In-Context Exploiter for Extensive-Form Games
作者: Shuxin Li, Chang Yang, Youzhi Zhang, Pengdeng Li, Xinrun Wang, Xiao Huang, Hau Chan, Bo An
分类: cs.AI, cs.GT
发布日期: 2024-08-10
💡 一句话要点
提出ICE:利用上下文学习在扩展式博弈中自适应地利用对手策略
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 上下文学习 扩展式博弈 策略利用 强化学习 Transformer模型
📋 核心要点
- 现有博弈求解方法侧重于寻找纳什均衡,但忽略了利用非理性对手的可能性,导致次优策略。
- ICE算法通过上下文学习,使单个模型能够扮演博弈中的任何玩家,并根据对手的行为自适应地调整策略。
- 实验结果表明,ICE算法能够有效地利用各种未知对手,验证了其在扩展式博弈中进行策略利用的能力。
📝 摘要(中文)
纳什均衡(NE)是博弈论中一种被广泛采用的解概念,因为它具有稳定性。然而,我们观察到,即使采用NE策略,也可能无法获得最佳结果,特别是当对手不遵守NE策略时。基于此,我们提出了一个新的博弈求解问题:我们能否学习一个模型,使其能够利用任何对手(甚至是NE对手)来最大化自身效用?在这项工作中,我们首次尝试通过上下文学习来研究这个问题。具体来说,我们引入了一种新方法,即上下文学习利用器(ICE),以训练一个单一模型,该模型可以充当博弈中的任何玩家,并通过上下文学习自适应地利用对手。我们的ICE算法包括生成多样化的对手策略,通过强化学习算法收集交互历史训练数据,以及在精心设计的课程学习框架内训练基于Transformer的智能体。最后,全面的实验结果验证了我们的ICE算法的有效性,展示了其利用任何未知对手的上下文学习能力,从而积极地回答了我们最初的博弈求解问题。
🔬 方法详解
问题定义:论文旨在解决传统博弈求解方法在面对非理性对手时的局限性。现有方法通常致力于寻找纳什均衡,但未能充分利用对手的非理性行为来提升自身收益。因此,问题在于如何设计一种能够自适应地学习并利用任何对手策略(包括偏离纳什均衡的策略)的智能体。
核心思路:论文的核心思路是利用上下文学习(In-Context Learning)的能力,训练一个能够根据对手的历史行为动态调整自身策略的智能体。通过将对手的行为历史作为上下文信息输入模型,智能体可以学习到不同对手的特点,并采取相应的利用策略。这种方法避免了为每个对手单独训练模型的需要,提高了模型的泛化能力。
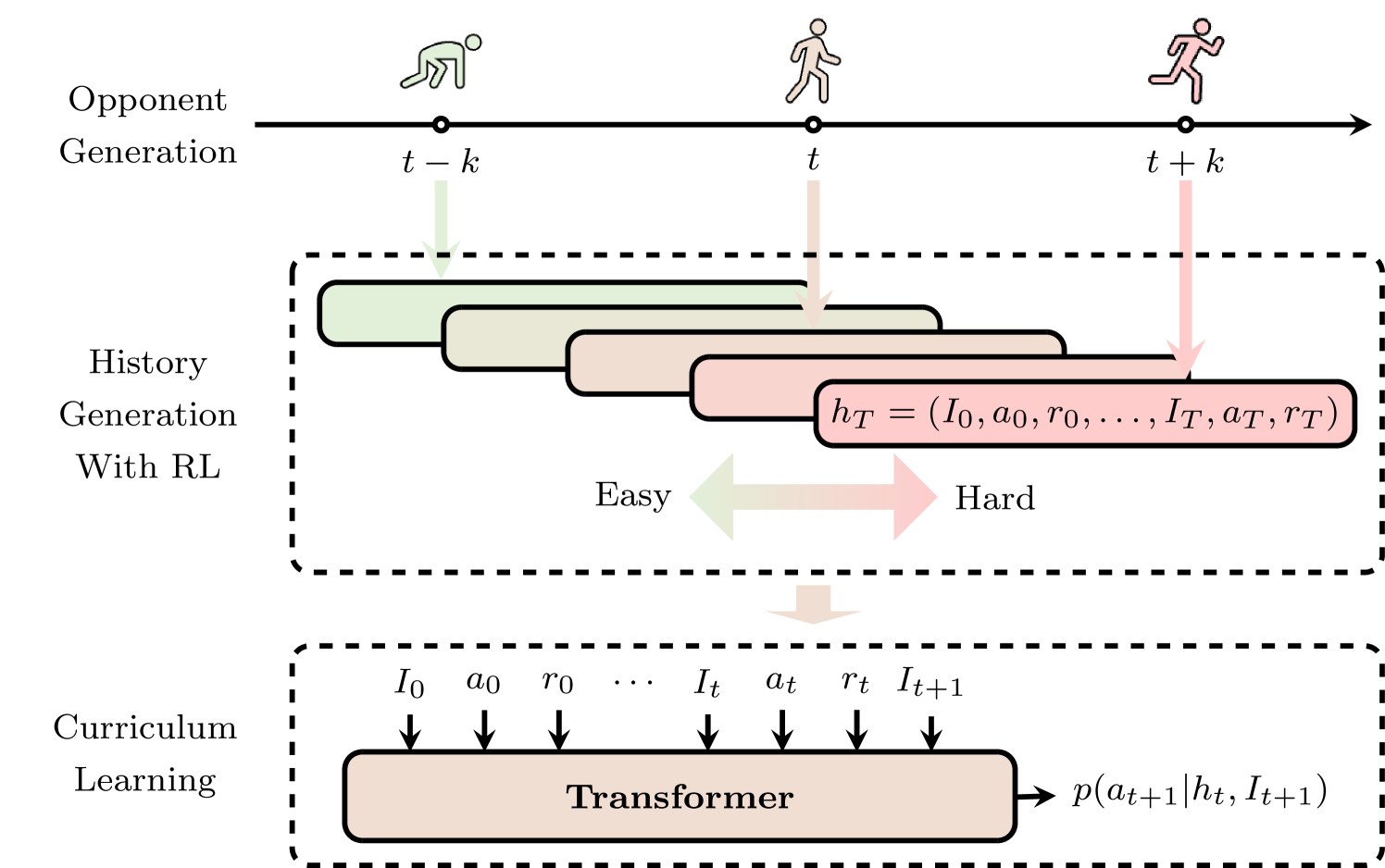
技术框架:ICE算法的技术框架主要包括三个阶段:1) 生成多样化的对手策略:使用强化学习算法生成各种不同的对手策略,包括接近纳什均衡和偏离纳什均衡的策略。2) 收集交互历史数据:让智能体与生成的对手进行交互,记录交互历史数据,包括智能体和对手的行动、状态和奖励。3) 训练基于Transformer的智能体:使用收集到的交互历史数据,在课程学习框架下训练一个基于Transformer的智能体。Transformer模型能够有效地捕捉序列数据中的依赖关系,从而更好地理解对手的行为模式。
关键创新:ICE算法的关键创新在于将上下文学习应用于扩展式博弈的策略利用。与传统的博弈求解方法相比,ICE算法不需要预先知道对手的策略,而是通过观察对手的行为来学习和利用其弱点。此外,ICE算法使用单一模型来处理不同的对手,避免了为每个对手单独训练模型的需要,提高了模型的效率和泛化能力。
关键设计:在训练过程中,论文采用了课程学习策略,逐步增加对手策略的复杂性,以提高智能体的学习效率和鲁棒性。损失函数的设计旨在最大化智能体在与对手交互时的累积奖励。Transformer模型的具体结构和参数设置根据具体的博弈环境进行调整。此外,论文还设计了特定的输入格式,将对手的历史行为编码为Transformer模型的输入,以便模型能够有效地利用这些信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,ICE算法在各种扩展式博弈中均表现出色,能够有效地利用各种未知对手。例如,在Leduc Hold'em游戏中,ICE算法能够显著超越传统的纳什均衡求解器,并取得更高的平均收益。此外,实验还验证了ICE算法的泛化能力,表明其能够适应不同的对手策略,并保持稳定的性能。
🎯 应用场景
该研究成果可应用于各种涉及策略交互的场景,例如:网络安全攻防、金融市场交易、自动驾驶车辆博弈等。通过学习和利用对手的策略,智能体可以在复杂环境中做出更优决策,提高自身收益。此外,该方法还可以用于分析对手的行为模式,为策略制定提供参考。
📄 摘要(原文)
Nash equilibrium (NE) is a widely adopted solution concept in game theory due to its stability property. However, we observe that the NE strategy might not always yield the best results, especially against opponents who do not adhere to NE strategies. Based on this observation, we pose a new game-solving question: Can we learn a model that can exploit any, even NE, opponent to maximize their own utility? In this work, we make the first attempt to investigate this problem through in-context learning. Specifically, we introduce a novel method, In-Context Exploiter (ICE), to train a single model that can act as any player in the game and adaptively exploit opponents entirely by in-context learning. Our ICE algorithm involves generating diverse opponent strategies, collecting interactive history training data by a reinforcement learning algorithm, and training a transformer-based agent within a well-designed curriculum learning framework. Finally, comprehensive experimental results validate the effectiveness of our ICE algorithm, showcasing its in-context learning ability to exploit any unknown opponent, thereby positively answering our initial game-solving question.