OpenOmni: A Collaborative Open Source Tool for Building Future-Ready Multimodal Conversational Agents
作者: Qiang Sun, Yuanyi Luo, Sirui Li, Wenxiao Zhang, Wei Liu
分类: cs.HC, cs.AI, cs.CL
发布日期: 2024-08-06 (更新: 2024-11-17)
备注: Published in Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations (EMNLP 2024) Best Demo Paper Award at EMNLP 2024
期刊: EMNLP 2024 (System Demonstrations), pp. 46-52
🔗 代码/项目: GITHUB
💡 一句话要点
OpenOmni:用于构建多模态对话Agent的开源协作工具,支持端到端pipeline基准测试。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态对话Agent 开源工具 端到端pipeline 基准测试 人机交互
📋 核心要点
- 现有技术在构建多模态对话Agent时,缺乏端到端的解决方案,难以支持协作开发和性能基准测试。
- OpenOmni提供了一个开源的端到端pipeline,集成了多种模态处理和生成技术,支持定制模型集成和本地/云部署。
- OpenOmni支持延迟和准确性基准测试,允许研究人员专注于pipeline瓶颈,加速多模态对话Agent的开发和验证。
📝 摘要(中文)
多模态对话Agent因其自然和类人的交互方式而备受青睐。然而,目前缺乏全面的端到端解决方案来支持协作开发和基准测试。尽管像GPT-4o和Gemini这样的专有系统展示了令人印象深刻的音频、视频和文本集成,以及200-250毫秒的响应时间,但在平衡延迟、准确性、成本和数据隐私方面仍然存在挑战。为了更好地理解和量化这些问题,我们开发了OpenOmni,这是一个开源的端到端pipeline基准测试工具,集成了语音转文本、情感检测、检索增强生成、大型语言模型等先进技术,并能够集成定制模型。OpenOmni支持本地和云部署,确保数据隐私,并支持延迟和准确性基准测试。这种灵活的框架允许研究人员自定义pipeline,专注于真正的瓶颈,并促进快速的概念验证开发。OpenOmni可以显著增强诸如视障人士的室内辅助等应用,从而推进人机交互。
🔬 方法详解
问题定义:现有方法在构建多模态对话Agent时,缺乏一个统一的、可定制的端到端平台,难以进行有效的协作开发、性能评估和瓶颈分析。专有系统虽然性能强大,但在数据隐私、成本和可访问性方面存在限制。因此,需要一个开源、灵活、可扩展的框架,以促进多模态对话Agent的研究和应用。
核心思路:OpenOmni的核心思路是构建一个模块化的、可配置的pipeline,将多模态处理的各个环节(如语音识别、情感分析、检索增强生成、语言模型等)解耦,并提供标准接口,允许研究人员根据需要选择、替换和定制各个模块。通过提供基准测试工具,帮助开发者量化不同模块组合的性能,从而优化整个pipeline。
技术框架:OpenOmni的整体架构是一个端到端的pipeline,包含以下主要模块:1) 输入模块:负责接收多模态输入,如音频、视频和文本。2) 预处理模块:对输入数据进行清洗、转换和特征提取。3) 模态处理模块:包含语音转文本、情感检测等模块,用于处理不同模态的信息。4) 检索增强生成模块:利用检索技术从知识库中获取相关信息,并结合大型语言模型生成回复。5) 输出模块:将生成的回复以文本或语音等形式输出。整个pipeline支持本地和云部署。
关键创新:OpenOmni的关键创新在于其开源、模块化和可定制的设计。它不同于传统的封闭式系统,允许研究人员自由地探索不同的模型组合和pipeline配置。此外,OpenOmni还提供了一套基准测试工具,帮助开发者量化不同配置的性能,从而优化整个系统。
关键设计:OpenOmni的关键设计包括:1) 模块化接口:定义了统一的接口,方便不同模块的集成和替换。2) 可配置的pipeline:允许用户根据需求自定义pipeline的结构和参数。3) 基准测试工具:提供了一系列评估指标,如延迟、准确性等,用于量化pipeline的性能。4) 本地和云部署支持:方便用户在不同的环境下部署和测试系统。具体的参数设置、损失函数、网络结构等技术细节取决于所使用的具体模型。
🖼️ 关键图片
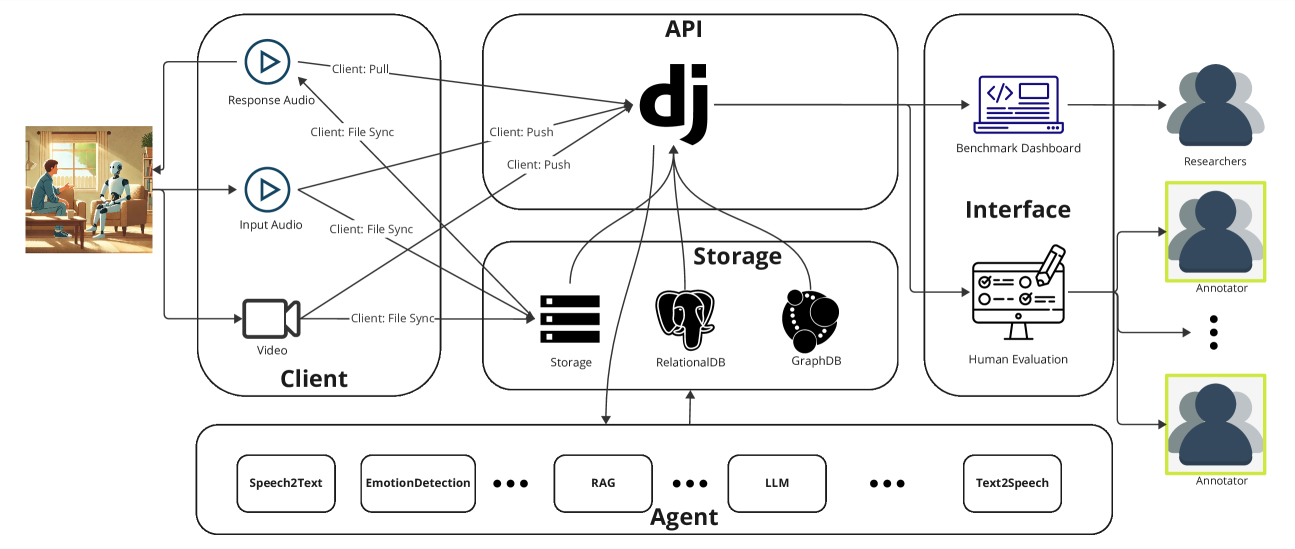

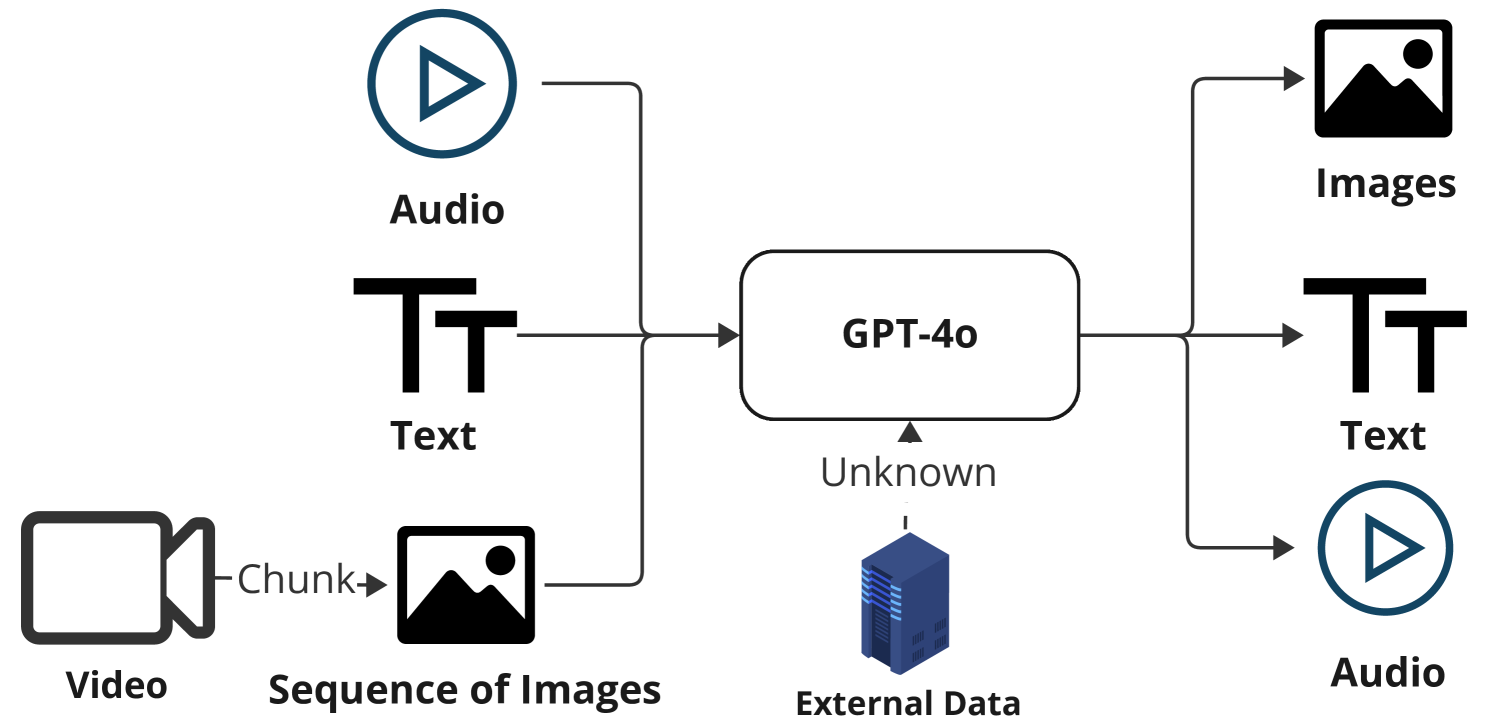
📊 实验亮点
OpenOmni提供了一个完整的端到端pipeline,并集成了多种先进技术,例如语音转文本、情感检测、检索增强生成和大型语言模型。通过OpenOmni,研究人员可以方便地构建和评估多模态对话Agent,并专注于解决实际的瓶颈问题。演示视频展示了OpenOmni在室内辅助方面的应用,证明了其在实际场景中的可行性和有效性。具体的性能数据和对比基线需要在实际使用中进行评估。
🎯 应用场景
OpenOmni具有广泛的应用前景,例如:1) 辅助视障人士进行室内导航和信息获取;2) 构建智能客服系统,提供多模态的交互体验;3) 开发个性化的教育机器人,根据学生的情感状态和学习进度进行智能辅导。该研究将促进人机交互技术的发展,并为构建更加智能、自然的对话Agent提供有力支持。
📄 摘要(原文)
Multimodal conversational agents are highly desirable because they offer natural and human-like interaction. However, there is a lack of comprehensive end-to-end solutions to support collaborative development and benchmarking. While proprietary systems like GPT-4o and Gemini demonstrating impressive integration of audio, video, and text with response times of 200-250ms, challenges remain in balancing latency, accuracy, cost, and data privacy. To better understand and quantify these issues, we developed OpenOmni, an open-source, end-to-end pipeline benchmarking tool that integrates advanced technologies such as Speech-to-Text, Emotion Detection, Retrieval Augmented Generation, Large Language Models, along with the ability to integrate customized models. OpenOmni supports local and cloud deployment, ensuring data privacy and supporting latency and accuracy benchmarking. This flexible framework allows researchers to customize the pipeline, focusing on real bottlenecks and facilitating rapid proof-of-concept development. OpenOmni can significantly enhance applications like indoor assistance for visually impaired individuals, advancing human-computer interaction. Our demonstration video is available https://www.youtube.com/watch?v=zaSiT3clWqY, demo is available via https://openomni.ai4wa.com, code is available via https://github.com/AI4WA/OpenOmniFramework.