MPC-Minimized Secure LLM Inference
作者: Deevashwer Rathee, Dacheng Li, Ion Stoica, Hao Zhang, Raluca Popa
分类: cs.CR, cs.AI, cs.LG
发布日期: 2024-08-07
💡 一句话要点
Marill:通过MPC友好的LLM微调,实现高效安全的LLM推理
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 安全多方计算 大型语言模型 安全推理 模型微调 隐私保护
📋 核心要点
- 现有LLM推理服务面临用户隐私泄露和模型权重泄露的双重风险,安全多方计算(MPC)虽能解决,但开销巨大。
- Marill的核心思想是在LLM微调阶段进行架构调整,减少推理时MPC的使用量,将部分计算移至MPC外。
- 实验表明,Marill在保证下游任务性能的同时,显著降低了安全推理的运行时间和通信开销。
📝 摘要(中文)
许多基于大型语言模型(LLM)的推理服务存在隐私问题,可能会向服务泄露用户提示或向用户泄露专有权重。安全推理通过安全多方计算(MPC)为此问题提供了一种解决方案,但由于MPC带来的巨大开销,对于现代LLM工作负载而言仍然不切实际。为了解决这个开销问题,我们提出了Marill,一个通过调整LLM微调来最小化安全推理期间MPC使用量的框架。Marill在微调期间引入了高层次的架构更改,通过移除一些昂贵的操作并将其他操作移到MPC之外,显著减少了安全推理期间MPC中所需昂贵操作的数量,而不会损害安全性。因此,Marill生成的模型在所有安全推理协议中都更加高效,并且我们的方法补充了此类操作的MPC友好近似。与标准微调相比,Marill在各种MPC设置下的安全推理期间,实现了3.6-11.3倍的运行时间提升和2.4-6.9倍的通信量减少,同时通常在下游任务中保持超过90%的性能。
🔬 方法详解
问题定义:当前基于LLM的推理服务面临严重的隐私泄露风险,包括用户输入数据泄露给服务提供商,以及模型权重泄露给用户。虽然安全多方计算(MPC)可以提供安全推理,但其计算和通信开销对于大型LLM来说非常高昂,导致实际应用受限。现有的MPC优化方法往往集中在算子层面的优化,缺乏对LLM架构的整体考虑。
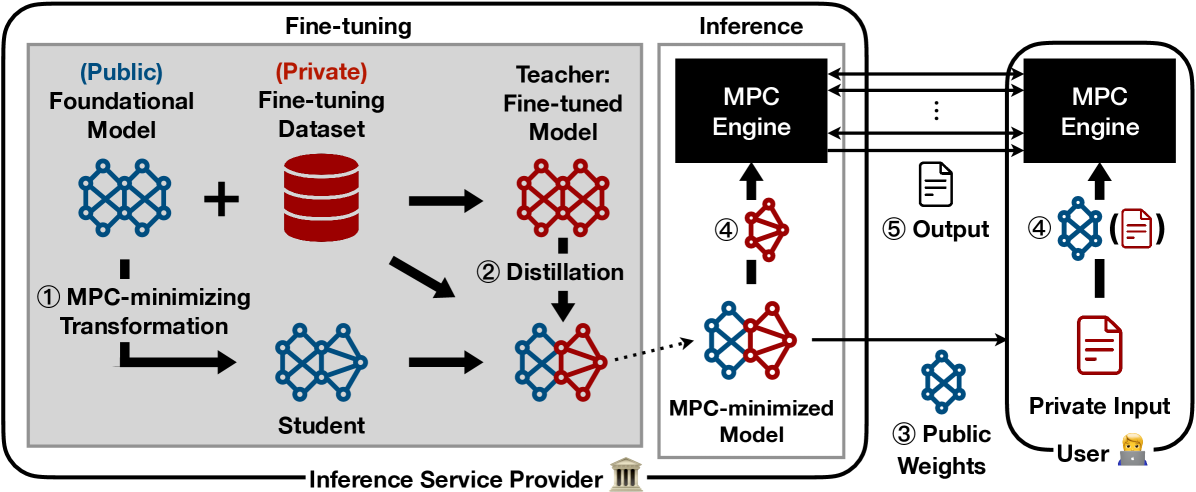
核心思路:Marill的核心思路是在LLM的微调阶段,通过架构上的调整,将推理过程中计算密集且对安全性要求不高的操作移出MPC,从而显著降低MPC的计算负担。这种方法的核心在于找到哪些操作可以安全地移出MPC,以及如何调整模型结构以适应这种改变。
技术框架:Marill的整体框架包括以下几个阶段:1) Profiling: 分析LLM推理过程中各个操作的计算量和安全性需求。2) Architecture Modification: 根据Profiling的结果,对LLM的架构进行修改,将部分操作移出MPC。这可能涉及到层融合、算子替换等技术。3) MPC-Aware Fine-tuning: 在修改后的架构上进行微调,以恢复模型性能。微调过程中需要考虑MPC的特性,例如避免使用不友好的激活函数等。4) Secure Inference: 使用修改后的模型进行安全推理,此时MPC的计算量已经大大降低。
关键创新:Marill的关键创新在于将MPC的优化提前到模型微调阶段,通过架构上的调整来减少MPC的使用量。与传统的MPC优化方法相比,Marill从更高的层次上解决了安全推理的效率问题。此外,Marill还提出了一种MPC-aware的微调方法,可以有效地恢复模型性能。
关键设计:Marill的关键设计包括:1) Operation Relocation: 精确地识别可以安全移出MPC的操作,例如某些激活函数、归一化层等。2) MPC-Friendly Approximation: 对于无法完全移出MPC的操作,使用MPC友好的近似算法来降低计算复杂度。3) Loss Function Design: 在微调过程中,使用特殊的损失函数来平衡模型性能和MPC开销。例如,可以使用正则化项来惩罚模型中不适合MPC计算的参数。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Marill在各种MPC设置下,相比于标准微调,实现了3.6-11.3倍的运行时间提升和2.4-6.9倍的通信量减少。同时,Marill通常在下游任务中保持超过90%的性能。这些结果表明,Marill是一种有效的安全LLM推理优化方法。
🎯 应用场景
Marill可应用于各种需要保护用户隐私和模型所有权的LLM推理场景,例如金融风控、医疗诊断、法律咨询等。通过降低安全推理的计算成本,Marill使得在资源受限的环境下部署安全LLM推理服务成为可能,从而推动LLM在隐私敏感领域的应用。
📄 摘要(原文)
Many inference services based on large language models (LLMs) pose a privacy concern, either revealing user prompts to the service or the proprietary weights to the user. Secure inference offers a solution to this problem through secure multi-party computation (MPC), however, it is still impractical for modern LLM workload due to the large overhead imposed by MPC. To address this overhead, we propose Marill, a framework that adapts LLM fine-tuning to minimize MPC usage during secure inference. Marill introduces high-level architectural changes during fine-tuning that significantly reduce the number of expensive operations needed within MPC during inference, by removing some and relocating others outside MPC without compromising security. As a result, Marill-generated models are more efficient across all secure inference protocols and our approach complements MPC-friendly approximations for such operations. Compared to standard fine-tuning, Marill results in 3.6-11.3x better runtime and 2.4-6.9x better communication during secure inference across various MPC settings, while typically preserving over 90% performance across downstream tasks.