SLO-aware GPU Frequency Scaling for Energy Efficient LLM Inference Serving
作者: Andreas Kosmas Kakolyris, Dimosthenis Masouros, Petros Vavaroutsos, Sotirios Xydis, Dimitrios Soudris
分类: cs.DC, cs.AI, cs.AR, cs.LG
发布日期: 2024-08-05 (更新: 2025-12-03)
💡 一句话要点
提出throttLL'eM框架,通过动态调整GPU频率和实例大小,实现LLM推理服务在SLO约束下的节能优化。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 LLM推理 GPU频率调整 服务水平目标 节能优化 机器学习 性能预测 动态资源分配
📋 核心要点
- 大型语言模型推理对GPU功耗需求高,现有方法难以在满足服务水平目标(SLO)的同时降低能耗。
- throttLL'eM框架通过预测KV缓存使用和批大小,利用机器学习模型动态调整GPU频率和实例大小。
- 实验表明,throttLL'eM在满足SLO的前提下,能耗降低高达43.8%,能源效率提升至少1.71倍。
📝 摘要(中文)
随着大型语言模型(LLMs)的普及,其对高功耗GPU的依赖带来了日益增长的能源需求,引发了环境和经济方面的担忧。推理是LLM工作负载的主要部分,对服务提供商提出了关键挑战:在服务水平目标(SLO)下最小化能源成本,以确保最佳用户体验。本文提出了 extit{throttLL'eM},一个通过实例和GPU频率调整来降低能耗并满足SLO的框架。 extit{throttLL'eM}具有预测未来KV缓存使用情况和批大小的机制。利用一个以这些预测作为输入的机器学习(ML)模型, extit{throttLL'eM}在迭代级别管理性能,以较低的频率和实例大小满足SLO。结果表明,所提出的ML模型实现了大于0.97的$R^2$分数,并且平均每次迭代的性能预测误差小于1。在LLM推理跟踪上的实验结果表明,与NVIDIA的Triton服务器相比,在SLO下, extit{throttLL'eM}实现了高达43.8%的能耗降低和至少1.71倍的能源效率提升。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)推理服务中,如何在满足服务水平目标(SLO)的前提下,最小化能源消耗的问题。现有方法,如NVIDIA Triton server,可能无法根据实际负载动态调整资源,导致能源浪费。现有方法的痛点在于无法在保证用户体验(SLO)的同时,有效地降低GPU的功耗。
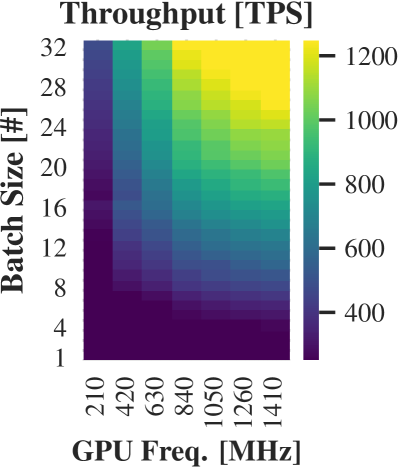
核心思路:论文的核心思路是根据LLM推理过程中的KV缓存使用情况和批大小等信息,预测未来的性能需求,并利用这些预测信息动态地调整GPU的频率和实例大小。通过降低GPU频率和减少实例数量,可以在不违反SLO的前提下,显著降低能源消耗。这种动态调整策略能够更好地适应变化的负载,从而实现更高效的资源利用。
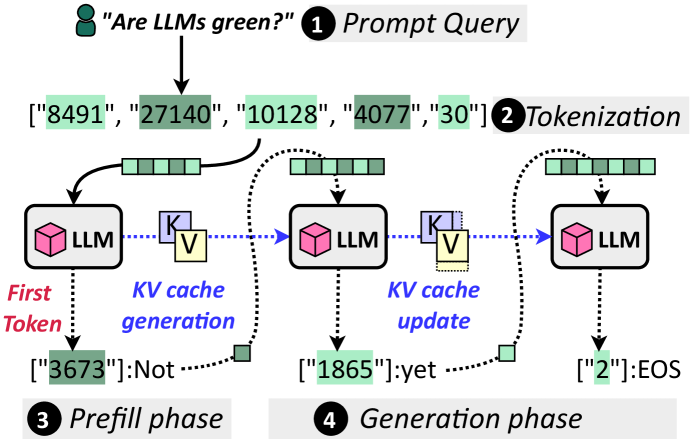
技术框架:throttLL'eM框架包含以下主要模块:1) 性能预测模块:该模块负责预测未来的KV缓存使用情况和批大小。2) 机器学习模型:该模型以性能预测模块的输出作为输入,预测在不同GPU频率和实例大小下的性能表现。3) 频率和实例大小调整模块:该模块根据机器学习模型的预测结果,动态地调整GPU的频率和实例大小,以满足SLO并最小化能源消耗。整体流程是:收集LLM推理过程中的性能数据 -> 预测未来性能需求 -> 利用机器学习模型预测不同配置下的性能 -> 调整GPU频率和实例大小 -> 监控SLO并进行反馈调整。
关键创新:论文的关键创新在于提出了一种基于机器学习的动态资源调整方法,该方法能够根据LLM推理过程中的实时性能数据,预测未来的性能需求,并动态地调整GPU频率和实例大小。与现有方法相比,throttLL'eM能够更精细地控制资源分配,从而在满足SLO的前提下,显著降低能源消耗。此外,该方法还考虑了KV缓存的使用情况,这对于LLM推理的性能至关重要。
关键设计:性能预测模块使用时间序列预测模型(具体模型未知)来预测未来的KV缓存使用情况和批大小。机器学习模型使用回归模型(具体模型未知)来预测在不同GPU频率和实例大小下的性能表现,目标是最小化预测误差,使用R^2作为评估指标。频率和实例大小调整模块使用优化算法(具体算法未知)来确定最佳的GPU频率和实例大小,目标是在满足SLO的前提下,最小化能源消耗。SLO的具体定义未知,但可能包括延迟、吞吐量等指标。
🖼️ 关键图片
📊 实验亮点
实验结果表明,throttLL'eM框架在LLM推理跟踪上实现了显著的节能效果。与NVIDIA的Triton服务器相比,在满足SLO的前提下,throttLL'eM能够降低高达43.8%的能耗,并提升至少1.71倍的能源效率。机器学习模型实现了大于0.97的R^2分数,并且平均每次迭代的性能预测误差小于1,表明该模型具有较高的预测精度。
🎯 应用场景
该研究成果可应用于各种需要部署大型语言模型推理服务的场景,例如云服务提供商、AI平台等。通过动态调整GPU频率和实例大小,可以显著降低能源消耗,降低运营成本,并减少碳排放,具有重要的经济和社会价值。未来,该技术可以进一步扩展到其他类型的AI模型和服务,实现更广泛的节能优化。
📄 摘要(原文)
As Large Language Models (LLMs) gain traction, their reliance on power-hungry GPUs places ever-increasing energy demands, raising environmental and monetary concerns. Inference dominates LLM workloads, presenting a critical challenge for providers: minimizing energy costs under Service-Level Objectives (SLOs) that ensure optimal user experience. In this paper, we present \textit{throttLL'eM}, a framework that reduces energy consumption while meeting SLOs through the use of instance and GPU frequency scaling. \textit{throttLL'eM} features mechanisms that project future KV cache usage and batch size. Leveraging a Machine-Learning (ML) model that receives these projections as inputs, \textit{throttLL'eM} manages performance at the iteration level to satisfy SLOs with reduced frequencies and instance sizes. We show that the proposed ML model achieves $R^2$ scores greater than 0.97 and miss-predicts performance by less than 1 iteration per second on average. Experimental results on LLM inference traces show that \textit{throttLL'eM} achieves up to 43.8\% lower energy consumption and an energy efficiency improvement of at least $1.71\times$ under SLOs, when compared to NVIDIA's Triton server.