Preserving Privacy in Large Language Models: A Survey on Current Threats and Solutions
作者: Michele Miranda, Elena Sofia Ruzzetti, Andrea Santilli, Fabio Massimo Zanzotto, Sébastien Bratières, Emanuele Rodolà
分类: cs.CR, cs.AI, cs.CL, cs.LG
发布日期: 2024-08-10 (更新: 2025-02-10)
备注: Published in Transactions on Machine Learning Research (TMLR) https://openreview.net/forum?id=Ss9MTTN7OL
期刊: Transactions on Machine Learning Research, 2025
💡 一句话要点
综述:大型语言模型中的隐私保护——威胁与解决方案
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 隐私保护 差分隐私 联邦学习 隐私攻击 机器卸载学习 数据匿名化
📋 核心要点
- 大型语言模型训练依赖海量数据,易泄露隐私,尤其在医疗等敏感领域,现有方法难以有效应对。
- 本研究全面考察LLM隐私威胁,提出在训练流程中集成隐私保护机制的综合解决方案。
- 综述分析了现有文献,总结了LLM隐私保护的挑战、工具和未来方向,旨在指导更安全的AI系统开发。
📝 摘要(中文)
大型语言模型(LLMs)是人工智能领域的一项重大进步,已应用于各个领域。然而,它们依赖于从互联网获取的大规模数据集进行训练,这带来了显著的隐私问题,在医疗保健等关键领域尤为突出。此外,某些特定应用场景可能需要在私有数据上对这些模型进行微调。本综述 критически 考察了与 LLM 相关的隐私威胁,强调了这些模型记忆并无意中泄露敏感信息的可能性。我们通过回顾针对 LLM 的隐私攻击来探讨当前威胁,并提出了在整个学习流程中集成隐私机制的全面解决方案。这些解决方案包括匿名化训练数据集、在训练或推理过程中实施差分隐私以及训练后的机器卸载学习。我们对现有文献的全面回顾突出了在 LLM 中保护隐私方面持续存在的挑战、可用工具和未来方向。这项工作旨在通过全面了解隐私保护方法及其在降低风险方面的有效性,来指导开发更安全和值得信赖的 AI 系统。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)训练过程中存在的隐私泄露问题。现有方法在保护LLM隐私方面存在不足,例如,简单的数据匿名化可能无法完全消除隐私风险,而直接应用差分隐私可能会显著降低模型性能。此外,针对LLM的特定攻击手段(如成员推断攻击、属性推断攻击)使得隐私保护更具挑战性。
核心思路:论文的核心思路是在LLM的整个学习流程中,从数据预处理、模型训练到推理部署,全面集成隐私保护机制。这包括在数据层面进行匿名化处理,在模型训练阶段应用差分隐私或联邦学习,以及在推理阶段实施隐私增强技术。此外,论文还关注训练后的模型卸载学习,以应对模型已经泄露隐私的情况。
技术框架:论文没有提出新的技术框架,而是一个综述性的工作,对现有的隐私保护技术在LLM中的应用进行了梳理和总结。其框架可以理解为:1)隐私威胁分析:识别LLM面临的各种隐私攻击;2)隐私保护方法:介绍各种隐私保护技术,如数据匿名化、差分隐私、联邦学习、对抗训练等;3)评估与比较:对不同隐私保护方法的优缺点进行评估和比较;4)未来方向:探讨LLM隐私保护的未来研究方向。
关键创新:该论文的关键创新在于对LLM隐私保护领域的现有研究进行了系统性的梳理和总结,并指出了该领域面临的挑战和未来的研究方向。它没有提出全新的技术方法,而是提供了一个全面的视角,帮助研究人员更好地理解和解决LLM的隐私问题。
关键设计:由于是综述论文,没有具体的技术设计。论文讨论了各种隐私保护技术在LLM中的应用,例如,差分隐私中的隐私预算选择、联邦学习中的模型聚合策略、对抗训练中的对抗样本生成方法等。这些技术细节需要根据具体的应用场景进行调整和优化。
🖼️ 关键图片
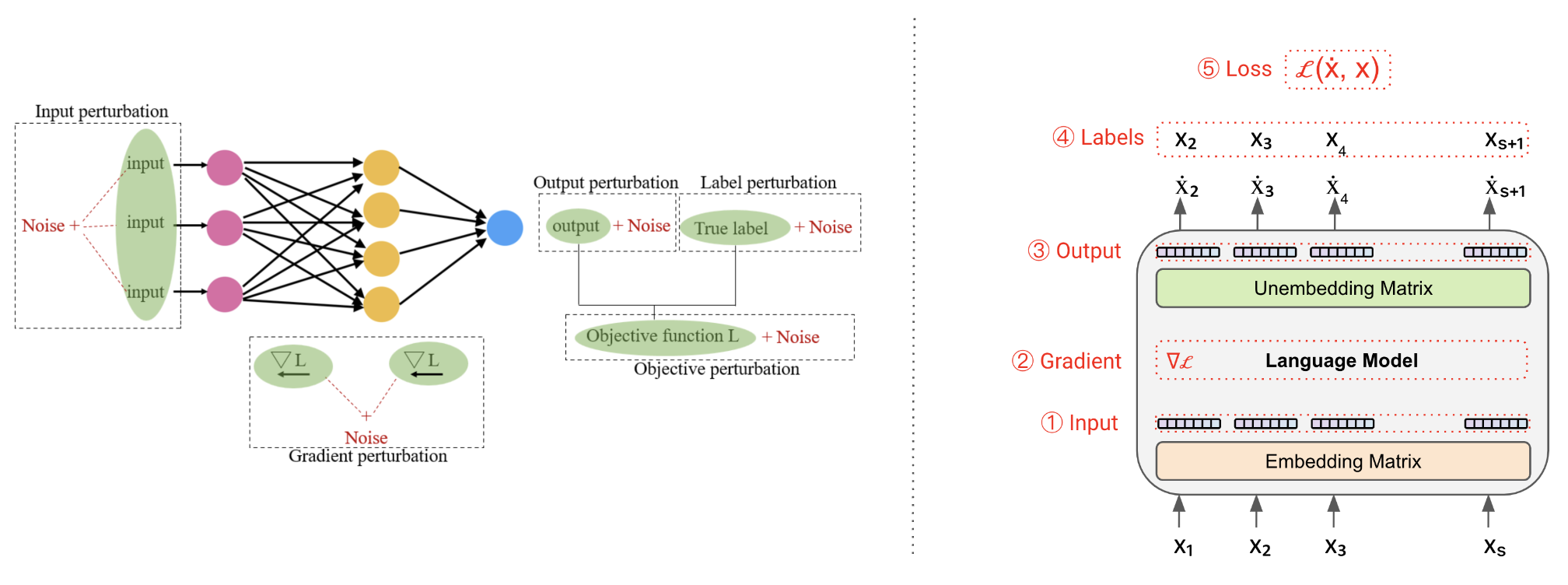
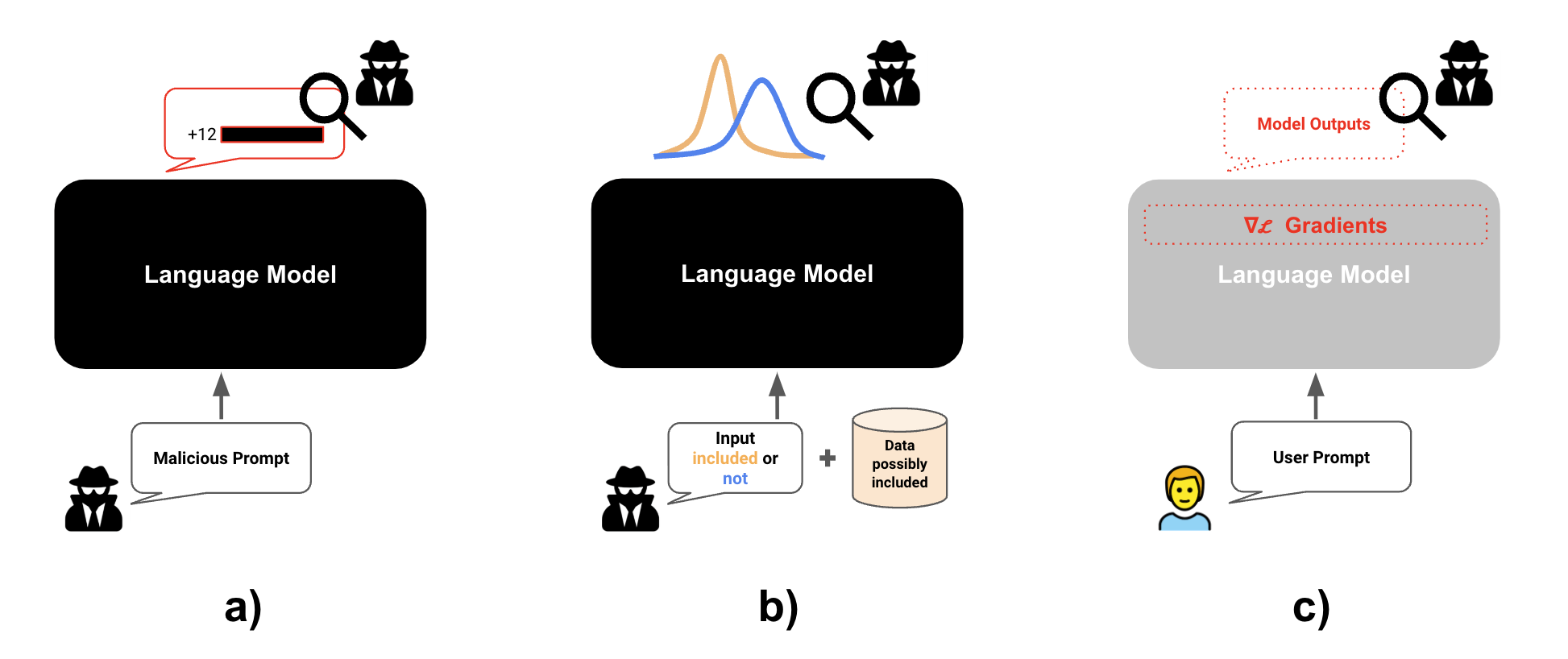

📊 实验亮点
该综述全面回顾了LLM隐私保护领域的现有研究,总结了各种隐私攻击手段和防御方法,并对不同方法的优缺点进行了评估。它强调了在LLM的整个学习流程中集成隐私保护机制的重要性,并指出了该领域未来研究的挑战和方向。虽然没有提供具体的性能数据,但为研究人员提供了一个全面的视角,有助于更好地理解和解决LLM的隐私问题。
🎯 应用场景
该研究成果对医疗、金融等涉及敏感数据的领域具有重要应用价值。通过采用文中所述的隐私保护方法,可以降低LLM在这些领域应用中的隐私泄露风险,促进安全可信的AI系统开发。未来,该研究将推动LLM在更多隐私敏感场景下的应用,例如个性化医疗、智能政务等。
📄 摘要(原文)
Large Language Models (LLMs) represent a significant advancement in artificial intelligence, finding applications across various domains. However, their reliance on massive internet-sourced datasets for training brings notable privacy issues, which are exacerbated in critical domains (e.g., healthcare). Moreover, certain application-specific scenarios may require fine-tuning these models on private data. This survey critically examines the privacy threats associated with LLMs, emphasizing the potential for these models to memorize and inadvertently reveal sensitive information. We explore current threats by reviewing privacy attacks on LLMs and propose comprehensive solutions for integrating privacy mechanisms throughout the entire learning pipeline. These solutions range from anonymizing training datasets to implementing differential privacy during training or inference and machine unlearning after training. Our comprehensive review of existing literature highlights ongoing challenges, available tools, and future directions for preserving privacy in LLMs. This work aims to guide the development of more secure and trustworthy AI systems by providing a thorough understanding of privacy preservation methods and their effectiveness in mitigating risks.