Spin glass model of in-context learning
作者: Yuhao Li, Ruoran Bai, Haiping Huang
分类: cond-mat.dis-nn, cond-mat.stat-mech, cs.AI, cs.CL
发布日期: 2024-08-05 (更新: 2025-04-18)
备注: 16 pages, 4+6 figures, revised version to the journal
期刊: Phys. Rev. E 112, L013301 (2025)
DOI: 10.1103/5l5m-4nk5
💡 一句话要点
将Transformer线性注意力机制映射到自旋玻璃模型,解释上下文学习能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 自旋玻璃模型 Transformer 线性注意力 预训练模型
📋 核心要点
- 大型语言模型的上下文学习能力缺乏有效的机制解释,难以将其与物理学理论联系。
- 本文将线性注意力Transformer映射到自旋玻璃模型,利用该模型解释预训练过程中权重参数的相互作用。
- 研究表明,增加任务多样性能够促使上下文学习的出现,使模型在新的提示设置中具备预测能力。
📝 摘要(中文)
大型语言模型展现出惊人的上下文学习能力,即能够利用提示来预测查询,而无需额外的训练,这与传统的监督学习形成鲜明对比。对这种现象进行机制性解释,并将其与物理学联系起来,极具挑战性且尚未解决。本文研究了一个简单而富有表现力的具有线性注意力的Transformer,并将其映射到一个具有实值自旋的自旋玻璃模型,其中耦合和场解释了数据的内在无序性。该自旋玻璃模型解释了权重参数在预训练期间如何相互作用,并进一步阐明了为什么仅提供提示即可预测未见过的函数而无需进一步训练。我们的理论表明,对于单实例学习,增加任务多样性会导致上下文学习的出现,通过允许玻尔兹曼分布收敛到权重参数的唯一正确解。因此,预训练的Transformer在新的提示设置中显示出预测能力。所提出的解析可处理模型为思考如何解释大型语言模型的许多有趣但令人费解的属性提供了一条有希望的途径。
🔬 方法详解
问题定义:大型语言模型展现出强大的上下文学习能力,即仅通过prompt就能对query进行预测,而无需额外的训练。然而,这种能力的内在机制尚不明确,缺乏理论解释,尤其难以与物理学中的相关概念建立联系。现有方法难以解释这种涌现的上下文学习能力,以及预训练过程对模型性能的影响。
核心思路:本文的核心思路是将Transformer模型中的线性注意力机制与物理学中的自旋玻璃模型联系起来。通过这种映射,将语言模型中的权重参数视为自旋玻璃模型中的自旋,从而利用自旋玻璃模型的理论框架来分析和理解上下文学习的内在机制。这种方法旨在揭示预训练过程如何影响模型的权重参数,并最终导致上下文学习能力的出现。
技术框架:该研究的技术框架主要包括以下几个步骤:首先,选择一个具有线性注意力的简化Transformer模型。然后,将该Transformer模型映射到一个具有实值自旋的自旋玻璃模型。在这个自旋玻璃模型中,耦合和场被用来解释数据的内在无序性。接着,利用自旋玻璃模型的理论工具,分析权重参数在预训练期间的相互作用。最后,通过理论分析和实验验证,解释为什么仅提供prompt即可预测未见过的函数,而无需进一步训练。
关键创新:该研究的关键创新在于将深度学习模型与统计物理模型相结合,为理解上下文学习提供了一个新的视角。具体来说,将Transformer的线性注意力机制映射到自旋玻璃模型,利用自旋玻璃模型的理论框架来分析和解释上下文学习的内在机制。这种跨学科的方法为理解大型语言模型的涌现能力提供了一种新的思路。
关键设计:该研究的关键设计包括:选择具有线性注意力的Transformer模型,以便于映射到自旋玻璃模型;使用实值自旋的自旋玻璃模型,以便于表示Transformer中的权重参数;利用玻尔兹曼分布来描述权重参数的分布,并分析其在预训练过程中的演化;通过理论分析和实验验证,证明增加任务多样性可以促进上下文学习的出现。
🖼️ 关键图片
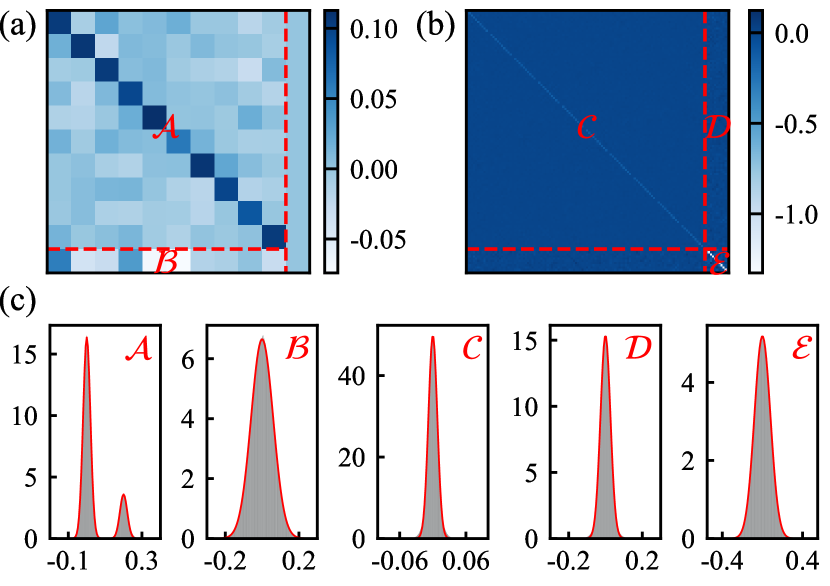
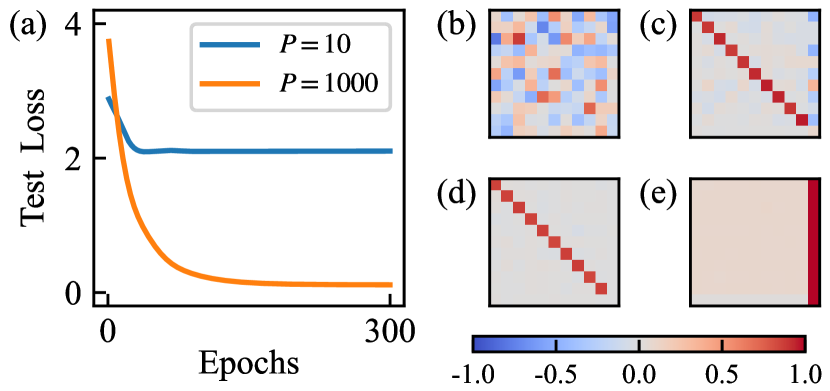
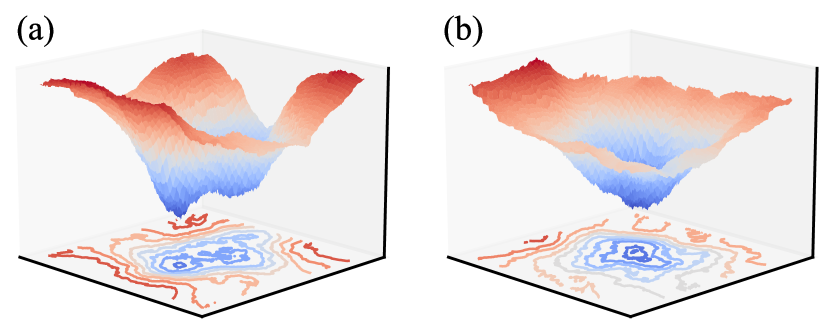
📊 实验亮点
该研究通过理论分析表明,对于单实例学习,增加任务多样性会导致上下文学习的出现,通过允许玻尔兹曼分布收敛到权重参数的唯一正确解。这解释了为什么预训练的Transformer在新的prompt设置中显示出预测能力。该研究为理解大型语言模型的上下文学习能力提供了新的理论视角。
🎯 应用场景
该研究成果有助于深入理解大型语言模型的内在机制,为改进模型设计、提升模型性能提供理论指导。此外,该研究提出的跨学科研究方法,可以将深度学习模型与物理学模型相结合,为解决其他人工智能难题提供新的思路。该研究对于开发更高效、更智能的语言模型具有重要意义。
📄 摘要(原文)
Large language models show a surprising in-context learning ability -- being able to use a prompt to form a prediction for a query, yet without additional training, in stark contrast to old-fashioned supervised learning. Providing a mechanistic interpretation and linking the empirical phenomenon to physics are thus challenging and remain unsolved. We study a simple yet expressive transformer with linear attention and map this structure to a spin glass model with real-valued spins, where the couplings and fields explain the intrinsic disorder in data. The spin glass model explains how the weight parameters interact with each other during pre-training, and further clarifies why an unseen function can be predicted by providing only a prompt yet without further training. Our theory reveals that for single-instance learning, increasing the task diversity leads to the emergence of in-context learning, by allowing the Boltzmann distribution to converge to a unique correct solution of weight parameters. Therefore the pre-trained transformer displays a prediction power in a novel prompt setting. The proposed analytically tractable model thus offers a promising avenue for thinking about how to interpret many intriguing but puzzling properties of large language models.