LLMServingSim: A HW/SW Co-Simulation Infrastructure for LLM Inference Serving at Scale
作者: Jaehong Cho, Minsu Kim, Hyunmin Choi, Guseul Heo, Jongse Park
分类: cs.DC, cs.AI
发布日期: 2024-08-10
备注: 15 pages, 11 figures
期刊: IISWC 2024
DOI: 10.1109/IISWC63097.2024.00012
💡 一句话要点
LLMServingSim:用于大规模LLM推理服务的软硬件协同仿真基础设施
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM推理服务 软硬件协同仿真 迭代级仿真 计算冗余 异构处理器 性能评估 加速器仿真
📋 核心要点
- 现有LLM服务仿真器无法有效处理LLM推理的动态工作负载变化,导致仿真精度不足。
- LLMServingSim通过迭代粒度的仿真,复用解码器块的计算冗余,提升仿真效率。
- 实验表明,LLMServingSim在保证仿真精度的前提下,显著提升了仿真速度,优于现有方法。
📝 摘要(中文)
近年来,构建高效的大型语言模型(LLM)推理服务系统受到了广泛的研究关注。这些研究不仅包括算法和软件领域的创新,还包括各种硬件加速技术的发展。然而,目前缺乏能够准确建模LLM服务系统中通用软硬件行为,且不会过度延长仿真时间的仿真基础设施。本文旨在开发一种有效的仿真工具,名为LLMServingSim,以支持未来LLM服务系统的研究。在设计LLMServingSim时,我们关注现有仿真器的两个局限性:(1)它们缺乏对LLM推理服务由于其自回归特性而产生的动态工作负载变化的考虑;(2)它们在LLM中没有利用算法冗余而导致重复仿真。为了解决这些局限性,LLMServingSim以迭代的粒度模拟LLM服务,利用解码器块中的计算冗余,并重用先前迭代的仿真结果。此外,LLMServingSim提供了一个灵活的框架,允许用户插入任何加速器编译器和仿真堆栈,以探索具有异构处理器的各种系统设计。实验表明,LLMServingSim产生的仿真结果与基于GPU的真实LLM服务系统的性能行为非常接近,误差率低于14.7%,同时与现有的加速器仿真器相比,仿真速度提高了91.5倍。
🔬 方法详解
问题定义:现有LLM服务仿真器在模拟大规模LLM推理服务时,面临两个主要问题。一是无法准确捕捉LLM自回归特性带来的动态工作负载变化,导致仿真结果与实际系统存在偏差。二是缺乏对LLM内部算法冗余的利用,导致大量重复仿真,效率低下。这些问题阻碍了对新型硬件加速技术和软件优化策略的有效评估。
核心思路:LLMServingSim的核心思路是以迭代为粒度进行LLM服务仿真,并充分利用LLM解码器块之间的计算冗余。通过重用先前迭代的仿真结果,避免重复计算,从而显著提升仿真速度。此外,LLMServingSim提供了一个灵活的框架,允许用户插入不同的加速器编译器和仿真堆栈,以支持对异构处理器系统的探索。
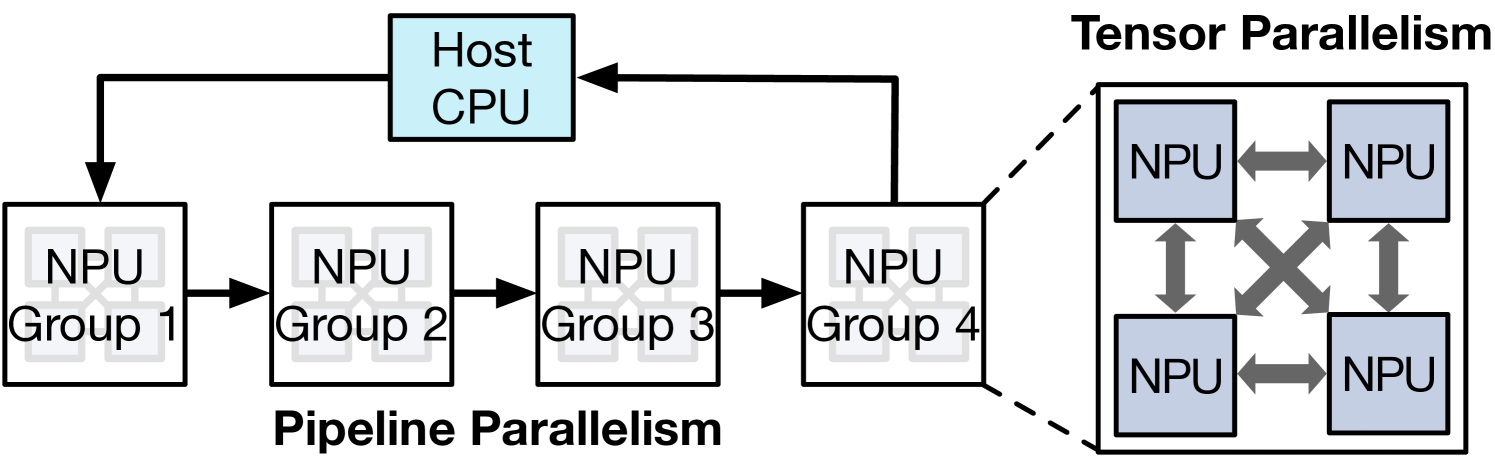
技术框架:LLMServingSim的整体框架包括以下几个主要模块:(1) 工作负载生成器,用于模拟LLM推理的动态请求;(2) 迭代级仿真器,以迭代为单位模拟LLM的推理过程;(3) 冗余利用模块,用于识别和重用解码器块之间的计算冗余;(4) 异构处理器支持模块,允许用户插入不同的加速器编译器和仿真堆栈。整个流程从生成LLM推理请求开始,然后迭代级仿真器根据请求模拟LLM的推理过程,冗余利用模块负责识别和重用计算冗余,最后异构处理器支持模块负责模拟不同硬件加速器上的执行情况。
关键创新:LLMServingSim的关键创新在于其迭代粒度的仿真方法和对LLM计算冗余的有效利用。传统的仿真器通常以层或操作为粒度进行仿真,无法准确捕捉LLM推理的动态特性。而LLMServingSim以迭代为粒度,能够更好地模拟LLM的自回归过程。此外,通过重用解码器块之间的计算冗余,LLMServingSim避免了大量重复仿真,显著提升了仿真效率。与现有方法相比,LLMServingSim在保证仿真精度的前提下,实现了更高的仿真速度。
关键设计:LLMServingSim的关键设计包括:(1) 迭代粒度的仿真器,其核心是维护一个迭代状态,记录每个迭代的输入、输出和计算结果;(2) 冗余利用模块,该模块通过分析LLM的结构,识别解码器块之间的计算冗余,并建立一个缓存机制,用于存储和重用先前迭代的计算结果;(3) 异构处理器支持模块,该模块提供了一个统一的接口,允许用户插入不同的加速器编译器和仿真堆栈。具体参数设置和网络结构取决于用户选择的加速器和LLM模型。
🖼️ 关键图片

📊 实验亮点
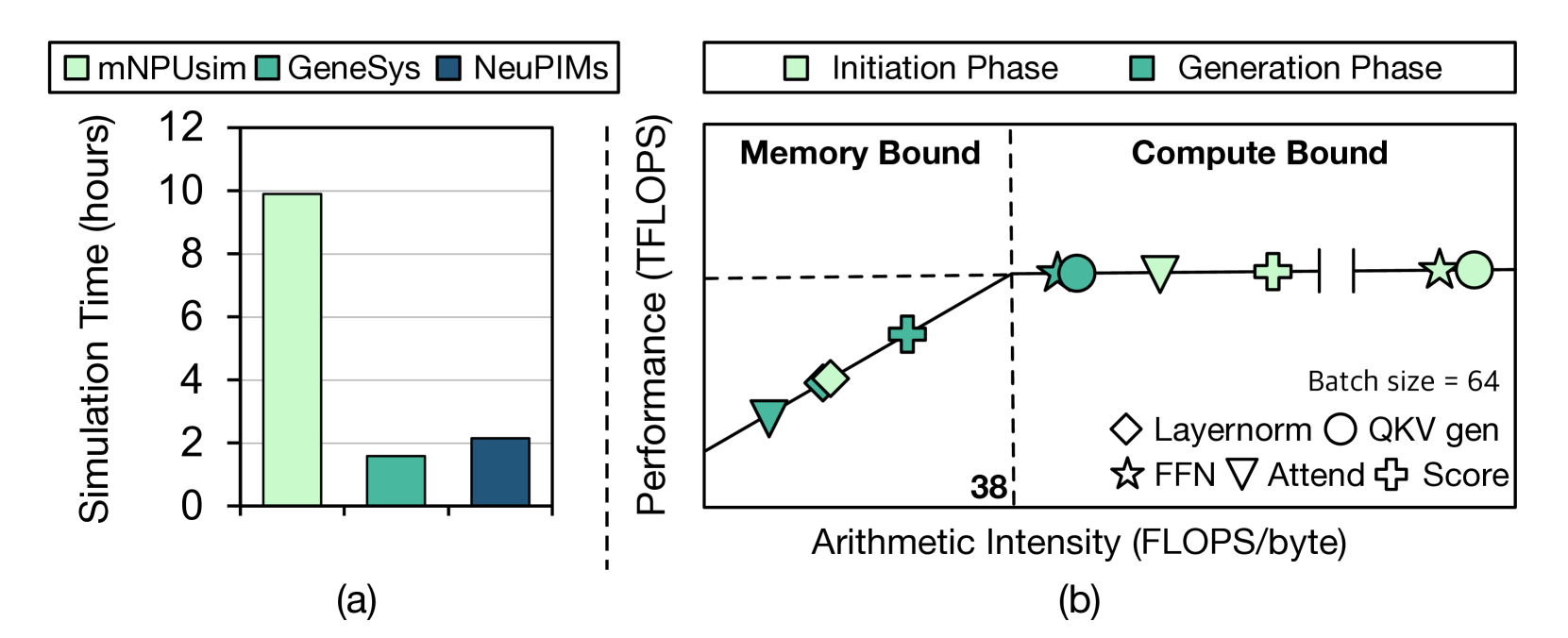
实验结果表明,LLMServingSim能够以低于14.7%的误差率,准确模拟真实GPU-based LLM服务系统的性能行为。同时,与现有的加速器仿真器相比,LLMServingSim的仿真速度提高了91.5倍。这些结果验证了LLMServingSim在LLM服务系统仿真方面的有效性和高效性。
🎯 应用场景
LLMServingSim可应用于LLM推理服务系统的设计与优化,例如硬件加速器的选择、软件优化策略的评估、以及系统资源分配的决策。通过使用LLMServingSim,研究人员和工程师可以快速评估不同设计方案的性能,从而加速LLM服务系统的开发和部署。该工具还有助于探索新型硬件架构和算法优化方法,推动LLM推理服务的发展。
📄 摘要(原文)
Recently, there has been an extensive research effort in building efficient large language model (LLM) inference serving systems. These efforts not only include innovations in the algorithm and software domains but also constitute developments of various hardware acceleration techniques. Nevertheless, there is a lack of simulation infrastructure capable of accurately modeling versatile hardware-software behaviors in LLM serving systems without extensively extending the simulation time. This paper aims to develop an effective simulation tool, called LLMServingSim, to support future research in LLM serving systems. In designing LLMServingSim, we focus on two limitations of existing simulators: (1) they lack consideration of the dynamic workload variations of LLM inference serving due to its autoregressive nature, and (2) they incur repetitive simulations without leveraging algorithmic redundancies in LLMs. To address these limitations, LLMServingSim simulates the LLM serving in the granularity of iterations, leveraging the computation redundancies across decoder blocks and reusing the simulation results from previous iterations. Additionally, LLMServingSim provides a flexible framework that allows users to plug in any accelerator compiler-and-simulation stacks for exploring various system designs with heterogeneous processors. Our experiments demonstrate that LLMServingSim produces simulation results closely following the performance behaviors of real GPU-based LLM serving system with less than 14.7% error rate, while offering 91.5x faster simulation speed compared to existing accelerator simulators.