Text Conditioned Symbolic Drumbeat Generation using Latent Diffusion Models
作者: Pushkar Jajoria, James McDermott
分类: cs.SD, cs.AI, cs.LG, eess.AS
发布日期: 2024-08-05
💡 一句话要点
提出基于潜在扩散模型的文本条件符号鼓点生成方法,提升鼓点生成质量与文本相关性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 鼓点生成 文本条件生成 潜在扩散模型 对比学习 多分辨率LSTM
📋 核心要点
- 现有鼓点生成方法难以保证生成鼓点的质量和与文本描述的相关性。
- 利用潜在扩散模型,结合对比学习预训练的文本和鼓点编码器,实现文本和音乐模态的对齐。
- 通过听力测试验证,生成的鼓点在质量、文本相关性和新颖性方面表现良好,可与人类创作媲美。
📝 摘要(中文)
本研究提出了一种基于潜在扩散模型(LDM)的文本条件鼓点生成方法。该方法利用从训练数据文件名中提取的信息性文本作为条件。通过在多模态网络中,使用对比学习预训练文本和鼓点编码器(对齐方式类似于CLIP),紧密对齐文本和音乐的模态。此外,还研究了一种基于多热编码的替代文本编码器。受到音乐多分辨率特性的启发,我们提出了一种新型LSTM变体——MultiResolutionLSTM,旨在独立地在各种分辨率下运行。与图像空间中最新的LDM类似,它通过在预训练的无条件自编码器提供的潜在空间中运行扩散,从而加快了生成过程。我们通过测量距离(包括在二值钢琴卷帘和潜在空间中)与训练数据集以及生成的鼓点之间的距离,来证明生成的鼓点的原创性和多样性。我们还通过听力测试评估生成的鼓点,重点关注质量、与提示文本的适用性和新颖性。结果表明,生成的鼓点具有新颖性,适合提示文本,并且质量与人类音乐家创作的鼓点相当。
🔬 方法详解
问题定义:论文旨在解决文本条件下的鼓点生成问题。现有方法在生成鼓点时,难以保证生成鼓点的质量,以及与输入文本描述的高度相关性,缺乏对音乐多分辨率特性的有效建模。
核心思路:论文的核心思路是利用潜在扩散模型(LDM)强大的生成能力,并结合对比学习预训练的文本和鼓点编码器,将文本信息有效地融入到鼓点生成过程中。通过在潜在空间中进行扩散过程,可以加速生成并提高生成质量。同时,引入MultiResolutionLSTM来捕捉音乐的多分辨率特性。
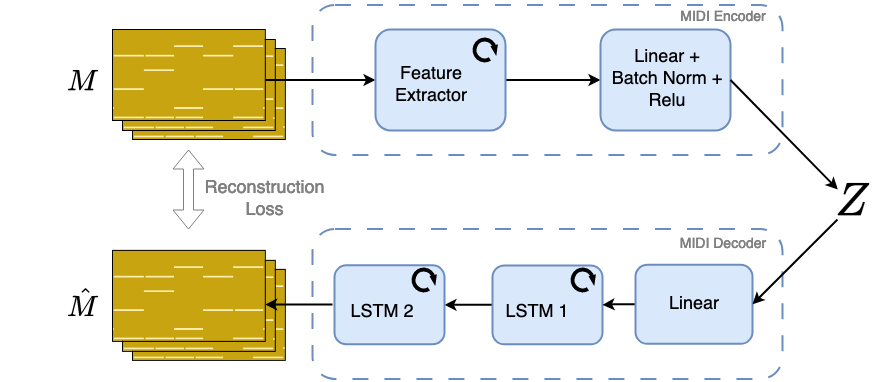
技术框架:整体框架包含以下几个主要模块:1) 预训练的无条件自编码器:用于将鼓点数据编码到潜在空间,并在生成后解码回原始空间。2) 文本编码器:将输入文本编码为文本嵌入向量,论文尝试了基于CLIP的文本编码器和基于多热编码的文本编码器。3) 鼓点编码器:将鼓点数据编码为鼓点嵌入向量,与文本编码器共同进行对比学习。4) 潜在扩散模型:在潜在空间中进行扩散和逆扩散过程,生成鼓点的潜在表示。5) MultiResolutionLSTM:作为扩散模型的核心模块,用于建模鼓点的时序关系,并支持多分辨率输入。
关键创新:论文的关键创新点在于:1) 提出了一种基于潜在扩散模型的文本条件鼓点生成框架,能够生成高质量且与文本描述相关的鼓点。2) 引入MultiResolutionLSTM,能够有效地捕捉音乐的多分辨率特性,提升生成鼓点的音乐性。3) 使用对比学习预训练文本和鼓点编码器,实现了文本和音乐模态的有效对齐。
关键设计:1) 对比学习损失函数:用于对齐文本和鼓点嵌入向量,使得相似的文本和鼓点在嵌入空间中距离更近。2) MultiResolutionLSTM结构:设计了一种LSTM变体,能够独立地在不同的时间分辨率上进行建模,从而捕捉音乐的多分辨率特性。3) 潜在空间扩散过程:在预训练的自编码器提供的潜在空间中进行扩散和逆扩散过程,加速生成并提高生成质量。4) 听力测试设计:设计了听力测试,从质量、文本相关性和新颖性三个方面评估生成鼓点的性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法生成的鼓点在原创性和多样性方面表现良好。听力测试结果显示,生成的鼓点在质量、与提示文本的适用性和新颖性方面均达到较高水平,与人类音乐家创作的鼓点质量相当。通过距离测量,验证了生成鼓点与训练数据集的差异性,以及生成鼓点之间的多样性。
🎯 应用场景
该研究成果可应用于音乐创作辅助工具、音乐教育软件、游戏音乐生成等领域。通过输入文本描述,用户可以快速生成符合需求的鼓点,降低音乐创作门槛,提高创作效率。未来,该技术有望扩展到其他乐器的生成,实现更丰富的音乐创作。
📄 摘要(原文)
This study introduces a text-conditioned approach to generating drumbeats with Latent Diffusion Models (LDMs). It uses informative conditioning text extracted from training data filenames. By pretraining a text and drumbeat encoder through contrastive learning within a multimodal network, aligned following CLIP, we align the modalities of text and music closely. Additionally, we examine an alternative text encoder based on multihot text encodings. Inspired by musics multi-resolution nature, we propose a novel LSTM variant, MultiResolutionLSTM, designed to operate at various resolutions independently. In common with recent LDMs in the image space, it speeds up the generation process by running diffusion in a latent space provided by a pretrained unconditional autoencoder. We demonstrate the originality and variety of the generated drumbeats by measuring distance (both over binary pianorolls and in the latent space) versus the training dataset and among the generated drumbeats. We also assess the generated drumbeats through a listening test focused on questions of quality, aptness for the prompt text, and novelty. We show that the generated drumbeats are novel and apt to the prompt text, and comparable in quality to those created by human musicians.