Harnessing the Power of LLMs in Source Code Vulnerability Detection
作者: Andrew A Mahyari
分类: cs.SE, cs.AI, cs.CR
发布日期: 2024-08-07
💡 一句话要点
利用LLM分析LLVM IR以检测源代码漏洞
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 源代码漏洞检测 大型语言模型 LLVM IR 静态分析 软件安全
📋 核心要点
- 软件漏洞是网络攻击的重要源头,传统的静态分析方法存在局限性。
- 利用LLM强大的模式识别能力,通过分析LLVM IR中间表示来检测多种编程语言的源代码漏洞。
- 实验结果表明,该方法在识别真实和合成代码中的漏洞方面具有很高的准确性。
📝 摘要(中文)
软件漏洞是由源代码中无意的缺陷引起的,是网络攻击的主要根源。源代码静态分析已被广泛用于检测软件开发人员引入的这些无意缺陷。大型语言模型(LLM)由于其能够捕获顺序数据(如自然语言)中的复杂模式,因此展现了类似人类的对话能力。本文利用LLM的能力来分析源代码并检测已知的漏洞。为了确保所提出的漏洞检测方法在多种编程语言中具有通用性,我们将源代码转换为LLVM IR,并使用这些中间表示训练LLM。我们对各种LLM架构进行了广泛的实验,并比较了它们的准确性。我们对来自NVD和SARD的真实和合成代码进行的全面实验表明,在识别源代码漏洞方面具有很高的准确性。
🔬 方法详解
问题定义:论文旨在解决源代码漏洞检测问题。现有方法,如传统的静态分析,可能无法有效捕捉复杂的漏洞模式,且对不同编程语言的适应性有限。因此,需要一种更通用、更智能的方法来提高漏洞检测的准确性和效率。
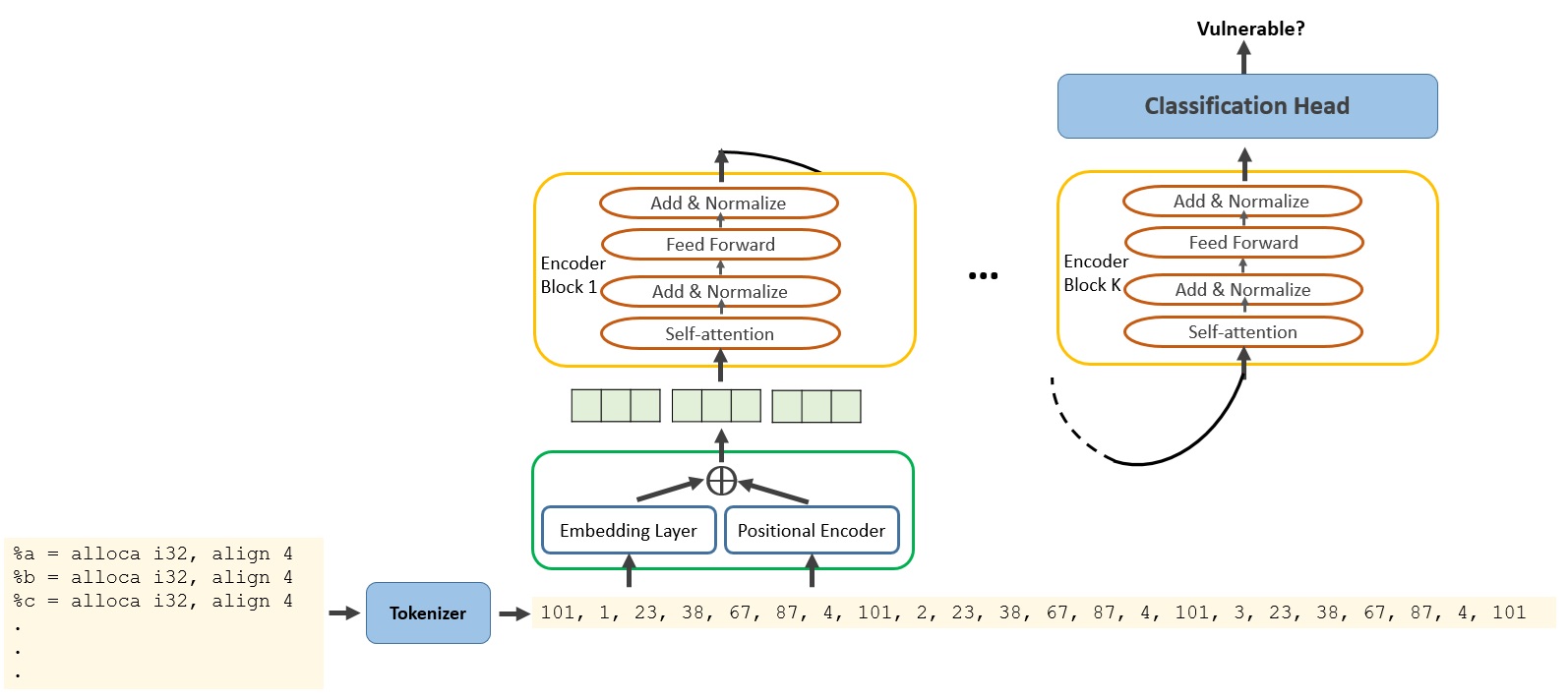
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的模式识别和学习能力,将源代码转换为LLVM IR中间表示,然后训练LLM来识别IR代码中的漏洞模式。这种方法的优势在于LLVM IR具有语言无关性,使得训练后的LLM能够检测多种编程语言的漏洞。
技术框架:整体框架包括以下几个主要步骤:1) 将多种编程语言的源代码转换为LLVM IR;2) 使用转换后的LLVM IR数据训练LLM;3) 使用训练好的LLM对新的LLVM IR代码进行漏洞检测;4) 将检测结果映射回原始源代码,以定位漏洞位置。
关键创新:最重要的技术创新点在于利用LLM直接分析LLVM IR,而不是分析特定编程语言的源代码。这种方法使得漏洞检测器具有更好的通用性和可扩展性,能够处理多种编程语言的漏洞检测任务。
关键设计:论文中关键的设计包括:LLM模型的选择(实验中对比了多种LLM架构),LLVM IR的转换策略(如何有效地将源代码转换为IR),以及训练数据的准备(如何构建包含漏洞信息的训练数据集)。具体的参数设置、损失函数和网络结构等细节可能因不同的LLM架构而异,论文中应该有详细描述。
🖼️ 关键图片
📊 实验亮点
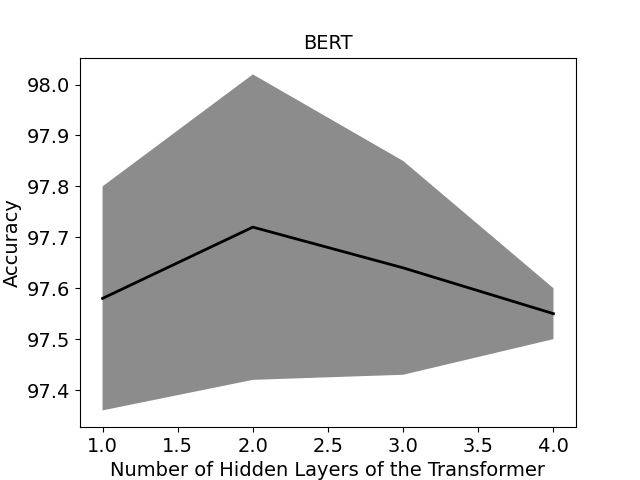
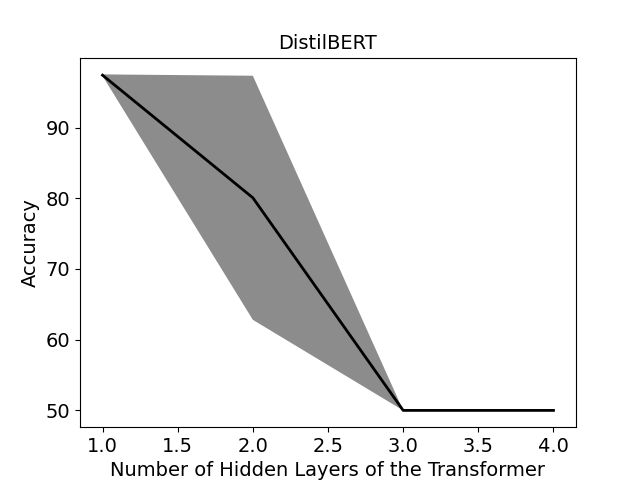
论文通过在真实世界和合成代码(来自NVD和SARD)上进行的大量实验,验证了所提出方法的有效性。实验结果表明,该方法在识别源代码漏洞方面具有很高的准确性,具体性能数据(如精确率、召回率、F1值)以及与现有方法的对比结果需要在论文中进一步查看。具体的提升幅度也需要在论文中查找。
🎯 应用场景
该研究成果可应用于软件安全领域,帮助开发人员在软件开发生命周期的早期发现和修复漏洞,从而提高软件的整体安全性。此外,该方法还可以用于自动化代码审计和安全评估,降低人工成本,提高效率。未来,该技术有望集成到IDE和CI/CD流程中,实现持续的安全监控。
📄 摘要(原文)
Software vulnerabilities, caused by unintentional flaws in source code, are a primary root cause of cyberattacks. Static analysis of source code has been widely used to detect these unintentional defects introduced by software developers. Large Language Models (LLMs) have demonstrated human-like conversational abilities due to their capacity to capture complex patterns in sequential data, such as natural languages. In this paper, we harness LLMs' capabilities to analyze source code and detect known vulnerabilities. To ensure the proposed vulnerability detection method is universal across multiple programming languages, we convert source code to LLVM IR and train LLMs on these intermediate representations. We conduct extensive experiments on various LLM architectures and compare their accuracy. Our comprehensive experiments on real-world and synthetic codes from NVD and SARD demonstrate high accuracy in identifying source code vulnerabilities.