Re-ENACT: Reinforcement Learning for Emotional Speech Generation using Actor-Critic Strategy
作者: Ravi Shankar, Archana Venkataraman
分类: eess.AS, cs.AI, cs.LG
发布日期: 2024-08-04
备注: 7 pages, 10 figures
💡 一句话要点
提出Re-ENACT,利用Actor-Critic强化学习策略进行情感语音生成。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 情感语音生成 强化学习 Actor-Critic 韵律特征修改 情感转换
📋 核心要点
- 现有情感语音转换方法在韵律特征修改方面存在局限,难以有效控制情感表达。
- 提出Re-ENACT框架,利用Actor-Critic强化学习策略,优化语音韵律特征以增强目标情感。
- 实验结果表明,该方法能够有效改变语音情感,性能与现有情感转换模型相当。
📝 摘要(中文)
本文提出了一种新方法,利用Actor-Critic强化学习策略来修改给定语音信号的韵律特征。该方法使用贝叶斯框架识别重要的连续片段,这些片段将给定话语的片段与人类情感感知联系起来。我们训练一个神经网络来生成伯努利随机变量集合的变分后验;我们的模型对其应用马尔可夫先验以确保连续性。从该分布中抽取的样本用于下游情感预测。此外,我们训练神经网络来预测情感类别的软分配作为目标变量。下一步,我们修改被掩盖片段的韵律特征(音高、强度和节奏),以提高目标情感的分数。我们采用Actor-Critic强化学习来训练韵律修改器,通过离散化修改空间。此外,它为通过WSOLA操作进行节奏操纵的梯度计算问题提供了一个简单的解决方案。实验表明,该框架将给定语音话语的感知情感改变为目标情感。此外,我们表明,我们的统一技术与来自监督和无监督领域的、需要成对训练的最先进的情感转换模型相当。
🔬 方法详解
问题定义:情感语音生成旨在改变语音的情感表达,现有方法通常依赖于监督或无监督学习,需要大量成对数据或复杂的训练策略。此外,如何有效地修改韵律特征(音高、强度、节奏)以达到目标情感表达是一个挑战,尤其是在保证语音自然度和情感强度之间取得平衡。
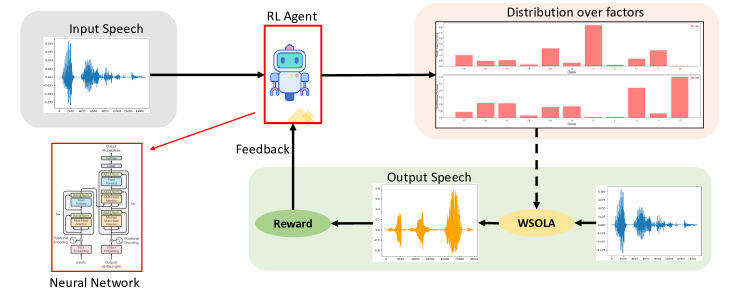
核心思路:本文的核心思路是利用强化学习,将情感语音生成问题建模为一个序列决策过程。通过Actor-Critic框架,Actor负责生成韵律特征的修改动作,Critic负责评估这些动作对情感表达的影响,从而引导Actor学习到最佳的修改策略。这种方法避免了对成对数据的依赖,并能够直接优化情感表达效果。
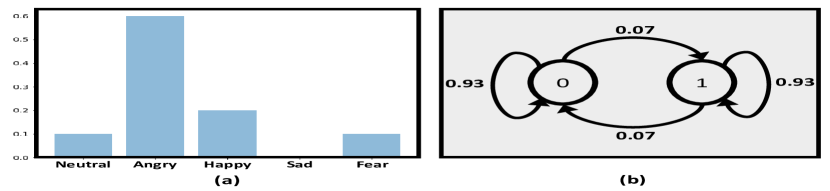
技术框架:Re-ENACT框架包含以下主要模块:1) 情感感知片段识别:使用贝叶斯框架识别与情感相关的语音片段。2) 情感预测:训练神经网络预测情感类别。3) 韵律修改:使用Actor-Critic强化学习训练韵律修改器,修改音高、强度和节奏。整体流程是,首先识别情感相关片段,然后预测当前情感,接着使用强化学习修改韵律特征以增强目标情感。
关键创新:该方法的主要创新在于将强化学习引入情感语音生成领域,并提出了一种基于Actor-Critic的韵律修改策略。与传统的监督或无监督方法相比,该方法能够直接优化情感表达效果,无需成对数据,并且可以灵活地控制情感强度。此外,该方法还提出了一种利用WSOLA操作进行节奏操纵的梯度计算方法。
关键设计:在情感感知片段识别中,使用马尔可夫先验来保证片段的连续性。在Actor-Critic强化学习中,通过离散化修改空间来简化训练过程。Actor网络输出韵律特征的修改动作,Critic网络评估这些动作对情感表达的影响,奖励函数基于目标情感的预测分数。WSOLA操作用于节奏操纵,并提出了一种计算梯度的简单方法。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Re-ENACT框架能够有效地改变语音情感,并达到与最先进的情感转换模型相当的性能。该方法在情感转换任务上与监督和无监督方法相比,无需成对训练数据,简化了训练流程。此外,该方法能够灵活地控制情感强度,并生成自然流畅的语音。
🎯 应用场景
该研究成果可应用于情感语音合成、语音助手、情感聊天机器人等领域。通过控制语音的情感表达,可以提升人机交互的自然性和情感体验。例如,在语音助手中,可以根据用户的情绪状态调整回复的情感,从而提供更个性化的服务。在情感聊天机器人中,可以生成更具表现力的语音,增强用户的沉浸感。
📄 摘要(原文)
In this paper, we propose the first method to modify the prosodic features of a given speech signal using actor-critic reinforcement learning strategy. Our approach uses a Bayesian framework to identify contiguous segments of importance that links segments of the given utterances to perception of emotions in humans. We train a neural network to produce the variational posterior of a collection of Bernoulli random variables; our model applies a Markov prior on it to ensure continuity. A sample from this distribution is used for downstream emotion prediction. Further, we train the neural network to predict a soft assignment over emotion categories as the target variable. In the next step, we modify the prosodic features (pitch, intensity, and rhythm) of the masked segment to increase the score of target emotion. We employ an actor-critic reinforcement learning to train the prosody modifier by discretizing the space of modifications. Further, it provides a simple solution to the problem of gradient computation through WSOLA operation for rhythm manipulation. Our experiments demonstrate that this framework changes the perceived emotion of a given speech utterance to the target. Further, we show that our unified technique is on par with state-of-the-art emotion conversion models from supervised and unsupervised domains that require pairwise training.