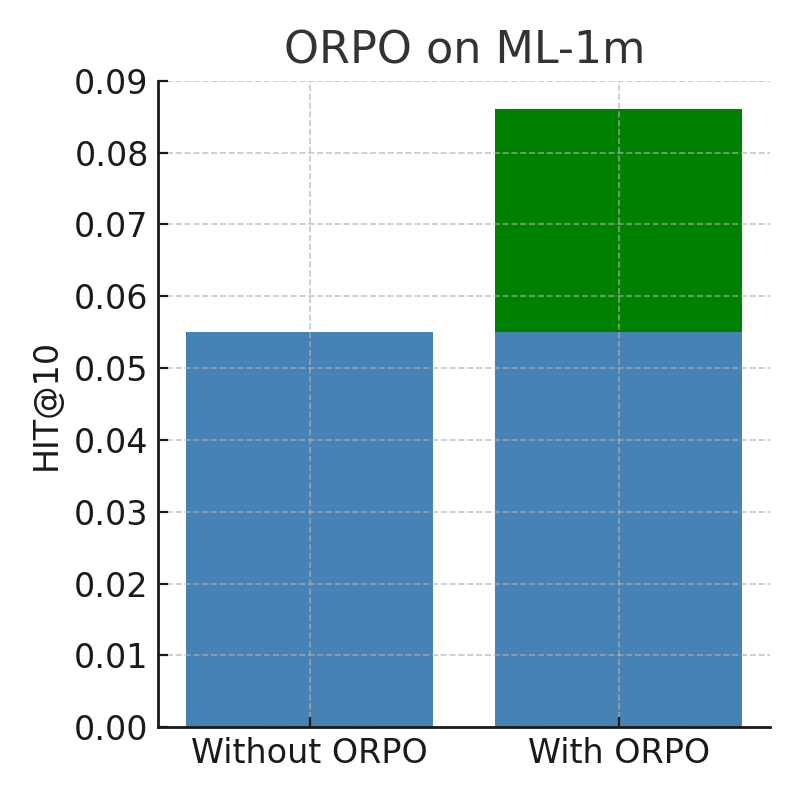
推荐系统旨在预测用户动态变化偏好以及历史行为与元数据之间的序列依赖关系。虽然基于Transformer的模型在序列推荐中表现出色,但其状态增长与序列长度成正比,导致内存和推理成本高昂。本研究聚焦于序列推荐的三个有前景的方向:一是通过使用状态空间模型(SSM)来提高速度,因为SSM可以在序列推荐领域以更低的延迟、内存和推理成本实现SOTA结果,如arXiv:2403.03900所提出的;二是通过大型语言模型(LLM)和Monolithic Preference Optimization without Reference Model (ORPO)来提高推荐质量;三是实施自适应批量和步长算法来降低成本并加速训练过程。
🔬 方法详解
问题定义:序列推荐旨在根据用户的历史行为预测其未来的行为或偏好。现有基于Transformer的模型虽然效果好,但计算复杂度高,尤其是在处理长序列时,内存和推理成本显著增加,限制了其在资源受限场景下的应用。
核心思路:论文的核心思路是利用状态空间模型(SSM)替代Transformer模型,因为SSM在处理序列数据时具有更高的效率,能够在降低计算成本的同时,保持甚至提升推荐性能。此外,还探索了使用大型语言模型(LLM)来优化推荐质量,并采用自适应算法来加速模型训练。
技术框架:整体框架包括三个主要部分:1) 使用状态空间模型(SSM)进行序列建模,提取用户行为的潜在状态表示;2) 利用大型语言模型(LLM)进行偏好优化,提升推荐结果的相关性和多样性;3) 采用自适应批量和步长算法,动态调整训练过程,加速模型收敛并降低训练成本。
关键创新:最重要的技术创新点在于将状态空间模型(SSM)引入序列推荐领域,并结合大型语言模型(LLM)进行优化。与传统的Transformer模型相比,SSM具有更低的计算复杂度和更高的效率,能够更好地处理长序列数据。同时,自适应训练算法能够有效降低训练成本,提升模型训练效率。
关键设计:论文中可能涉及的关键设计包括:SSM的具体结构(例如Mamba、S4等),LLM的微调策略(例如使用ORPO损失函数),自适应批量和步长算法的具体实现(例如基于梯度范数的动态调整),以及针对推荐任务设计的损失函数和评估指标。
🖼️ 关键图片
📊 实验亮点
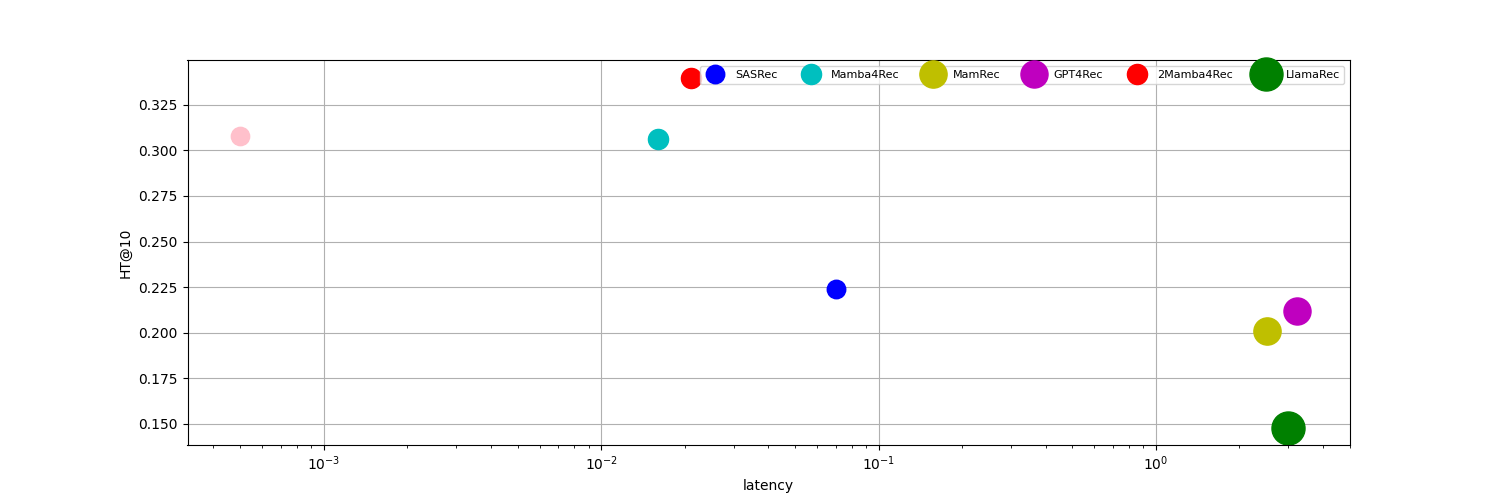
由于论文摘要中没有提供具体的实验结果,因此无法总结实验亮点。需要查阅论文全文才能获取具体的性能数据、对比基线和提升幅度等信息。但是,摘要中提到SSM可以在序列推荐领域以更低的延迟、内存和推理成本实现SOTA结果,这暗示了SSM在效率方面具有显著优势。
🎯 应用场景
该研究成果可应用于各种在线推荐系统,例如电商、视频平台、音乐应用等。通过降低计算成本和提高推荐质量,可以提升用户体验,增加用户粘性,并为平台带来更大的商业价值。未来的研究可以进一步探索SSM与其他先进技术的结合,例如图神经网络、强化学习等,以实现更智能、更高效的推荐系统。
📄 摘要(原文)
Recommender systems aim to estimate the dynamically changing user preferences and sequential dependencies between historical user behaviour and metadata. Although transformer-based models have proven to be effective in sequential recommendations, their state growth is proportional to the length of the sequence that is being processed, which makes them expensive in terms of memory and inference costs. Our research focused on three promising directions in sequential recommendations: enhancing speed through the use of State Space Models (SSM), as they can achieve SOTA results in the sequential recommendations domain with lower latency, memory, and inference costs, as proposed by arXiv:2403.03900 improving the quality of recommendations with Large Language Models (LLMs) via Monolithic Preference Optimization without Reference Model (ORPO); and implementing adaptive batch- and step-size algorithms to reduce costs and accelerate training processes.